
Mallo-Lab 구현을 하면서 공부한 내용, 마주친 에러, 결과물에 대한 분석 등을 두서없이 정리해둔 글
Virtual Memory
Types of Memory Area
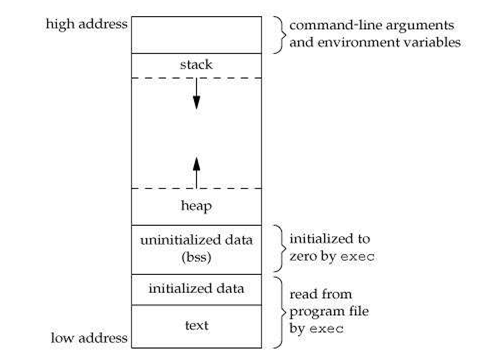
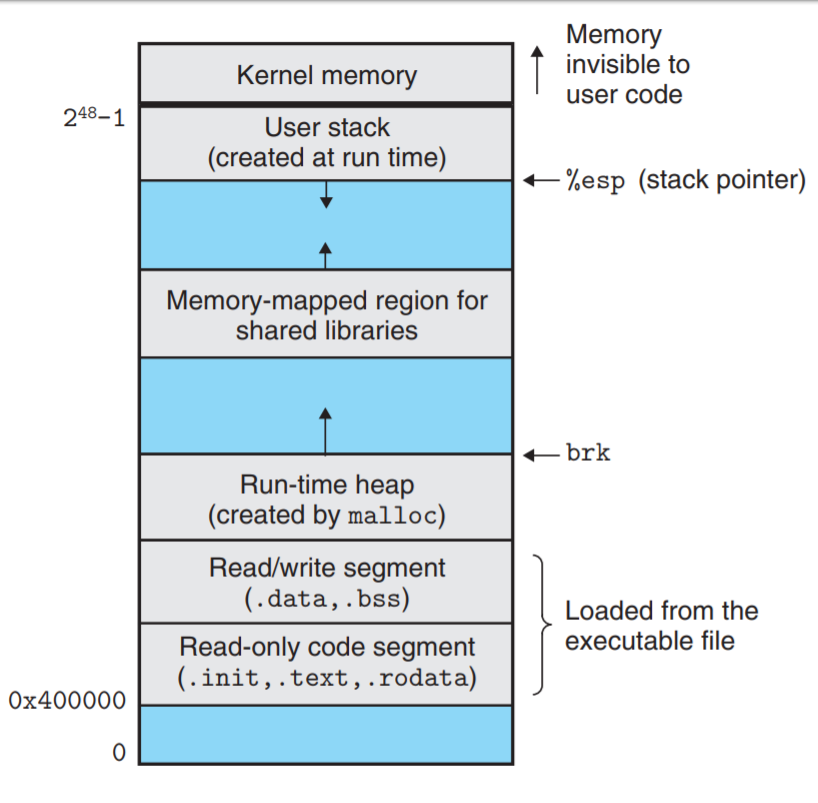
Three types of memory areas used to store data and instructions during program execution: the stack, the heap, and the code/text segment.
-
Stack: The stack is a region of memory used for storing local variables and function call frames. It is a Last-In-First-Out (LIFO) data structure, which means that the last item added to the stack is the first one to be removed. When a function is called, its local variables and other information related to the function are pushed onto the stack. When the function returns, this information is popped off the stack, and the stack pointer is reset to its previous value.
-
Heap: The heap is a region of memory used for dynamic memory allocation, where memory can be allocated and deallocated in any order. The heap is typically used for storing objects whose sizes cannot be determined at compile time or whose lifetimes are not known in advance. The heap is managed by the operating system's memory manager, which tracks allocated memory and deallocates it when it is no longer needed.
-
Code/Text Segment: The code or text segment is a region of memory used to store the program's executable instructions. It contains the program's machine code, which is the compiled version of the program's source code. The code segment is typically read-only and executable, meaning that it cannot be modified by the program itself at runtime. The code segment is mapped into memory at the program's start-up and remains constant throughout the program's execution.
