12.1 Large-Scale Deep Learning
신경망의 정확도와 복잡도를 개선하는데 있어 핵심적인 요인 중 하나는 신경망의 크기다.
고성능 하드웨어와 소프트웨어 기반구조가 필요하다.
12.1.1
12.1.2
그래픽 카드는 다수의 3차원 정점좌표들에 대해 행렬 곱셈과 나눗셈 연산을 수행함과 동시에, 2차원 화면 좌표로 변환하는 작업도 병렬로 수행.
각 픽셀에 대해 여러 연산을 적용해서 픽셀의 값을 결정하는 연산도 병렬 수행.
cpu와 gpu에 대해 설명해준다
12.1.3
컴퓨터 한 대의 계산 자원으로는 큰 신경망을 실행하기에 부족할 때가 있다.
해결책은, 여러 대의 컴퓨터로 분산하는 것이다.
inference의 분산
각 입력 견본을 각자 다른 컴퓨터로 처리하기 -> 자료 병렬성(data parallelism)
하나의 자료점을 어려 대의 컴퓨타가 처리하기 -> 모델 병렬성(model parallelism)
train
자료 병렬성
SGD(확률적 경사 하강법) 단계에서 미니배치의 크기 키우기 -> 최적화가 선형에 못 미칠 때가 많음.
여러 컴퓨터가 여러 경사 하강 단계들을 병렬로 계산하는게 낫지만, 표준적인 경사 하강법은 순차적인 알고리즘임. 단계 t에서의 기울기는 단계 t-1에서 산출한 매개변수들의 함수이기 때문이다.
해결책 - 비동기 확률적 경사 하강법
비동기(asynchronous) 확률적 경사 하강법은 각 core는 잠금 없이 매개변수들을 읽어서 기울기를 계산 후 갱신한다. 일부 core가 다른 core의 결과를 덮어쓸 수 있음. 따라서 각 경사 하강 단계의 평균 개선량이 감소한다. 그러나 산출 속도가 증가하여 전체적인 학습이 빨라짐.
12.1.4
추론 비용을 줄이는 한 가지 핵심 전력은 모델 압축(model compression)
고비용 모형을 더 작은, 저장 비용과 평가 비용이 낮은 모델로 대체한다.
주로 과대적합을 피하려고 크기를 키운 모델에 적용할 수 있다.
12.1.5
자료 처리 시스템의 속도를 높이는 전략 하나, 하나의 입력을 처리하는데 필요한 계산을 서술하는 계산 그래프에 동적 구조(dynamic struture)가 존재하는 시스템을 구축하는 것
개별 신경망에서 입력에 있는 특정 정보를 계산하는데 알맞는 부분(은닉 단위들의 부분집합)을 동적으로 결정할 수 있다.
이런 구조를 조건부 계산(conditional computation)이라고 부르기도 함.
게이터(gater)라고 부르는 신경망도 동적 구조를 가진 신경망의 예임.
전문가망(expert network)중 하나를 선택해서 현재 입력에 대한 출력을 계산한다.
동적 구조 시스템의 활용에서 주요 문제점들은, 시스템이 서로 다른 입력에 대해 서로 다른 코드 경로로 분기하다 보니 병렬성이 줄어든다.
12.1.6
심층망 전용 하드웨어 구현
12.2 Computer Vision
12.1
12.2 preprecessing 전처리
12.2.1.1 명암비 정규화
여러 컴퓨터 시각 과제들에서 안전하게 제거할 수 잇는 명백한 변동 요인은 이미지의 명암비이다.
이미지 전체 또는 한 영역의 픽셀들의 표준편차를 명암비로 간주함.
전역 명암비 정규화(Global contrast normalization, GCN)는 다수의 이미지들의 명암비 변동을 줄이기 위해, 각 이미지에서 평균 명암비를 뺀 후 이미지 픽셀들의 표준편차가 어떤 축척 상수 s와 같아지도록 적절히 비례한다.
