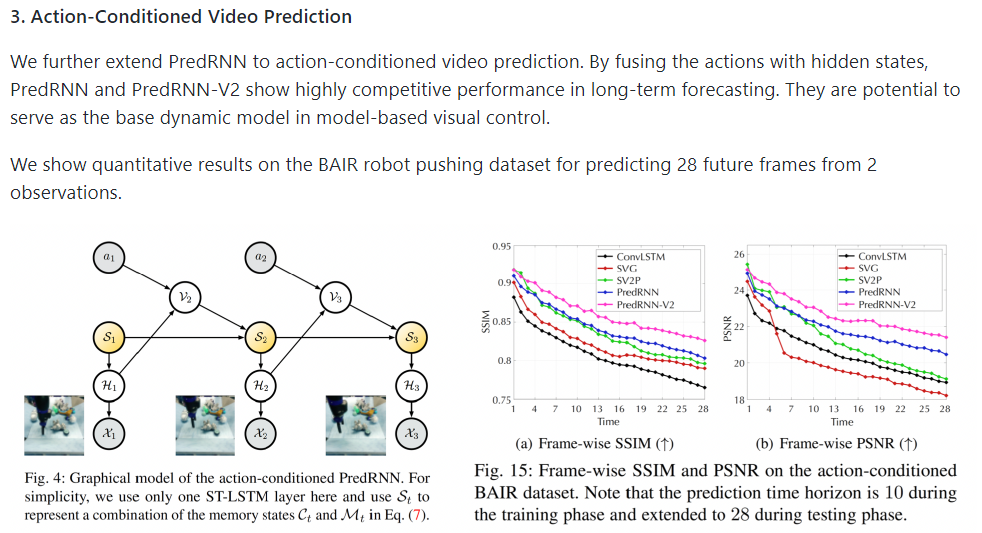
[논문 리뷰] PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning
딥러닝 논문 리뷰

paper v2 : https://arxiv.org/pdf/2103.09504v2.pdf
paper v3 : https://arxiv.org/pdf/2103.09504.pdf
0. 시공간 메모리가 필요한 이유?
기존의 LSTM 구조는 시공간적 변형보다 순차 데이터의 Non-Markovian 장기적 특성을 파악하는 데 초점을 맞췄다. High-level feature는 보존하는 데에 반해 low-level feature는 보존하지 않아 시간적 변화를 포착하기엔 적합하지만 미래 프레임을 생성하는 데는 한계가 있다.
예를 들어 사람이 움직이는 모습을 1초 단위로 캡쳐한 사진이 있다. 사람은 1초 단위로 움직임이 보일 것이지만, 나무, 건물 등 주변 배경은 변화가 거의 없을 것이다. 기존의 LSTM에서는 변화가 없는 '공간'에 대한 데이터를 보존하지 않을 수 있다. 따라서 프레임을 만들어 내는 데에는 한계가 있다.
1. PredRNN(Predictive Recurrent Neural Network)
-
ST-LSTM : LSTM에 시간 메모리 C(LSTM에 기존에 있던 메모리)와 시공간 메모리 M을 추가한 구조
-
ST-LSTM 레이어와 spatiotemporal memory flow 로 만든 모델
-
spatiotemporal memory flow는 모든 노드를 지그재그로 통과함
-
각 timestamp에서 low-level 정보는 새로 설계된 메모리 셀(M)을 통해 입력에서 출력으로 수직으로 전달되고, 최상위 계층에서 spatiotemporal memory flow는 high-level memory state를 다음 timestamp에서 하위 레이어로 가져옴.
-
PredRNN-V2 : memory decoupling과 reverse scheduled sampling을 통해 PredRNN의 training process를 개선한 모델
- memory decoupling : ST-LSTM은 Temporal Memory C와 Spatiotemporal Memory M 두 개를 가지는데, 두 개의 메모리 상태를 자동으로 분리하기 어려움. 따라서 C와 M이 중복 features를 학습할 수 있음. C와 M이 중복 feature를 학습하지 못하게 decoupling loss를 도입.