Virtual Memory and Memory Areas
The three memory areas (stack, heap, and code segment) are all allocated in virtual memory. The stack and heap are dynamically allocated by the program at runtime, and their size can change as the program runs. The code segment is usually a fixed size and is mapped into virtual memory at program startup.
When a program accesses memory in the stack, heap, or code segment, the virtual memory manager translates the virtual address used by the program into a physical address in RAM. If the page containing the requested memory is not currently in physical memory, the virtual memory manager swaps it in from disk. This allows the program to access more memory than is physically available and ensures that programs can run even if physical memory is full.
In summary, the stack, heap, and code segment are all allocated in virtual memory, and the virtual memory manager maps virtual addresses to physical addresses in RAM or on disk as needed to ensure that programs have access to the memory they require.
Memory Segments
In computer programming and operating systems, there are several segments of memory that are used to store different types of data and code. Here are the differences and relationships between the commonly used segments:
- Data segment: This segment contains static data and global variables that are initialized by the program at runtime. This segment grows upward in memory and is usually located after the code segment.
- Heap segment: This segment contains dynamically allocated memory that is used by the program during runtime. This segment grows upward in memory and is usually located after the data segment.
- Stack segment: This segment contains the runtime stack that is used to store local variables and function call data. This segment grows downward in memory and is located at the top of the address space.
- Code segment or Text segment: This segment contains the executable code of the program. It is a read-only segment that grows downward in memory and is usually located at the bottom of the address space.
The data, heap, and stack segments are part of the process's virtual memory space, while the code segment is loaded from the executable file into memory during program initialization. The text segment and code segment are often used interchangeably, as the text segment typically refers to the read-only portion of the code segment.
In summary, the data segment contains static data, the heap segment contains dynamically allocated memory, the stack segment contains the runtime stack, and the code/text segment contains the executable code of the program.
Data Segment (+ Heap Segment)
In computer memory management, the data segment is a portion of a program's memory space that contains global and static variables, as well as dynamically allocated memory (heap) and the program's initialized data.
The data segment is typically located in the lower memory address space of the program and is separated from the program's code (text segment) and the runtime stack (stack segment).
Global and static variables are stored in the data segment and have a fixed memory location throughout the execution of the program. The initialized data, such as global arrays and strings, are also stored in the data segment and are initialized to their predefined values before the program starts executing.
The dynamically allocated memory, also known as the heap, is also located in the data segment. It is used to store data that is allocated at runtime using functions such as malloc() and calloc() in C/C++ or new in C++. The size of the heap can grow or shrink dynamically as the program requests or releases memory.
System Call (시스템 호출, syscall)
운영체제는 커널모드와 사용자 모드로 나뉘어 구동되는데, 운영체제에서 응용 프로그램이 구동되는데 있어 파일 읽기, 쓰기, 입력, 출력 스레드 생성 등 많은 부분이 커널 모드를 사용한다. 사용자 모드의 프로그램이 커널 영역의 기능을 사용하기 위해, 즉 프로세스가 하드웨어에 접근해 필요한 기능을 사용하기 위해, 사용자 모드가 커널에 요청하여 커널 모드에서 작업을 처리하고 그 결과를 사용자 모드의 프로그램에게 전달하는 것이 시스템 콜이다. 시스템콜은 여러 종류의 기능으로 나누어져 있으며, 각 시스템콜에는 번호가 할당되고 시스템콜 인터페이스는 이러한 번호에 따라 인덱스되는 테이블을 유지한다.
A system call is a mechanism used by computer programs to request services from the operating system's kernel. It is a way for a user-level program to interact with the underlying system such as managing files, memory, and network connections, other hardware-related services or integral kernel services such as process scheduling and so on.
System calls provide an essential interface between a process and the operating system. When a program needs to perform a privileged operation, such as reading or writing to a file or allocating memory, it must use a system call to request the operating system to perform the operation on its behalf.
