
🪶 LoRA (Low Rank Adaptation)
이번에는 저번 글에서 말한 것 처럼LoRA(Low Rank Adaptation) 에 대해서 알아보겠다.
「LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021)」
LoRA는 위의 논문 「LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021) 에서 제시된 기존의 Fine-tuning을 개선한 방식이다. LoRA가 제시되기 이전에는 Fine-tuning은 전체의 파라미터를 조정하는 Full Fine-Tuning으로 이루어졌다. 이름만 들어도 전체 파라미터를 조정한다는 말에서 알 수 있듯, 비용이 어마어마하게 많이 들었다. 그래서 해당 논문에서는 LoRA를 사용해 저차원 부분행렬을 통해 일부 가중치만 조정하는 기법을 소개한다.
따라서 해당 논문을 바탕으로 LoRA에 대해서 정리를 해보겠다.
📘 Introduction of LoRA
논문에서는 LoRA가 제시된 이유로 기존의 파인튜닝 방식인 Full Fine-Tuning의 단점을 먼저 이야기한다. 크게 두 가지 단점이 있었는데, 첫 번째로 엄청난 양의 연산 비용을 요구한다는 점이다. 두 번째로 테스트를 위해 각 파라미터를 조정할 때 모델을 저장하여 성능 지표를 측정해야 한다는 점이다. 이는 GPT-2와 RoBERTa와 같은 LLM이 적은 기간 내에 계속 출시되면서 파라미터 수가 급격히 증가해 점점 어려워졌다. 이를 완화하기 위해 일부 파라미터만 저장하는 Adapting이라는 기법이 있었으나, 모델의 깊이가 증가하면 성능이 떨어지는 문제가 있었다.
위 그림은 LoRA를 간단히 설명하는 그림이다. 그림을 보면 차원의 입력이 각각 Pretrained로 설정된 가중치 와 에 input으로 들어간다. 여기서 LoRA의 핵심 개념을 알 수 있는데, 바로 기존의 는 freeze 시키고 입력을 새로운 layer에 입력으로 넣어 저차원 공간으로 축소(Down Projection)하는 행렬 를 거친다는 점이다. 참고로 는 출력 값의 차원이고, 은 Down Projection 했을 때의 차원이다. 이렇게 차원의 입력을 차원으로 줄여낸 뒤, 다시 행렬을 통해 원래 출력 차원 로 확장(Up Projection)한다. 결국 전체 업데이트 행렬은 형태가 된다.
위의 식이 최종적으로 LoRA가 가중치를 구하는 방법이다. 기존의 방법인 Full Fine-Tuning은 다음과 같다.
위 식은 가중치 전체를 조정하는 Full Fine-Tuning을 나타낸다.
이 그림은 원래 가중치 는 동결시키고, 작은 두 개의 행렬 만 학습해서 기존 선형 변환 결과에 보정값을 더해주는 구조를 단순하게 보여준다. 이를 통해 큰 모델 전체를 건드리지 않고도 파라미터 효율적인 학습이 가능하다는 것이 LoRA의 핵심이다.
여기서 핵심은 바로 인데, 논문에서는 파라미터가 175B이고 출력 차원 수가 12,288인 GPT-3에서도 또는 정도의 매우 작은 값으로도 성능이 유지된다고 한다. 사실 이렇게 들으면, 왜 성능이 유지되는지 의문이 될 정도로 터무니없게 차이가 크다.
논문에서는 이러한 원리를 LoRA를 고안할 때 영감을 받은 「Measuring the Intrinsic Dimension of Objective Landscapes (ICLR 2018)」, 그리고 「Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning (ACL 2021)」에서 언급한 LLM 모델의 Fine-Tuning은 저차원 공간에서 이루어진다는 이유로 설명한다. 두 논문에서는 거대한 네트워크라도 학습할 때는 저차원 공간(subspace)에서만 움직여도 충분하다는 발견, 그리고 대규모 언어모델 파인튜닝에서도 실제로 필요한 변화는 낮은 intrinsic dimension 안에서 발생한다는 것을 실험적으로 입증했다고 한다. 따라서 사실상 Fine-Tuning은 학습할 입력값에 대해 전체 차원을 사용할 필요가 없다는 것이다.
LoRA는 기본적으로 기존 파인튜닝보다 더 일반화된 방식이다. 풀 파인튜닝이 전체 파라미터를 학습하거나 일부만 선택해서 학습하는 것이라면, LoRA는 한 단계 더 나아가서 가중치 행렬 업데이트가 꼭 풀랭크(full-rank)일 필요가 없다는 점에 주목한다. 즉, 모든 가중치 행렬에 LoRA를 적용하고 bias까지 학습하며, rank $r$을 원래 가중치 행렬의 랭크 수준으로 높게 잡아버리면 사실상 풀 파인튜닝과 같은 표현력을 회복할 수 있다. 다시 말해, 학습 가능한 파라미터 수를 늘릴수록 LoRA는 풀 파인튜닝에 점점 가까워진다.