- reverse scheduled sampling : 인코더를 학습할 때 이전 Ground truth만 가지고 학습하지 않고, 모델로 생성한 프레임에서 실제 프레임으로 점점 바꿔가면서 학습 → 모델이 long-term input context에서 보다 많은 것을 배울 수 있다.
- 논문에서는 video prediction을 predictive learning domain으로 간주. 각 timestamp에서 관찰된 데이터는 RGB 비디오 프레임이며 즉 채널 수는 3개. 또 다른 실험은 precipitation nowcasting. 여기서 관찰된 데이터는 특정 영역의 gray-scale radar echo map.
2. 사전 지식
2.1 Convolutional LSTM
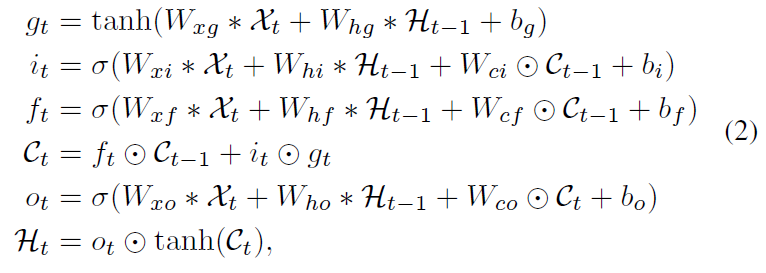
-
: Sigmoid activation function
-
: Convolution operator
-
⊙ : Hadamard product
— Challenge 1 : stacked ConvLSTM 네트워크는 input sequence 이 하단 레이어로 들어오고 output sequence 이 상단 레이어에 생성된다. Hidden state 가 밑에서 위로 전달되면서 representation이 계층별로 인코딩된다. 그러나 memory state 는 다른 레이어의 시각적 특징들과 관계없이 ConvLSTM 레이어 내에서 시간의 흐름에 따라 업데이트된다. 따라서 현재 timestamp의 첫 번째 계층은 이전 timestamp의 최상위 계층의 정보를 알지 못한다. 본 논문은 계층간 메모리 셀을 도입하여 이 문제를 해결한다.
— Challenge 2 : ConvLSTM 레이어에서 output hidden state 는 memory state 와 output gate 에 따라 달라진다. 이는 메모리 셀이 long-term과 short-term을 동시에 처리해야 함을 의미한다. 따라서 복잡한 시공간적 변화에 대해서는 잘 처리할 수 없다.
— Challenge 3 : ConvLSTM은 sequence-to-sequence RNN 아키텍처인데, Encoder와 Forecaster 간의 training 불일치가 발생한다.
3. Method
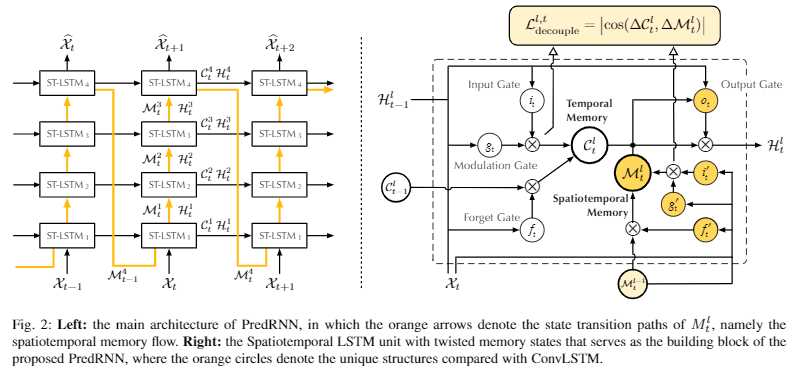
3.1 Spatiotemporal Memory Flow(시공간 메모리 흐름)
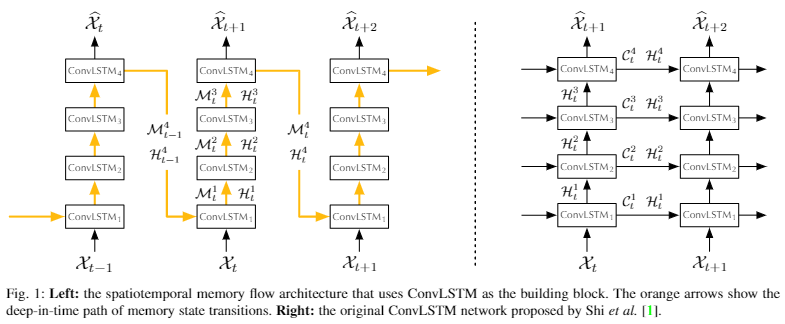
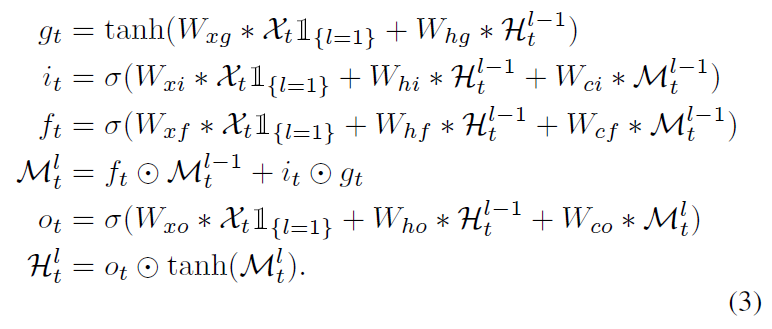
-
논문의 첫 번째 try로, ConvLSTM 계층을 PredRNN의 기본 구성 블록으로 채택한 형태.
-