Examples of system calls include open() to open a file, read() to read from a file, write() to write to a file, fork() to create a new process, exec() to replace the current process with a new one, and exit() to terminate a process.
시스템 호출의 세 가지 기능
- 사용자 모드에 있는 응용 프로그램이 커널의 기능을 사용할 수 있도록 한다.
- 시스템 호출을 하면 사용자 모드에서 커널 모드로 바뀐다.
- 커널에서 시스템 호출을 처리하면 커널 모드에서 사용자 모드로 돌아가 작업을 계속한다.
시스템 호출의 유형
- 프로세스 제어(process control)
- 파일 조작(file manipulation)
- 장치 관리(device management)
- 정보 유지(information maintenance)
- 통신(communication)
- 보안(Protection) - get/set file permissions
참고 : 운영체제 04 : 시스템 콜 (시스템 호출, System Call), 시스템 호출
Library Call (라이브러리 콜)
라이브러리 콜은 시스템 콜을 한번 더 감싼거
시스템콜을 커널에 직접 요청하는건데 위험하니까
라이브러리는 한번 더 감쌈으로서 에러 등의 위험성을 줄여준 것
시스템콜이 더 빠를 것 같지만
라이브러리 콜은 콜이 잦으면 한번에 모아서 커널에 보내기 때문에 오히려 더 빠르기 때문에
상황에 맞춰서 두가지를 적재적소에 사용해야함
sbrk/mmap for Dynamic Memory Allocation
brk & sbrk
brk and sbrk are basic memory management system calls used in Unix and Unix-like operating systems to control the amount of memory allocated to the data segment of the process.
The brk and sbrk calls dynamically change the amount of space allocated for the data segment of the calling process. The change is made by resetting the program break of the process, which determines the maximum space that can be allocated. The program break is the address of the first location beyond the current end of the data region.
sbrk is used to adjust the program break value by adding a possibly negative size, while brk is used to set the break value to the value of a pointer.
brk와 sbrk는 동적으로 메모리를 관리하기 위한 시스템 콜 함수이다. brk 함수를 통해 각각의 프로세스가 사용 가능한 메로리의 최대 지점을 설정함으로서 각 프로세스가 차지하는 메모리 공간을 한정시킨다. 그리고 sbrk 함수를 통해서 해당 프로세스에 할당된 메모리의 양을 동적으로 늘리고 줄일 수 있다.
mmap
MMAP is a UNIX system call that maps files into memory. It’s a method used for memory-mapped file I/O. It brings in the optimization of lazy loading or demand paging such that the I/O or reading file doesn’t happen when the memory allocation is done, but when the memory is accessed. After the memory is no longer needed it can be cleared with munmap call.
- mmap is used to map a region of virtual memory into a program's address space.
- The function takes several arguments, including the starting address of the memory region to map, the size of the region, the access permissions for the region, and flags that control the behavior of the mapping.
- mmap returns a pointer to the start of the mapped memory region, or -1 if an error occurs.
- mmap can be used to allocate memory dynamically, as well as to map files into memory for efficient file I/O operations.
- mmap is a more flexible and powerful memory management function than sbrk(), but it also requires more careful management to avoid issues such as memory leaks and other memory-related errors.
Why use sbrk over mmap in 'Malloc-Lab'
In general, sbrk() is used for allocating small amounts of memory on the heap, while mmap() is used for larger allocations or for mapping files into memory. The reason for this is that sbrk() operates on the existing heap memory space and modifies the program's data segment, while mmap() allocates memory in a separate address space that is managed by the operating system.
One reason you might have been asked to use sbrk() to implement a malloc() function is that sbrk() is a lower-level system call than mmap(). As such, implementing malloc() using sbrk() provides a more fundamental understanding of how memory allocation works in a program.
Another reason to use sbrk() instead of mmap() is that sbrk() is more efficient for small allocations. Since sbrk() operates on the existing heap memory space, it can allocate memory more quickly than mmap(), which requires the operating system to allocate and manage a separate memory space.