📊 Results
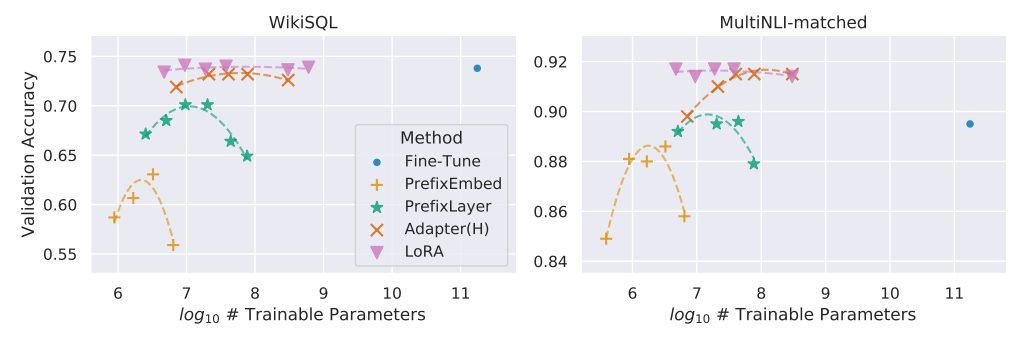
실험 결과를 보면 LoRA가 왜 이렇게 주목받는지 바로 알 수 있다. 먼저 평가 지표에 대해서 설명하겠다.
WikiSQL은 자연어 질문을 SQL 쿼리로 바꾸는 데이터셋이다. 예를 들어 2010년에 개봉한 영화 제목 알려줘라는 문장이 들어오면 모델은 그걸 SQL 쿼리 형태로 바꿔야 한다. 그래서 단순히 언어 이해만 보는 게 아니라 데이터베이스 쿼리까지 연결하는 능력을 평가한다.
MultiNLI는 두 문장의 의미적 관계를 따지는 데이터셋이다. 나는 점심을 먹었다와 나는 밥을 안 먹었다는 모순, 나는 점심을 먹었다와 나는 음식을 먹었다는 함의, 그리고 서로 관련 없는 문장은 중립으로 분류한다. 결국 모델이 문장 간 의미를 얼마나 정확히 파악하는지를 측정한다.
SAMSum은 대화 요약 데이터셋이다. 메신저 대화처럼 짧은 대화가 주어지고, 모델은 그걸 요약해야 한다. 예를 들어 A: 오늘 뭐해? B: 영화 볼 건데. A: 같이 가자라는 대화가 있으면 A와 B가 같이 영화를 보기로 했다라고 요약하는 식이다. 짧은 대화를 읽고 핵심만 뽑아내는 능력을 평가한다. 그리고 이런 요약 과제 성능을 볼 때 쓰는 게 R1, R2, RL이다. R1은 정답 요약과 단어 단위로 얼마나 겹치는지를 보는 지표이고, R2는 연속된 두 단어 bigram이 겹친 비율을 본다. RL은 최장 공통 부분 수열(Longest Common Subsequence)을 기반으로 해서 문장 구조 자체가 비슷한지를 평가한다. 결국 R1은 단어 겹침, R2는 구 겹침, RL은 문장 구조 겹침이라고 보면 된다.
우선 WikiSQL 결과부터 보면, Full Fine-Tuning은 가장 높은 성능을 보여주지만 파라미터 수가 엄청나다. 반면에 LoRA는 훨씬 적은 파라미터만 학습했음에도 불구하고 Full Fine-Tuning에 거의 근접한 정확도를 달성했다. Adapter(H)도 LoRA와 비슷하게 좋은 성능을 보이지만, Prefix 계열(PrefixEmbed, PrefixLayer)은 상대적으로 낮은 정확도를 보인다.
MultiNLI-matched 결과는 더 극적이다. Full Fine-Tuning이 여전히 좋은 성능을 내지만, LoRA와 Adapter(H)는 보다 높은 정확도를 훨씬 더 효율적인 파라미터 사용으로 달성했다. 특히 LoRA는 실질적으로 Full Fine-Tuning 수준의 성능을 뛰어넘으면서도 필요한 파라미터 수는 압도적으로 적다.
그리고 SAMSum에서도 LoRA는 Full Fine-Tuning보다 더 높은 수준의 정확도를 보였다.
즉, LoRA는 단순히 파라미터를 줄이는 수준이 아니라, 적은 자원으로도 풀 파인튜닝급 성능을 낼 수 있다는 걸 명확히 보여준다. 이런 점에서 실제 대규모 모델을 다룰 때 LoRA가 가지는 실용성은 엄청나다고 할 수 있다.
그리고 나는 FT가 항상 좋은 줄 알았는데, 찾아보니 과적합으로 인해 오히려 FT의 성능이 안 좋아질 수도 있다고 한다. 입력 데이터가 적을 경우 FT는 과적합이 일어날 가능성이 있지만 LoRA는 데이터셋이 적어도 적절한 학습이 가능하다.
📝 마무리
오늘은 LoRA에 대해 논문과 실험 결과를 중심으로 정리해 보았다. LoRA는 단순히 파라미터 효율성을 제공하는 수준을 넘어, 실제로 Full Fine-Tuning에 맞먹거나 그 이상의 성능을 적은 자원으로 달성할 수 있음을 보여준다. 특히, 데이터셋 크기가 제한적이거나 리소스가 부족한 상황에서 매우 강력한 대안이 될 수 있다.
다음 글에서는 오늘 정리한 내용을 바탕으로 실제 코드를 통해 LoRA를 활용한 파인튜닝 방법을 자세히 살펴보겠다.