위 그림에서 오른쪽은 기존의 ConvLSTM 네트워크. memory state 는 개별 recurrent layer 내부에 제약되어 있고 화살표 방향에 따라 업데이트 됨. hidden state 만 최종 prediction에 전달됨. 이 방식은 video classification 같은 supervised learning task에 주로 사용되었음.
-
그러나 input frame과 예상 출력은 같은 공간 영역에 있을 수 있다. 즉, input과 예상 output은 공간 영역에 대해 폐쇄적인, 크게 변화가 없는 데이터 분포를 가지고 시간 영역에서는 서로 연관된 움직임을 가지는 데이터 분포를 보일 수 있다.
-
따라서 different level에서 학습된 memory representation을 잘 활용하여 학습해야 한다. Global motion에 대한 이해와 input sequence의 미세한 변화를 잘 기억할 수 있어야 한다.
-
spatiotemploral memory flow는 왼쪽 그림의 주황색 화살표로 표시함. memory state를 지그재그 방향으로 메모리를 업데이트해서 입력에서 출력으로 knowledge를 더 잘 전달함.
-
개선된 architecture에서 input gate, input modulation gate, forget gate, output gate는 동일한 계층에서 이전 timestamp의 hidden state와 시간 메모리 state에 종속되지 않음. 대신 hidden state 와 이전 계층에서 현재 timestamp에 제공한 spatitemporal memory state 에 의존함.
-
bottom recurrent unit ()은 이전 시간대의 상단 계층에서 상태값을 받음. 왼쪽 그림에서 input-to-state, state-to-state 전환과 관련해 서로 다른 convolution parameters를 가짐.
-
input, forget, output gate 계산할 때, ConvLSTM은 Hadamard product ⊙을 사용하지만 PredRNN에서는 convolution operator *을 사용.
3.2 Spatiotemporal LSTM with Memory Decoupling
-
Spatiotemporal memory state는 먼저 위쪽으로 업데이트 되고 다음 timestamp로 이동한다. 이런 deep-in-time architecture는 vanishing gradient 문제가 발생할 수 있다. short-term과 long-term을 모두 학습하기 위해 C의 기존 메모리 흐름과 M의 새로운 시공간 메모리 흐름을 결합하는 메커니즘을 도입
-
그림 2는 논문에서 소개하는 최종 PredRNN 모델로, ConvLSTM 대신 ST-LSTM을 채택한다.