Dynamic Memory Allocation
Explicit & Implicit Memory Allocation
- Explicit allocator : allocate and free with code
- Implicit allocator : system takes care of freeing the memory (garbage collection, Java, etc.)
==> Malloc-Lab에서 C언어를 통해 구현하는건 explicit memory allocator
Allocator
Allocator has a lot of constraints compared to applications
- allocator can't move around blocks by it's own will because it's up to the application to manage the memory it is using
- allocator has to deal with the tradeoff with space and speed
Goal of allocator : maximize throughput and peak memory utilzation
- throughput : Number of completed requests per unit time
- Peak memory utilization(Uk) : sum of all payloads divided by current heap size
- Uk = max(Pk) / Hk <= 1
- payload(Pk) : size of block app requests to malloc
- assuming that heap(Hk) only grows (in real it also shrinks)
- max of Pk since 블록이 할당되고 free 되길를 반복하니까 가장 할당된게 많았던 순간을 기록/가지고 계산
- at best case peak memory utilization would be 1 since all heap is allocated with payload without any fragmentation
Memory Fragmentation (메모리 단편화)
- Internal Fragmentation
- payload is smaller than the block size
- due to padding for alignment purposes, policy decicions(having the minimum size of block allocation)
- previous requests를 보면 현재의 정도를 알 수 있음
- External Fragmentation
- 힙에는 충분한 메모리가 있는데, 크기가 충분한 블록이 없을 때 발생
- internal과 달리 미래에 들어오는 요청에 따라 발생할 수 있기 때문에 미리 판단하기 어려움
Memory fragmentation is a phenomenon that occurs when free memory in a computer's memory (RAM) becomes divided into smaller chunks that are too small to satisfy the allocation requests of larger memory blocks. This can occur over time as memory is repeatedly allocated and deallocated, leaving small gaps of unused memory scattered throughout the memory space.
When the available memory space becomes highly fragmented, the operating system may no longer be able to allocate a large enough block of contiguous memory to satisfy the memory allocation request, even though the total amount of free memory is sufficient. This can lead to memory allocation failures or performance degradation.
Memory fragmentation can occur in two main forms: internal fragmentation and external fragmentation.
Internal fragmentation occurs when a memory allocation is made to a larger block of memory than is needed. This can occur, for example, when a program requests a block of memory that is a multiple of the memory allocation unit size, leaving unused space within the allocated block.
External fragmentation occurs when the available memory space is divided into many smaller fragments, making it difficult to find a contiguous block of memory to satisfy a larger memory allocation request. This can happen when many small memory allocations and deallocations occur over time, leaving small gaps of unused memory between allocated blocks.
To reduce the impact of memory fragmentation, operating systems and programming languages often provide memory management techniques such as garbage collection, memory pooling, and defragmentation tools. Garbage collection automatically frees unused memory, memory pooling pre-allocates a fixed number of memory blocks of the same size to reduce fragmentation, and defragmentation tools reorganize the memory space to reduce the number of small gaps between memory blocks.
+) Overview of implementing above techniques
Garbage Collection: Garbage collection is a technique used to automatically free memory that is no longer in use by the program. One way to implement garbage collection in C is to use a mark-and-sweep algorithm. This involves periodically traversing the memory space and marking all memory blocks that are still in use. Any memory block that is not marked can be safely deallocated.
Memory Pooling: Memory pooling is a technique used to pre-allocate a fixed number of memory blocks of the same size, which can be reused for future memory allocations. In C, memory pooling can be implemented by using a data structure such as a linked list to keep track of the available memory blocks. When a memory allocation request is made, a block from the pool can be returned if one is available, rather than allocating new memory from the operating system.
Defragmentation: Defragmentation is a technique used to reduce memory fragmentation by reorganizing the memory space to reduce the number of small gaps between memory blocks. In C, defragmentation can be implemented by copying memory blocks to new locations in memory to consolidate small gaps and create larger contiguous blocks of free memory.
Implementing these techniques in C requires a deep understanding of memory management and can be challenging to do correctly. It is also worth noting that modern operating systems often provide their own memory management tools, and it may be more efficient to rely on these built-in tools rather than implementing your own.
