고가용성 : 시스템이 장애 상황에서도 멈추지 않고 정상적으로 서비스를 제공할 수 있는 능력
✅ 노드 = 카프카 서버
- 카프카가 설치되어 있는 서버 단위를 의미
즉 쉽게말해서 Kafka가 설치되어 있는 서버를 노드 라고 부른다
이 노드 가 고장나면 메시지를 전달하는 것 자체가 막히기 때문에, 서비스 장애가 일어난다.
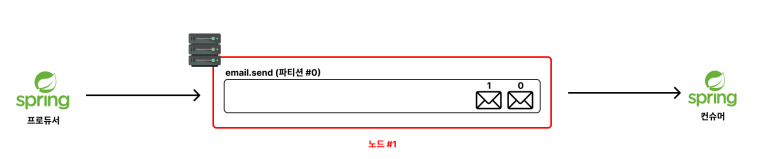
이러한 서비스 장애를 막기 위해서, 위그림과 같이 노드 를 1개만 두지 않고, 최소 3개의 노드를
구성한다. 그러면 첫번째 노드가 고장나더라도, 다른 노드에서 메시지를 저장할 수 있다.
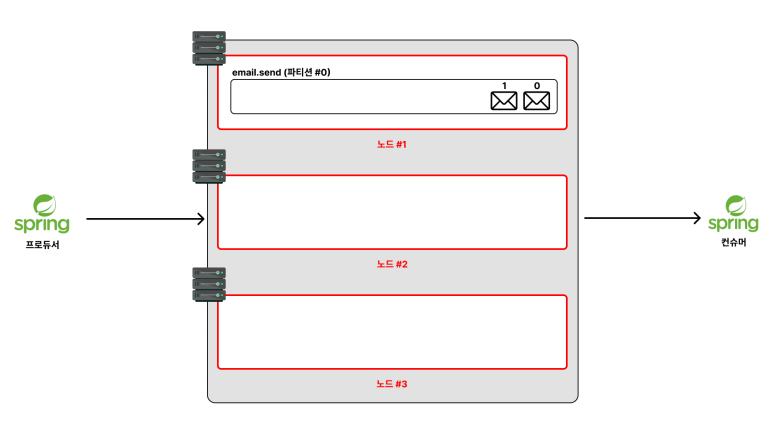
✅ 클러스터
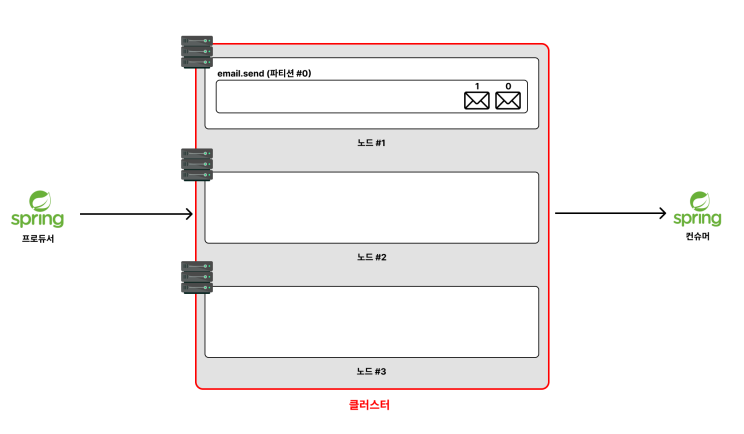
- 여러 대의 서버가 연결되어 하나의 시스템처럼 동작하는 서버들의 집합
위 사진에서 나온 3대의 노드 사진을 보면, 각 노드들이 서로 유기적으로 작동하고 있다.
장애시 시스템 전체가 중단없이 작동되게 만든다. 이와같이 유기적으로 작동하는 노드 들을 묶어서
클러스터 라고 부른다.
✅ 브로커, 컨트롤러
위에서 나온 노드(Kafka 서버) 는 크게 컨트롤러 와 브로커 로 구성되어 있다.
브로커 는 메시지를 저장하고 클라이언트의 요청을 처리하는 역할을 한다.
컨트롤러 는 브로커들간의 연동과 전반적인 클러스터 상태를 총괄하는 역할을 한다.