-
ST-LSTM의 공식은 아래와 같다.
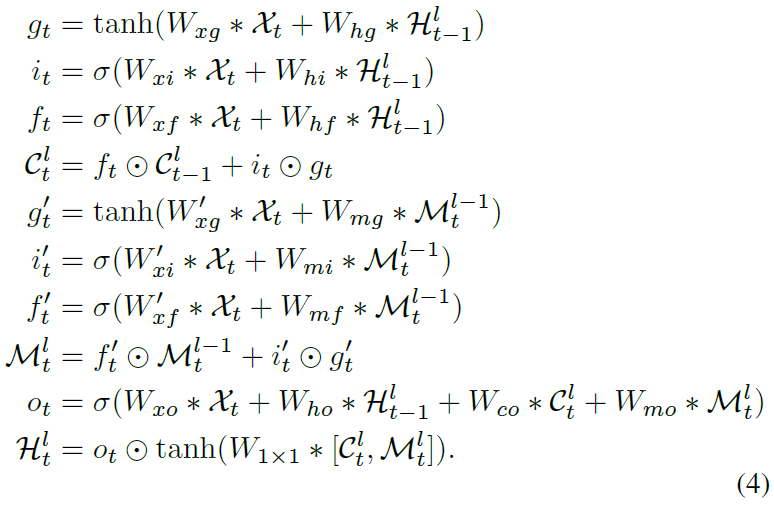
-
는 각 ST-LSTM 계층 내에서 의 이전 노드에서 현재 시점으로 전송되는 시간 메모리.
-
는 시공간 메모리. 동일한 시간대의 하위 ST-LSTM 레이어에서 현재 노드로 수직 전달됨. 인 ST-LSTM 은 을 에 할당함.
-
와 은 서로 다른 신호에 의해 제어되기 때문에 은 와 다른 input gate , forget gate , input modulation gate 를 가짐.
-
각 노드의 hidden states 는 수평으로 전달되는 와 지그재그로 전달되는 의 조합이다. 와 를 조합한 다음 차원수를 감소시키기 위해 1x1 convolution layer를 적용하여 가 memory state와 같은 차원수를 갖게 함.
-
은 short-term, 는 long-term 학습을 용이하게 도와주는 데 이 둘이 중복된 feature를 학습하지 못하게 decoupling loss를 제시했다.
-
Decoupling 공식
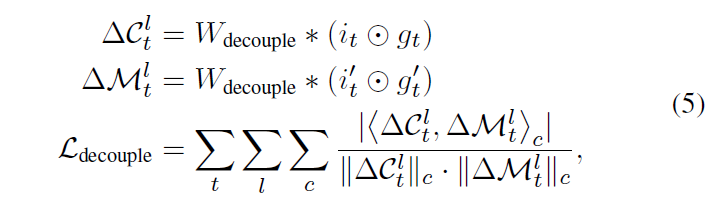
-
은 모든 ST-LSTM 계층에서 공유되는 1x1 convolution.
-
와 는 각각 dot product와 norm이며 채널별로 계산됨
-
와 는 수식 (4)에서 파생된다.
-
new parameters는 training할 때만 사용되고 예측할 땐 전체 모델에서 제거되므로 모델 크기는 증가하지 않는다.(new parameters→ 아마 decoupling loss를 얘기하는 것)
-
cosine similarity로 decoupling loss를 정의하여 이 0이 되도록 유도한다. cosine similarity는 두 대상의 similarity가 높을 때 1이 되므로, 이 0이 되도록 유도한다는 것은 두 대상의 similarity를 낮춘다는 의미이다. 와 이 중복해서 학습하지 않고 각각 long-term, short-term을 학습할 수 있도록 한다.
-
Ensemble learning처럼 base learner의 다양성을 강화하는 아이디어를 적용하여 recurrent networks의 memory states의 pairs의 거리를 다양화함.