문제점은 명암비가 0인 이미지(모든 픽셀이 같은 세기인 이미지)는 어떤 비례 계수를 사용해도 명암비를 변경할 수 없다.
구면화(sphering)
분산이 같아지도록 주성분들을 재비례하는 것이다.
백화(whitening)와 같은 연산이다.
국소 명암비 정규화(Local Contrast Normalization, LCN)
이미지 전체가 아니라 이미지의 작은 영역들에 대해 명암비를 정규화한다.
각 픽셀에서 인근 픽셀들의 평균을 빼고 인근 픽셀들의 표준편차로 나누는 것은 모든 방법에서 공통임. 구체적인 방법에 따라서는 픽셀을 중심을 한 직사각형 영역의 모든 픽셀의 평균과 표준편차를 그대로 사용하기도 하고, 가우스 가중치들을 이용한 가중 평균과 가중 표준편차를 사용하기도함.
국소표준편차들의 특징 맵들을 계산한 후 각 특징 맵에 대해 성분별 뺄셈과 성분별 나눗셈을 적용하는 식으로 효율적으로 구현할 수 있음.
미분 가능 연산으로, 입력 전처리 연산은 물론 신경망 은닉층의 비선형 함수로도 사용할 수 있다.
12.3 Speech Recognition
음성 인식(speech recognition)
자동 음성 인식(automatic speech recognition ASR)
주어진 음향 정보 순차열 X에 대응되는 가장 그럴듯한 언어 정보 순차열 y를 계산하는 함수 f^ASR를 학습하는 것을 목표로 함.
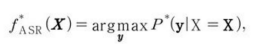
P^는 입력 X를 목표 y와 연관시키는 진(true) 조건부 분포이다.
은닉 마르코프 모델(Hidden Markov Model, HMM)과 가우스 혼합 모델(Gaussian mixture model, GMM)
GMM은 음향 특징들과 음소들의 연관 관계를 모델화했고 HMM은 음소들의 순차열을 모델화했다.
HMM이 음소들과 이산적인 부분음소 상태들의 순차열을 산출, GMM은 각 이산적 기호들을 짧은 길이의 음향 파형 자료로 변환한다.
제한 볼츠만 기계(restricted Boltzmann machine, RBM)
무방향 확률적 모형을 훈련해서 입력 자료를 모델화하는 것에 기반을 둔 것이다.
비지도 사전 훈련(unsupervised pretraining)을 이용해서 하나의 심층 순방향 신경망을 구축하는데, 이때 신경망의 각 층을 각각 하나의 RBM의 훈련을 통해 초기화함.
이 신경망은 고정 크기 입력 구간안의 음향 스펙트럼 표현들을 입력받아서, 그 구간의 중심 프레임에 대한 HMM 상태들의 조건부 확률들을 예측한다.
12.4 Natural Language Processing
12.4.1 N-gram
n개의 토큰들로 이루어진 하나의 순차열
n번째 토큰의, 이전에 관측한 n-1개의 토큰들이 주어졌을때의 조건부 확률을 정의한다.
n=1인 모델을 유니그램(unigram), n=2는 바이그램(bigram), n=3은 트라이그램(trigram)
n-gram 과 n-1 gram 모델을 동시에 훈련하고 조건부 확률을 계산할 때 이미 계산해서 저장해 둔 두 확률을 조회해서 나누기만 하면 된다.
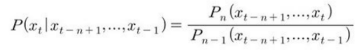
Pn의 추론을 정확하게 재현하려면, Pn-1을 훈련할 때 각 순차열에서 반드시 마지막 요소를 생력해야 한다.
한계는 훈련 집합의 단어 도수로 추정한 Pn이 0이 될 가능성이 크다. Pn-1이 0이면 확률이 정의되지 않아서 산출하지 못한다.
평활화(smoothing)를 사용한다. -> 관측된 튜플들에서 관측되지 않은, 관측된 것들과 비슷한 튜플로 확률질량이 이동함.
12.5 Other Applications