쉽게 비유하면, 브로커 는 직원, 컨트롤러 는 총관리자로 비유하면 좋다
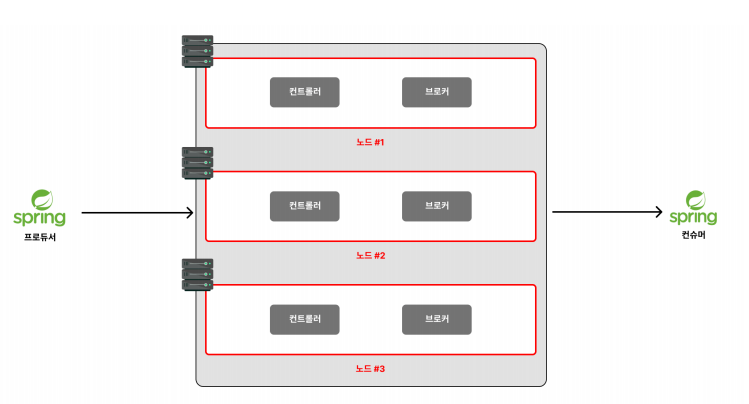
위 사진처럼 하나의 Kafka 서버에서 컨틀로러 와 브로커 를 동시에 셋팅을 할 수도 있지만
컨트롤러 와 브로커 를 분리해서 Kafka 서버를 구성할 수 있다.
기본적으로 Kafka 서버에서 브로커 는 9092번 포트에서 실행되고
컨트롤러 는 9093번 포트에서 실행된다.
하나의 Kafka 서버를 띄우면 프로세스가 2개가 실행된다 (9092, 9093) = 별개의 프로세스로 실행된다.
✅ 레플리케이션
- 데이터의 안정성과 가용성을 높이기 위해, 토픽의 파티션을 여러 Kafka 서버에 복제하는 것을 의미
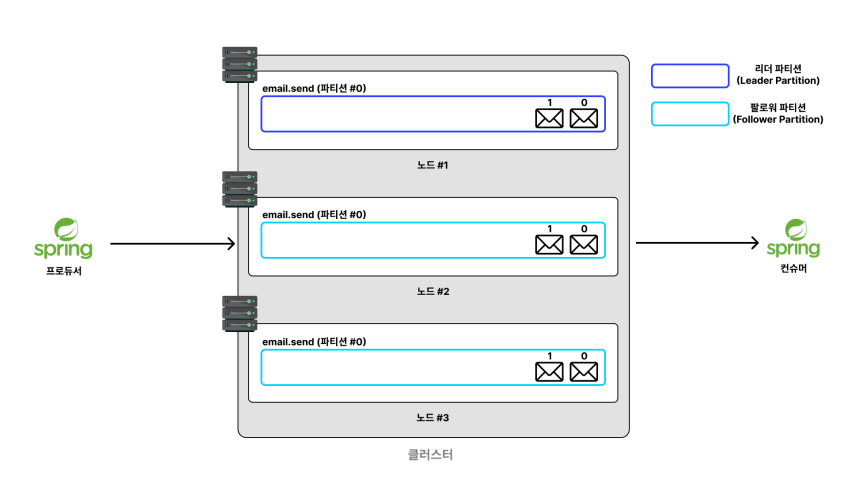
위 사진처럼 첫번째 Kafka 서버에 있는 파티션을 각각 노드2, 노드3에 복제한것을 볼 수 있다.
여기서 원본 파티션을 리더 파티션 이라고 부르며, 복제한 파티션을 팔로워 파티션 이라 부른다.
리더 파티션 은 프로듀서나 컨슈머 서버가 직접적으로 메시지를 쓰고 있는 파티션이며
팔로워 파티션 은 프로듀서나 컨슈머 서버가 메시지를 쓰고 있지 않다.
ex) 프로듀서 서버는 메시지를 리더 파티션 으로만 넣는다.
ex) 컨슈머 서버가 메시지를 꺼내서 처리할 때는 리더 파티션 에 있는 메시지만 꺼내서 처리한다.
팔로워 파티션 은 리더 파티션 의 메시지를 실시간으로 복제하며 유지한다.
ex) 프로듀서 서버가 오프셋 2번 메시지를 리더파티션 에 넣는 순간, 팔로워 파티션 에 그 메시지를 가져온다.
리더 파티션 이 장애가 발생하면, 팔로워 파티션 이 대신 리더 파티션 역할을 담당한다.
그로 인해 장애가 발생해도, 팔로워 파티션 이 메시지를 정상적으로 처리할 수 있다.
= 복제한 파티션이 리더 역할을 하게됨 = 팔로워 파티션 이 리더 파티션 으로 승격
레플리케이션 개수는 kafka 서버 수만큼 설정할 수 있지만,
실무에서는 레플리케이션 개수를 2나 3으로 설정해서 활용한다.
레플리케이션 개수를 많이 설정하면, 복제가 너무 많이되서 디스크 공간이 부족해지고, 속도가 느려진다.
ex) kafka 서버를 3대로 설정했는데, 레플리케이션 을 3개보다 많은 개수로 설정할 수 없다.