-
최종 PredRNN model은 unsupervised 방식의 end-to-end로 학습됨.
-
PredRNN의 training 목표는 아래 식과 같다. 아래 식의 첫 번째 term은 각 시간대의 네트워크 출력에서 작동하는 frame reconstruction loss, 두 번째 term은 memory decoupling regularization이다 . 는 하이퍼 파라미터.
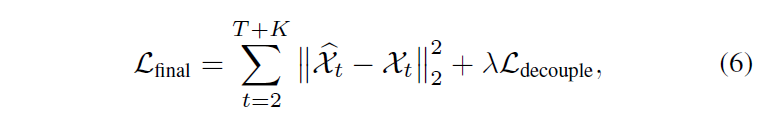
3.3 Training with Reverse Scheduled Sampling
- 인코딩 단계에서 Reverse Scheduled Sampling 도입 → 사용함으로써 이점? 인코더가 에서 오랜 시간동안 시간에 따른 변화를 학습, Encoder와 Forecaster간의 training process의 불일치를 줄여줌
- Encoder-forecaster training discrepancy
- sequence encoding과 forecasting에 대해 로 나타낼 수 있음. 시간적 변화는 로 나타낼 수 있음. 각 timestamp t에 대해 은 다음과 같이 계산함.
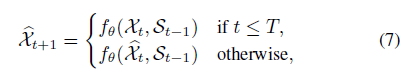
- 즉 t 시간에 들어온 input 의 예측값 은 와 의 조합으로 생성되고, 만약 라면 와 의 조합으로 생성됨.
- encoder()와 forecaster()의 주요 차이점은 output을 도출할 때, 모델 자체에서 오는 예측값 를 쓰느냐, 이전 시점의 true frame 을 쓰느냐이다.
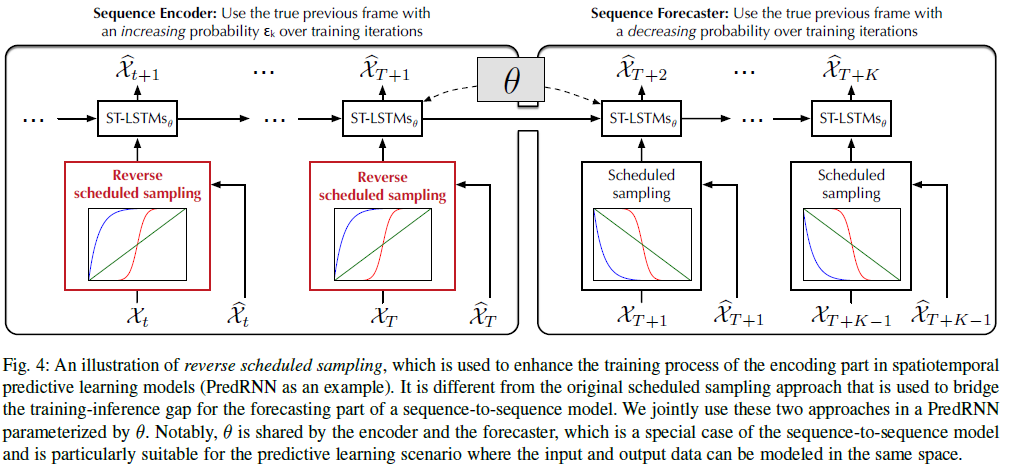
- 위 그림은 Encoder에 reverse scheduled sampling을 적용한 그림이다. PredRNN(v2)은 Reverse scheduled sampling과 scheduled sampling을 함께 사용한다.
- 동일한 파라미터 집합 를 쓰면 Encoder와 forecaster 간의 training 불일치가 발생할 수 있다. 불일치가 발생하면 이 비효율적으로 최적화되고 모델의 학습을 방해한다.