How much to free?
모든 블록의 header field에 블록의 크기를 명시하여, 그 정보를 활용해 지정된 만큼만 할당 해제
Methods for Keeping track of free blocks?
-
Implicit list of free blocks
- 모든 allocated or free block에 header를 두어서 각각의 size정보로 다음 block이 어디서 시작하는 계산해서 넘어갈 수 있는 방법
- 가장 기본적인 방법으로 다른 더 발전된 방법에서도 사용하는 기본 개념을 가지고 있음
-
Explicit free list
- block에서 정보를 써서 다음 이어지는 free block을 연결해주는 것
- 더 효율적일 수 있음
-
Segregated free list
- 여러개의 리스트를 사용해서 특정 범위의 사이즈에 대해 저장
-
Other
- Blocks sorted by size using a balanced tree
- Buddy System
Implicit Free List and the basics of Allocation
Placement policy : Finding a free block
-
First fit : Allocate block into the first free block that is big enough in the list
-
Next fit : Start searching for the free block from where it was last updated (allocated or freed) But, usually results in worst memory fragmentation
-
Best fit : Find for the free block that has the closest size(?) resulting in the best memory utilization but also leads to space and time tradeoff
-
Good fit : first 와 best의 혼합 버전 - 힙의 특정 부분에서만 찾는다던지
-
그 외 - Multiple free list(Segregate free list) : 찾는 리스트의 길이가 줄어드니까 시간도 더 줄어들거고, 블록의 크기 범위도 맞춰서 하니까 fragmentation도 줄일 수 있음 --> best fit을 효과적으로 적용할 수 있는 방법
Splitting policy
split the free block with the size of block needed and allocate in the first block, make the latter part as free block
작은 블록에 대해서는 splitting을 안하도록 정책을 세울 수도 있음
Coalescing policy : Freeing a block
Coalesce meaning "join together"
When a block is freed, there might be other adjacent free blocks. So whenever a block is freed, adjacent blocks must be checked and coalesced.
Coalescing time
일반적으로(?) Malloc-Lab에서와 같이 블록을 할당 해제할 때 마다 앞뒤 블록의 할당정보를 확인하여 free block를 바로 coalescing 하는 방법을 채택하는 것 같다. 그러나 필요에 따라 상황에 맞춰 효율을 증가시키기 위해 한꺼번에 몰아서 coalescing을 하는 방법을 채택할 수도 있다고 한다.
Deferred coalescing : 특정 threshold 까지 기다렸다가 한꺼번에 coalescing 하도록 정책을 세운 것
Boundary Tags
각각의 블록의 footer에 해당 블록의 크기와 할당정보를 저장해 둠
그런데, 만약에 footer가 없다면 앞에있는 블록의 할당여부를 확인하기 위해선 리스트의 맨 앞에서부터 다시 차례대로 확인하는 수 밖에 없다는 문제가 발생한다. 이러한 상황을 해결해주기 위해 각각의 블록에는 헤더와 동일한 정보(해당 블록의 크기와 할당 정보)를 가지고 있는 footer가 있어야 하며, 이는 boundary tag 라고 부르기도 한다.
Boundary Tag Optimization
어쨌든 footer도 overhead 데이터로 internal fragmentation이라고 볼 수 있다. 극단적으로는 아주 작은 payload를 가진 블록이 여러개 저장되게 되면, payload가 저장된 메모리보다 header 및 footer가 저장된 메모리가 더 많을 수도 있다.
Footer는 free block에 대해 coalescing 할 때 필요하며, allocated block에는 없어도 되는 정보이다. 따라서, free block이 이전 block의 allocation status를 가지고 있으면 allocated block은 footer가 없어도 되며, 모든 allocated block에서 word size의 메모리를 아낄 수 있다.
Free block의 header/footer에 8byte alignment로 인해 비어있는 비트에, 해당 블록의 할당 정보와 함께 앞 블록의 할당 정보를 저장함으로서 해결할 수 있다.
