https://www.deeplearningbook.org/contents/linear_factors.html
Linear Factor Models - 선형 인자 모형
인자(factor) - 관측되지 않는 변수, 잠재 변수(latent variable)
잠재 변수가 있는 가장 단순한 확률 모델에 해당하는 선형 인자 모델을 소개한다.
심층 모델을 확장한 형태 생성 모델(generative model)을 구축하는데 필요한 접근 방식을 보여준다.
선형 인자 모델의 특징은 h(잠재 변수)의 선형 변환에 노이즈를 더함으로 x를 생성하는 확률적 선형 디코더(stochastic linear decoder) 함수를 활용한다.
결합분포를 가진 설명 인자(explanatory factor)들을 발견할 수 있다. -> 선형 디코더를 사용하기에 다루기가 쉽다.
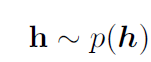
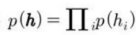
p(h)는 인수곱 분포(factorial distribution)으로 표본을 추출하기 쉽다. 주어진 인자를 기초해서 실수값 관측 가능 변수를 추출한다.
h의 선형변화에 bias와 noise를 더함으로써 x를 생성하며 noise는 차원들에 대해 독립이다.(Gaussian and diagonal)
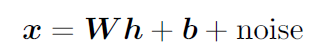
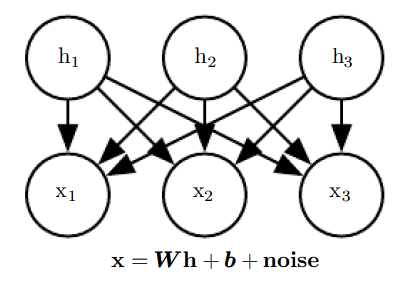
선형 인자 모델의 구조
13.1 Probabilistic PCA and Factor Analysis
PCA(주성분 분석)
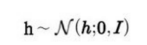
가우스 분포
인자분석에서 관측변수(observed variable) xi들이 h가 주어졌을 때 조건부 독립(conditionally independent)이라고 가정한다.
인자분석에서는 noise를 공분산 행렬이 
인 대각 공분산 가우스 분포에서 얻는다.
σ^2 = [σ^2 1, σ^2 2, ....,σ^2 n]^T는 변수별 분산들을 담은 벡터이다.
서로 다른 관측변수 xi들 사이의 의존성을 포착하는 것이다.
확률론의 틀에서 PCA를 하려면 조건분 분산들을 모두 같게 만들어야 한다. σ^2은 하나의 스칼라이다.
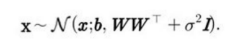
위와같이 공분산이 바뀐다.
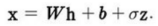
이와같이 나타낼 수 도 있다.
반복적인 EM 알고리즘을 사용해서 W와 σ^2을 추정할 수 있다.
대부분의 변동을 어떤 작은 잔차(residual) 재구축 오차(reconstruction error)까지는 잠재변수 h로 찾을 수 있다.
모든 주성분들은 직교한다.
13.2 Independent Component Analysis (ICA)
ICA(독립 성분 분석)은 가장 오래된 표현 학습 알고리즘
선형 인자들을 모형화하기 위한 접근 방식의 하나인 독립 성분 분석은 관측된 신호를 여러 바탕(underlying) 신호들로 분리하고, 그 바탕 신호들을 비례하고 더해서 관츤 자료를 만든다.
신호들은 상관관계가 없으며 서로 완전히 독립이라고 가정한다.
ICA는 매개변수적(fully parametirc) 생성 모델을 훈련한다. 바탕 인자들에 관란 사전 분포 p(h)를 미리 지정해야한다.
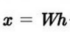
주어진 사전분포에 기초해서 위와 같이 생성한다.
변수들을 비선형적으로 변화해서 p(x)를 구할 수 있다. 그 후 최대가능도를 이용해서 학습시킨다.