✅ 연습 (강의참고)
우선 하나의 EC2에 3대의 Kafka 노드를 구축했다고 가정하자
노드 안에는 각각의 (브로커, 컨트롤러) 가 존재
Kafka 노드에 토픽을 생성하면서 (레플리케이션) 까지 생성하기
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic 토픽명 partitions 1 --replication-factor 3 -> email.send 토픽을 생성하면서 파티션은 1개, 복제파티션은 3개 생성
위에서 만든 토픽 세부정보 값을 출력하면 아래와 같이 나온다
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic email.send

PartitionCount : 해당 토픽의 파티션 수
ReplicationFactor : 해당 토픽의 레플리케이션 수
Partition : 파티션 번호 (0 부터 시작임)
Leader : 해당 토픽의 리더 파티션을 가지고 있는 노드 id (노드번호는 1부터 시작)
= 1번 Kafka 서버에 리더파티션의 정보를 가지고 있다는 뜻
Replicas : 해당 토픽의 파티션을 복제하기로 설정된 노드들의 id
Isr : 리더 파티션과 똑같은 상태로 복제(동기화)가 완료된 노드들의 id
💡 ISR 의 개수와 Replicas 개수가 맞지 않으면 장애가 있다는 신호로 받아들일 수 있다.
만약 리더 파티션 이 아닌 팔로워 파티션 에 메시지를 넣으면 어떻게 될까?
정답부터 말하면, 리더파티션과 팔로워 파티션들에 모두 다 메시지가 들어있는것을 확인할 수 있다
그 이유는 Kafka 프로듀서 서버는 메시지를 보내기전에, 파티션의 리더가 누구인지 확인하고
자동으로 리더 파티션 한테 메시지를 전송해준다.
결국은 팔로우 파티션 에 메시지를 전송하게 아니라 리더 파티션 에 메시지가 전송되었고
그 후에 복제가되서 팔로우 파티션 에 메시지가 들어있었던 것이다.
이게 가능한 이유는 Kafka 서버끼리 서로 연동되어 있어서, 리더 파티션 을 가진 노드가
어떤것인지에 대해 서로 주고 받을 수 있기 때문이다.
Producer → broker 2
broker 2 → (아 이건 내가 리더 아님)
broker 2 → broker 1 (리더)에게 전달
broker 1 → 메시지 저장
그 후에
리더 파티션에 write
↓
ISR 팔로워들에게 복제
↓
팔로워 파티션에도 데이터 생김✅ 리더 파티션에 장애가 발생하면 어떻게 될까?
기존 리더 파티션을 가지고 있는 노드를 조회하면 아래 사진과 같이 나온다.
사진과 같이 현재 1번 노드가
리더 파티션을 가지고 있다. 테스트를 위해 1번 노드를 종료시켜보자
그 후 다른 노드의 주로를 조회하면
사진과 같이
리더 파티션이 2번 노드로 승격된것을 확인할 수 있다.
또Isr에 1번 노드가 빠져 있는것을 보면, 문제가 있음을 확인할 수 있다.
여기에 메시지를 넣으면, 정상적으로 토픽에 메시지를 넣었음을 확인할 수 있다.
그 후에 다시 1번 노드를 복구시키고, 다시 2번노드를 조회하면
다시리더 파티션이 1번으로 바뀌었으며,Isr에도 다시 1번노드가 들어온것을 확인할 수 있다.

✅ 정리
Kafka 서버를 3대로 구성하면, 특정 브로커에 장애가 발생하더라도 서비스가 중단되지 않는다.
브로커 간 파티션 복제를 통해 데이터 손실을 방지하며, 리더 파티션 에 장애가 발생할 경우
팔로워 파티션 이 자동으로 리더 로 승격되어 시스템은 지속적으로 운영된다.
이러한 구조는 Kafka의 대표적인 고가용성 (High Availability) 구성 방식이다.
쉽게 말하면
Kafka 는 다중 브로커 와 파티션 복제를 통해 장애 상황에서도 자동 복구 및 무중단 서비스를 제공한다.
Kafka 서버는 초기 단계 서비스의 경우는 1대 서버로도 충분하다 (비용 절감의 단계) 추후 점진적 확장
하지만 서비스 안정성이 중요한 단계의 경우 최소 3 대의 서버를 구성하는 것이 좋다.
✅ Spring Boot에 Kafka 서버 3대를 연결해서 사용하는 방법
Producer 서버와 Consumer 서버에서 각각 application.yml 파일을 수정해줘야함
<!-- Producer -->
spring:
kafka:
bootstrap-servers:
- {Kafka 서버 IP 주소}:9092
- {Kafka 서버 IP 주소}:19092
- {Kafka 서버 IP 주소}:29092
.....<!-- Consumer -->
spring:
kafka:
bootstrap-servers:
- {Kafka 서버 IP 주소}:9092
- {Kafka 서버 IP 주소}:19092
- {Kafka 서버 IP 주소}:29092
.....