Implicit Free List - Summary
- 심플한 구현
- Allocation cost : linear time worst case
- Free cost : constant time worst case, even with coalescing
- Memeory usage : placement policy에 따라 다름
- linear time이 걸리기 때문에 malloc/free에서는 사용되지 않음 - 하지만 splitting, boundary tag, coalescing 은 모든 allocator에서 사용되는 개념
구현 결과에 대한 분석
Next fit 의 경우 상황에 따라 first fit에 비해 오히려 memeory utilization이 더 나쁠 수 있다. 그러나 general 한 상황에서, 혹은 주어진 테스트 케이스에서, first fit으로 진행한다면 이미 할당된 블록으로 꽉 차있는 앞쪽을 일일히 확인하면서 뒤에 비어있는 블록을 찾아가게 되는 반면, next fit은 마지막으로 allocate 한 블록 또는 마지막으로 free 한 블록부터 탐색을 하기 때문에 시간적인 면에서 훨씬 효율성이 좋고 결과적으로 적은 throughput이 나올 수 있다.
이와 같은 이유로, fist fit으로 구현한 경우 44점의 utilization과 9점의 throughput이 나온 것에 반해 next fit은 43점의 util(더 낮음)과 40점의 throughput을 보이는 것을 확인할 수 있었다.
Explicit Free List
Explicitly links the free blocks together into a doubly linked list.
Explicit free list를 사용하는 경우 allocated block은 이전과 동일하게 header, payload(+padding)(+footer)로만 구성되어있고 free block의 경우 doubly linked list처럼 next item과 previous item에 대한 정보를 가지고 있다.
free block만 track 하면 되기 때문에 allocated block과 상관 없이 free block의 payload 구간을 자유롭게 사용하면 된다.
LIFO(Last in first out) 방식과 주소 순 정렬 방식이 있는데, 주소순 정렬 방식의 경우 알려진 구현된 방식은 거의 없는 것 같고, LIFO 방식만 구현을 해 보았다.
각각의 free block에서 predecessor와 successor의 포인터를 저장하고, 블록을 할당하고 해제할 때마다 앞뒤 블록의 predecessor/successor 정보를 바꿔주며, block이 할당되는 경우에는 해당 블록을 splice out 하고, 새로 추가되는/수정된 free block은 explicit free list의 가장 앞에 삽입해주는 방식이다.
// 회고
구현와 테스트를 마친 implicit 코드를 기반으로 explicit free list를 적용했고, 구현을 마쳐 테스트를 진행하는데 오류가 날 리가 없을 것 같은데 자꾸만 payload 배치 오류, segmentation fault 등의 오류가 떠서 정말 혼란스러웠다. 그 와중에 디버거가 실행이 안돼서 디버거가 되게 만드는데 시간을 쓰느니 함수마다 printf를 하여 문제가 되는 부분을 찾는 방법으로 선회하였다.
찍어본 결과 (당연히) free list 관련해서 구현한 부분에서 문제가 나고 있었고, 오류가 터지기 직전 내용을 타고타고 올라간 결과 coalescing에서 무언가 빠지고 있다는걸 발견했다.
전날 아무리 찍어봐도 정확한 오류 부분이 찾아지지 않아서 포기하자 생각하며 자러 기숙사에 들어갔었다. 그런데 확실히 졸린 상태보다 다음날 아침에 맑은 정신으로 차분하게 다시 디버깅을 시작해보니 생각보다 금방 오류 구간을 찾을 수 있었다.
free list에 insert 해주는 함수를 return할 때마다 넣어줬어야 했는데 딱 한줄 빼먹었던 것이었다.
차분하게 찾아낼 수 있어서 정말 기분이 좋았다. 이제 segregated list를 얼른 해보자!!