IC의 많은 변형이 가능하다. 일부는 결정론적 디코더를 사용하는 대신 x를 생성해서 noise를 추가한다. 대부분은 최대가능도 기준을 사용하지 않고 h = W^−1 x의 성분들이 서로 독립시키는 것을 목표로 한다.
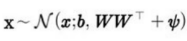
W의 행렬식을 취해야하는데, 행렬식 계산은 수치적으로 불안정해질 수 있다. ICA의 일부 변형은 W를 직교행렬함으로써 문제 연산을 피한다.
ICA의 모든 변형에서 공통점은, p(h)가 반드시 비 가우스 분포여야한다. 가우스 분포라면 W의 식별이 불가능해진다. -> 서로 다른 여러 W 값들이 p(x)에 관한 동일한 분포에 대응한다.
사용자가 분포를 지정해야 하는 최대가능도 접근 방식에서는
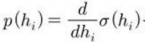
를 사용한다
비 가우스 분포는 가우스 분포에 비해 0 부근에서 peak이 더 높다.
대부분의 ICA 구현들이 희소 표현의 학습을 목적으로 하기 때문이다.
13.3 Slow Feature Analysis
SFA는 시간 신호들에 있는 정보를 이용해서 불변 특징들을 학습하는 선형 인자 모델
느린 특징 분석은 느림 원리라고 부르는 일반 원리에 기초한다.
장면의 중요한 특징들은 그 장면의 서술을 구성하는 개별 측도들에 비해 느리게 변한다는 것이다.
느림 원리를 모형에 적용하는 방법은, 비용함수에 다음과 같은 형태의 항을 하나 추가하면 된다.
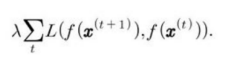
λ는 느림 정칙화 항의 강도를 결정하는 초매개변수, t는 시간순 견본 순차열의 특정 견본을 지칭하는 시간 색인, f는 정칙화할 특징 추출기(feature extractor), L은 f(x^(t),f(x^(t+1))의 거리를 측정하는 손실함수이다. L로는 흔히 평귭제곱오차를 사용한다.
선형 특징 추출기에 적용하면 효율성이 생긴다. 그래서 닫힌 형태로 훈련될 수 있다.
ICA의 일부 변형들처럼 SFA가 그 자체로 생성 모델은 아니다.
SFA가 입력 공간에서 특징 공간으로의 선형 사상을 정의하지만 특징 공간에 관한 사전분포를 정의하지 않아 입력 공간에 대해 분포 p(x)를 강제하지 않음으로 생성 모델이라고 하기 힘들다.
SFA 알고리즘은 f (x;θ)를 하나의 선형 변환으로 정의하여 최적화 문제를 푼다.
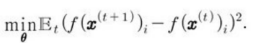
단, 조건을 충족해야 한다.
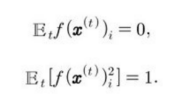
유일한 해를 가지려면 학습된 특징의 평균이 0이어야 한다는 조건이 필요하다. 그렇지 않으면 모든 특징 값에 하나의 상수를 더해서 또 다른 해를 얻을 수 있다.
특징들은 분산이 1이어야 한다는 조건은 모든 특징이 0으로 축약되는 문제를 방지하기 위한 것이다.
PCA처럼 SFA의 특정에는 순서가 있다.
1. 가장 느리게 변하는 특징
2. 여러 개의 특징을 학습하려면 조건을 추가해야한다.
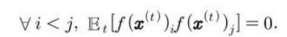
즉, 학습된 특징들은 반드시 서로 선형 무상관이어야 한다.
이런 조건이 없으면 모든 학습된 특징이 가장 느린 신호 하나만 포착하는 결과가 빚어질 수 있다
SFA는 x에 비선형 기저 확장(basis expansion)을 적용한 후 SFA를 적용해서 비선형 특징들을 학습하는 형태로 쓰인다.
x를 이차 기저(모든 i와 j에 대한 성분 xixj들로 이루어진 벡터)로 확장한다.