- encoder에서는 보다 실제 frame인 가 더 유용한 정보지만 forecaster에서는 실제 frame이 아닌 예측값을 받기 때문에 이 더 유용하다. 그래서 모델은 forecasting 부분에서 더 어려운 상황에서 training하게 된다. 모델이 pre-train이 잘 된 상태라서 생성된 데이터의 분포가 실제 데이터의 분포에 가깝다면 (7)과 같이 forward propagation하여 train하면 된다. 하지만 그렇지 않으면 Encoder-forecaster 간의 격차로 인해 모델의 최적화가 잘 이루어지지 않는다. → Reverse scheduled sampling을 도입하게 된 계기 인코더 true frame만 받아서 학습하고 forecaster에서는 예측 frame만 받아서 학습하다보면 둘 사이에 격차가 생길 수 밖에 없다!
- sequence encoding과 forecasting에 대해 로 나타낼 수 있음. 시간적 변화는 로 나타낼 수 있음. 각 timestamp t에 대해 은 다음과 같이 계산함.
- Scheduled sampling
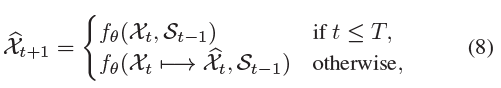
- (8)에서 은 forecaster에 입력되는 프레임이 실제 프레임 부터 예측 프레임 으로 점차 변화했음을 나타낸다.
- 를 사용할지 를 사용할지는 샘플링을 통해 random으로 결정한다. 확률 에 대해 를 사용하고, 확률 에 대해 를 사용할 수 있다.
- 는 training iterations의 index이다. 는 의 함수이며 linear하거나 exponentially(지수적)하게 감소한다. gradient descent 알고리즘에서 learning rate를 점진적으로 감소시키는 것과 같다.
- 이면 forecaster는 encoder처럼 train되고 이면 전체 모델은 추론 단계와 같은 설정으로 train된다.
- 모델이 training 중에 의 분포를 인식할 수 있고, Encoder와 forecaster 사이의 차이를 부분적으로 메울 수 있다.
- 하지만 이 방법은 long-term dynamics 학습에 있어 Encoder의 비효율적인 training을 개선하지 못한다.
- Encoder와 forecaster 간의 격차를 줄이는 다른 방법으로는 Encoder의 train 방식을 수정하는 것이다.→ 그래서 Reverse scheduled sampling 도입!
- Reverse scheduled sampling
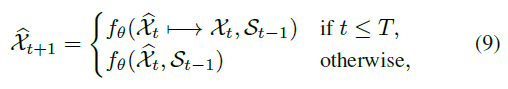
- (9)에서 은 학습 스케줄을 나타낸다. 인코딩 단계에서 실제 프레임 을 샘플링할 확률 또는 를 샘플링할 확률 이 있다.
- 는 에서 시작하여 로 증가하는 함수이다.

- 는 increasing factors이고, 는 시그모이드 함수의 starting point이다. 이 하이퍼 파라미터는 의 증가 곡선에서 결정한다.(아래의 빨간색 곡선)