Segregated Free List
Segregated Free List 방법은 특정한 블록 크기 또는 크기 범위의 리스트를 여러개 만들어, find fit, insert, remove 등을 할 때 특정한 크기의 리스트에서만 검색하고 조작하도록 하는 방법이다. 이에 따라, 검색을 하며 봐야하는 블록의 개수가 효율적으로 줄어들 수 있기 때문에 throughput을 크게 증가시킬 수 있고, 동시에 필요한 사이즈의 블록을 찾아서 할당하기 때문에 best fit 또는 good fit 정도의 메모리 효율성을 챙길 수 있다.
현재 나와있는 메모리 할당 기준 중에 가장 좋은 방법이라고 한다. (저자 직강, CS:APP 3판 출간 시기 기준)
구현을 열심히 하고 있지만 아직도 C언어에 적응하는 중이기 때문에 이 global variable이 이해가 가지 않았다.
static void *segregated_list[LISTLIMIT]그래서 gpt에게 물어본 결과:
The
segregation_listarray is an array of pointers to free blocks, so each element of the array is a pointer to a block header in the heap memory.In the
mm_initfunction, thesegregation_listarray is initialized to containNULLpointers, indicating that there are no free blocks in the heap memory yet. Later, when a block is freed, its header address is added to the appropriate free list, and the correspondingsegregation_listpointer is updated to point to the new head of the free list.So while
segregation_listitself does not store any data or addresses in the heap memory, each element of the array is a pointer to a block header in the heap memory. Thesegregation_listarray is simply used to keep track of the free lists, and each element of the array is a pointer to the head of a free list.
이 변수 자체가 heap의 어느 지점을 가리키는게 아니라 포인터로 구성된 리스트이기 때문에 맨 앞에 asterisk가 붙는거였다. ㅎ (바보..)
// 디버깅 과정
1. free list에 insert 할때는 case를 잘 나눠서 구현했는데, remove 에서는 너무 간단하게 생각하고 넘어갔었다. 디버깅 결과 여기가 문제가 있는걸 보고 자세히 들여다보니 내가 너무 naive 하게 생각하고 넘어갔다는걸 깨닫고 다시 그림을 그려서 case를 나누어 주었다.
2. 주소를 출력한 하면 hexadecimal 형태로 되어있는걸 integer로 변환해서 숫자끼리 비교해 어느 주소가 힙에서 더 높이 위치하고 어느게 더 아래에 있는지, 맞게 배치되어있는지 비교해보았다. (비효율적인 방법인 것 같지만 지금으로서는 생각나는 유일한 방법이었다 ㅠ)
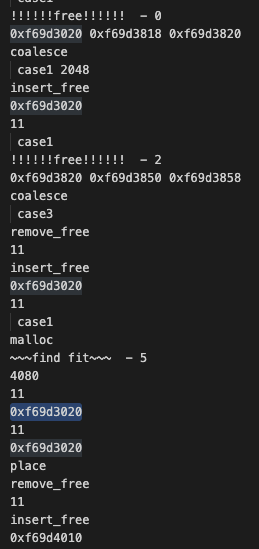
- 2번 블록을 free 할 때 0번과 합쳐서 free list 에 insert 할 때 어떤 list에 들어가는지 확인하기
- 5번 블록이 알맞은 list에 들어갈 공간을 찾는지 확인하기
확인해본 결과 할당이 해제된 공간의 크기가 충분하지 않아서 새로 할당되는 블록이 들어가면 안되는데 계속 엉뚱한 곳에 들어가고 있었다.
문제되는 free block의 coalescing 과정을 살펴본 결과 크기 범위에 맞는 segregated list에 들어가야 하는데, 다른 사람들의 풀이에서 참고했던 비트연산과정에서 list 번호가 제대로 계산되지 않는 경우가 발생해서 그런 것으로 보였다.
다른 사람들은 <<= 연산을 통해 2로 나누어주는 연산으로 원하는 segregated list에 찾아가던데.. 나는 계산해본 결과 소수점 아래가 버려지면서 리스트의 크기 범위가 뒤섞이는 현상을 보이고 있었다.
결국 소수점을 살리는 float 연산을 통해 해당 문제를 해결하였고, 몇시간 동안 붙잡고 있던 해당 오류를 해결할 수 있었다.