-> 적절히 조합해서 심층 비선형 느린 특징 추출기를 학습할 수 있다.
장점은 배울 특징들을 예측하는 것이 이론적으로 가능, 심지어 심층 비선형 환경에서도 가능하다.
바탕 인자들의 실제 변화 방식에 관한 지식이 있다면, 인자들을 표현하는 최적의 함수를 해석적으로 푸는 것이 가능하다.
단점은 다른 학습 알고리즘들은 비용함수가 구체적인 특정 픽셀 값에 크게 의존하기 때문에 모델이 어떤 특징을 배울지 예측하기가 어렵다.
13.4 Sparse Coding
비지도 특징 학습과 특징 추출 메커니즘으로서 자세히 연구된 선형 인자 모델
엄밀하게 말하면 모델에서 h의 값을 추론하는 과정에만 해당함.
다른 선형 인자 모델들처럼 희소 부호화 모형은 하나의 선형 디코더에 x의 재구축을 위한 noise를 더한 것이다. -> 가우스 noise를 사용하는 가정인데, β는 등장 정밀도(isotropic precision)이다.
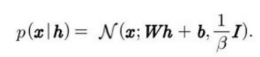
분포 p(h)로는 0 부근에서 봉우리가 날카로운 분포를 선택한다. 인수분해된(factorized) 라플라스 분포나 코시(Cauchy) 분포, 인수분해된 스튜던트(Student) t 분포 등이 있다.
라플라스 사전분포
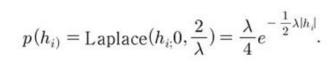
스튜던트 t 사전분포
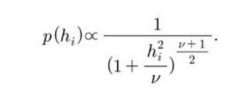
희소 부호화를 최대가능도로 훈련하는 것은 처리 불가능한 문제다. 대신, 자료의 부호화와 디코더의 훈련을 번갈아 한다면 주어진 부호화에 대해 자료를 잘 재구축할 수 있다.
PCA 모델은 가중치 행렬의 곱셈으로만 이루어진 매개변수적 인코더(parametric encoder) 함수를 이용해서 h를 예측한다. 그러나 희소 부호화에서는 매개변수적 인코더를 사용하지 않는다.
희소 부호화에 쓰이는 인코더는 일종의 최적화 알고리즘으로, 가능성이 가장 큰 하나의 부호 값을 구하는 최적화 문제를 푸는 역할을 한다.
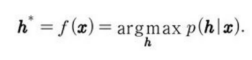
(a)
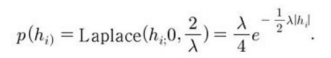
(b)
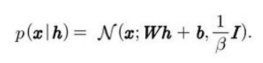
a와 b 식을 결합하면 다음 그림과 같은 최적화 문제가 나온다.
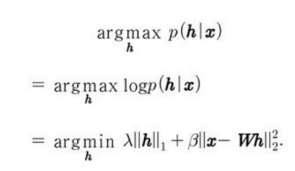
h에 의존하지 않으면 양의 비례 인수들로 나누어지는 항들은 생략되었다.
h에 가해진 L^1 norm 조건으로 희소한 h^*를 산출한다.
모델을 훈련하기 위해서는 h에 대한 최소화와 W에 대한 최소화를 번갈아 수행해야 한다.
이 경우 β를 하나의 초매개변수로 취급한다.
보통 매개변수를 1로 두는데, 최적화 문제에서 매개변수의 역할이 λ의 역할과 겹쳐 둘 다 초매개변수로 둘 필요가 없기 때문이다.
아까 말했던 h에 의존하지 않는 항들은 β에는 의존한다. β를 학습하려면 생략된 항들도 포함되어야하는데 그렇지 않으면 β가 0으로 축약된다.