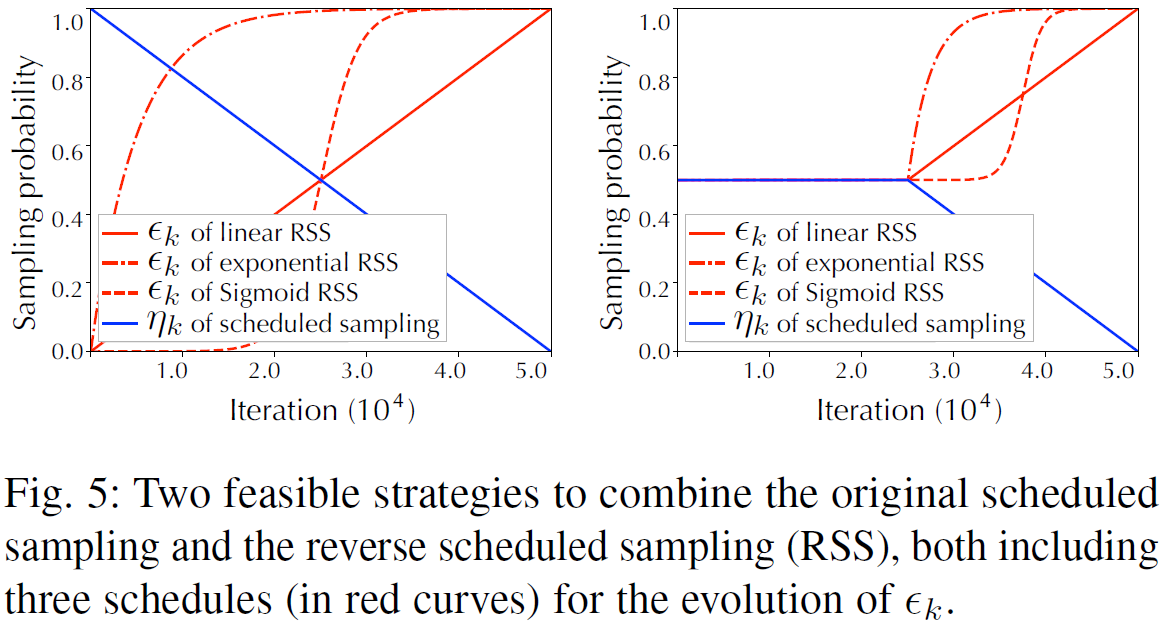
- Encoder는 점진적으로 단순화되는 커리큘럼으로 교육되는데, 이러한 approach를 Reverse Scheduled Sampling이라고 한다.
- 부분적으로 과거 프레임 없이 다단계 미래 프레임을 생성하다가 점점 한 단계 예측으로 변화한다.(점점 쉬워지는 것으로, 즉 단순해진다고 볼 수 있음)
- 모델은 input sequence로부터 long-term non-Markovian dynamics를 추출하고, Encoder의 끝 부분에서 Encoder-forecaster 불일치를 해소하기 위한 솔루션을 제공한다.
- training 초기 단계에서는 sequence-to-sequence 모델의 양쪽 부분은 이전 예측값을 사용할 확률이 높다. 즉, 유사한 환경에서 일관되게 최적화된다.
- 그림5는 Reverse scheduling된 sampling을 original scheduling된 sampling과 통합하는 전략 두 가지를 나타내는 그림이다.
- 두 전략의 가장 큰 차이점은 Encoder와 Forecaster의 sampling 확률의 변동 범위가 training 초기 단계와 비슷한지, 아닌지이다.
- 결론적으로, 두 번째 전략이 더 나은 성능을 보인다. training을 시작할 때 Encoding, forecasting 단계에 유사한 샘플링 확률을 사용하면 Encoder-forecaster 불일치를 줄일 수 있다.
4. 실험 디테일
- Implementation Details
- ADAM optimizer
- 각 training iteration마다 8 sequence로 구성된 mini-batch로 학습
- learning rate
- 80,000 iterations
- 128 channel이 있는 PredRNN에서 4개의 ST-LSTM 레이어 사용
- 각 ST-LSTM 레이어에서 Convolution 커널 사이즈는 5*5
- Precipitation Forecasting from Radar Echoes
- 향후 0~2시간 내에 radar echoes의 움직임 예측하여 강수량 예측
- echoes는 non-rigid shapes이고 복잡한 대기 물리학으로 인해 빠르게 이동하거나 축적되거나 소멸할 수 있음
- Dataset : 중국 광저우에서 6분마다 10,000개의 관측 데이터로 구성. 관찰결과를 픽셀 값에 매핑하여 128*128 gray scale 영상으로 나타낸 다음 sliding window로 sequential radars map을 slice하여 총 9,600개의 sequence를 얻는다. 각 시퀀스는 10개의 input frame과 10개의 output frame을 갖고, 이는 과거 1시간 및 이후 1시간동안의 데이터이다. train에는 7,800개의 시퀀스 사용. 나머지는 모델 평가에 쓴다.
5. Extend Research