희소 부호화에 대한 접근 방식 중에서 p(h), p(x|h)를 명시적으로 구축하지 않는 것들도 있다.
추론 절차를 이용해서 추출했을 때 활성화 값이 0이 되는 경우가 많은 특징들의 사전(dictionary)을 학습하는 것이 주된 목표일 때도 많다.
h를 라플라스 사전분포에서 추출한다면, h의 한 성분이 실제로 0이 되는 사건의 확률은 0이다.
희소 부호화 접근 방식을 비매개변수적 인코더와 조합하면 재구축 오차와 로그 사전분포의 조합을 다른 매개변수적 인코더보다 잘 최소화한다. 그리고 인코더에 일반화 오차가 없다.
매개변수적 인코더는 일반화가 잘 되는 방식으로 x를 h로 사상하는 방법을 배운다.
훈련 데이터와 유사성이 없는 비정상적인 x의 경우에는 적절한 h를 찾지못할 수도 있다.
볼록함수에 해당하는 대부분의 희소 부호화 모델 공식화들에서는 최적화 절차가 항상 최적의 부호를 찾아낸다.(복제된 가중치 벡터들이 발생하는 퇴화 경우를 제외할 때)
유사성이 낮은 데이터는 희소성과 재구축 비용이 높아지지만, 인코더 가중치들의 일반화 오차지 인코더의 알반화 오차가 아니다.
희소 부호화의 최적화 기반 부호화 과정에 일반화 오차가 없음으로 부호 예측을 위한 매개변수적 함수로 사용할 때보다 분류기를 위한 특징 추출기로 사용할 때 일반화가 더 잘된다.
선형 S자 오토인코더(linear-sigmoid autoencoder)의 특징들보다 잘 일반화된다.
비매개변수적 인코더의 단점은 x가 주어졌을 때 h를 계싼하는데 시간이 더 많이 걸린다.
반복적 알고리즘을 돌려야 하기 때문이다.
반면, 매개변수적 오토인코더는 고정된 개수의 층들만 사용한다.(하나의 층을 사용할 때가 많다)
단점은 비매개변수적 인코더에 대해 역전파를 수행하기에 간단하지 않다. 그래서 비지도 학습 판정기준을 이용해서 희소 부호화 모델을 미리 훈련한 후 지도학습 판정기준을 이용해서 모델을 세밀하게 조정하는 기법을 적용하기 어렵다.
미분들을 근사할 수 있도록 수정한 희소 부호화 변형들도 있지만, 별로 안쓴다.
종종 다른 선형 인자 모델처럼 질 나쁜 표본들을 산출한다.
모델이 개별 특징을 잘 배운다고해도, 은닉 부호에 대한 인수곱 사전분포 때문에 모델이 생성한 표본에 모든 특징 중 일부 특징들이 무작위로 포함되기 때문이다.
이런 문제점은 가장 깊은 부호층에 비인수곱(nonfactorial) 분포를 강제할 수 있는 더 깇은 모델을 개발하는 동기가 되었으며, 얕은 모델들은 좀 더 정교하게 만드는 동기가 되었다.
13.5 Manifold Interpretation of PCA
PCA와 인자분석을 비롯한 선형 인자 모델이 하는 일을, 하나의 다양체(manifold)를 학습하는 것이라고 해석할 수 있음.
확률적 PCA는 확률이 높은 점들로 이루어진 얇은 팬케이크 모양의 영역을 정의한다.
영역은 곧 일부 축들을 따라 아주 좁게 펼쳐진 가우스 분포에 해당한다.
두꼐(수직축)는 얇지만 넓게(수평축) 퍼져 있는 팬케이크.
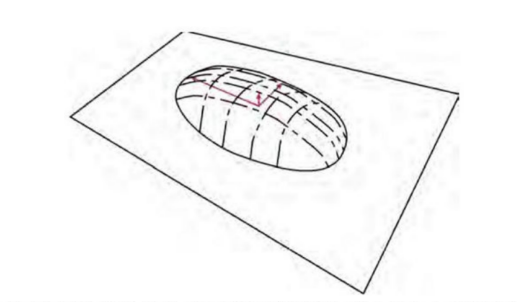
PCA는 고차원 공간에서 팬케이크를 하나의 선형 다양체에 맞게 방향을 정렬하는 것이라 할 수 있다.
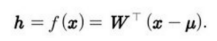
인코더는 위와 같이 정의된다.
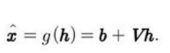
h의 저차원 표현을 계산한다. 오토인코더의 관점에서, 디코더는 위와 같인 x를 재구축한다.
재구축 오차를 최소화하는 선형 인코더와 디코더를 선택
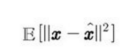
하는 것은 V = W, μ = b = E[x]로 두는 것에 해당하며, W의 열들은 하나의 정규직교 기저를 형성한다. 그 기저는 공분산행렬의 주 고유벡터들과 동인한 부분공간을 차지한다.
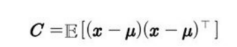
PCA의 경우 W의 열들은 고유벡터들을 해당 고윳값의 크기순으로 정렬한 것이다. (고윳값은 모두 음이 아닌 실수)
또한, C의 고윳값 λi가 고유벡터 v^(i) 방향으로의 x의 분산에 해당하는 점도 증명할 수 있다.
x ∈ R^D이고 d < Dd에 대해 h ∈ R^d일 때, 최적의 재구축 오차는
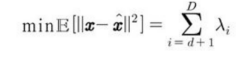
이다.(μ, b, V, W를 앞에서처럼 선택한 경우)
공분산의 계수(rank)가 d이면 λd+1에서 λD까지의 고윳값들은 0이고 재구축 오차는 0이다.
앞의 해를 재구축 오차를 최소화하는 것이 아니라 직교 W하에서 h의 성분들의 분산들을 최대화해서 구할 수 있다.
생성모델(generative model)
주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다. 가장 중요한 것은 학습 데이터의 분포를 학습하는 것이 가장 중요하다. 학습 데이터의 분포와의 차이가 적을수록 실제 데이터와 비슷한 데이터를 생성할 수 있다. 디코더(decoder)
해석기라는 의미로 컴퓨터에게 어떠한 명령을 처리하는데 사용됨.
명령어에 대한 구분을 위해 사용되는 것이 디코더
n개의 입력 변수에 대해 n개의 변수로 구성된 2^n개의 최소항을 생성함.공분산 행렬(Covariance matrix)
공분산이란 둘 이상의 변량(variance)이 연관성을 가지며 분포하는 모양을 전체적으로 나타낸 분산이다.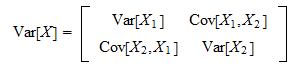
(Var[X1])은 x들이 평균을 중심으로 얼마나 흩어져 있는지를 나타내고,X1와 X2의 공분산(Cov[X1,X2])은 X1,X2의 흩어진 정도가 얼마나 서로 상관관계를 가지고 흩어졌는지를 나타낸다.
이때 Cov[X1,X2]와 Cov[X2,X1]는 동일하기 때문에 대각선 성분을 중심으로 대칭이 되게 된다.
각 요소들의 퍼져있음이 얼마나 유사하냐(요소의 변동이 얼마나 닮았냐), 요소들간의 내적을 통해 요소의 변동이 얼마나 닮았는지 알 수 있다.
데이터를 어떻게 linear transform하고 있는가, 행령은 linear transform을 통해 다른 벡터 공간으로 mapping해주는 기능을 가진다.
공분산 행렬의 초기 상태(데이터가 서로 관련이 없는 상태)에서 서로의 연관선에 대한 정보가 있는 공분산 행렬을 통해 각 데이터를 분산시켜 준다고 볼 수 있다.