이전에 만들어놓은 API 요청을 한번이 아니라 세번 연속으로 실행해보자
보내고나서 로그를 확인해보면, 한 번에 하나의 API 요청을 처리하는 것을 확인할 수 있다
SpringBoot는 멀티 쓰레드 기반으로 여러개의 요청을 병렬적으로 처리할 수 있는 구조를 가지고 있는데도, 왜 비효율적으로 한번에 하나의 요청만 처리하고 있는걸까?
이 문제의 원인은 파티션 과 밀접한 관련이 있다
✅ 파티션
큐(메시지를 임시로 저장할 수 있는 공간)을 여러개로 늘려서 병렬 처리를 가능하게 하는 기본 단위
✅ 파티션의 특징
각 토픽은 1개 이상의 파티션으로 구성할 수 있다.
토픽을 생성할 때 별도의 옵션을 주지 않으면, 아래와 같이 파티션을 한개만 생성한다
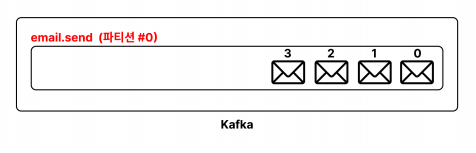
하지만 토픽을 생성할 때, 파티션을 여러개 만들 수 있다

Producer 가 특정 토픽에 메시지를 넣으면, 여러 파티션에 메시지가 적절하게 분산된다
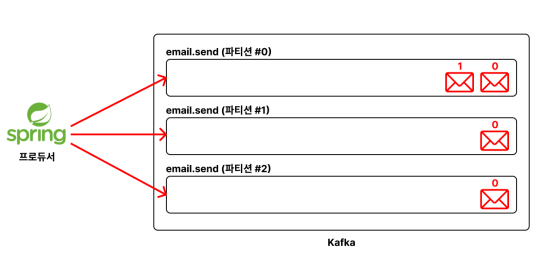
하나의 파티션 은 하나의 컨슈머에게만 할당한다
즉 여러 컨슈머 가 하나의 파티션 의 메시지를 처리할 수 없다
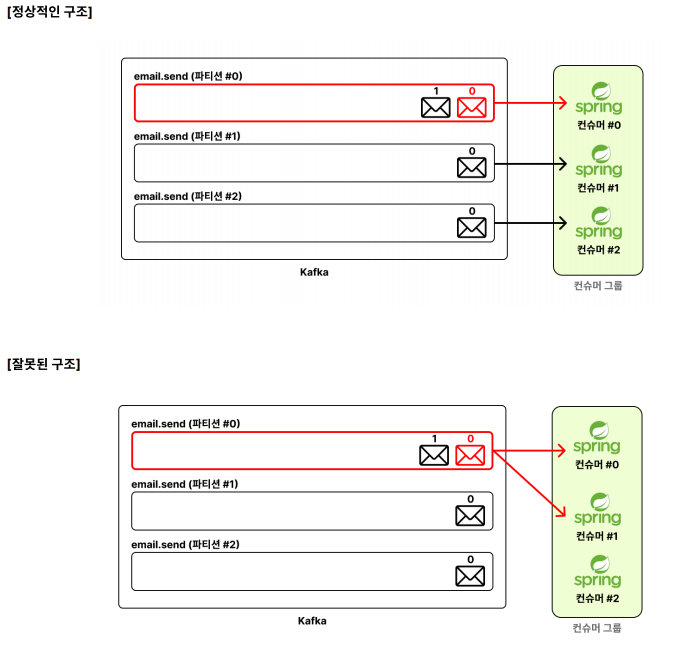
여러 컨슈머 서버가 하나의 파티션 의 메시지를 같이 처리할 수는 없지만,
하나의 컨슈머 서버가 여러 파티션 을 처리할 수 있다
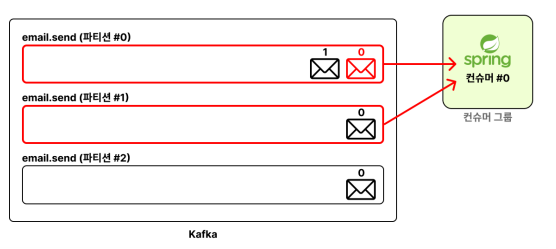
하나의 파티션 에 할당된 하나의 컨슈머 서버는 메시지를 순서대로 처리한다.
아래 사진과 같이 오프셋이 0,1 메시지를 병렬적으로 처리하지 않는다
그 이유는 파티션 단위로 메시지의 처리 순서를 보장하기 때문이다
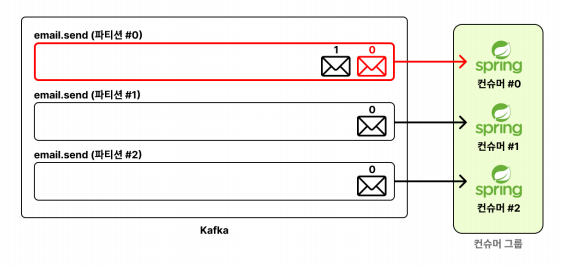
💡 정리하면 컨슈머 서버를 여러개 실행시켜도, 하나의 컨슈머 서버에서만 메시지를 처리한다
하나의 파티션 은 하나의 컨슈머 서버에게만 할당된다.
✅ 특정 토픽의 파티션 수 설정 / 조회 / 변경
- 토픽 생성할 때 파티션 수 설정 (토픽 생성 + 파티션 수 설정)
$ bin/kafka-topics.sh --bootstrap-server <kafka 주소>
--create --topic <토픽명> --partitions <파티션 수>
ex) $ bin/kafka-topics.sh --bootstrap-server localhost:9092
--create --topic joo.topic --partitions 3 -> joo 토픽을 생성하고 파티션을 3개로 생성
- 생성한 토픽에서 파티션 수 조회
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic joo.topic
아래 사진처럼 3개의 파티션이 생성된 것을 볼 수 있다
토픽을 생성할 때 별도의 옵션을 주지 않으면 파티션은 1개만 생성된다

이번에는 생성했던 토픽의 파티션 수를 늘려보자
- 기존 토픽의 파티션 수 변경
$ bin/kafka-topics.sh --bootstrap-server localhost:9092
--alter --topic joo.topic --partitions 5-> joo토픽의 파티션 수를 5개로 늘림

파티션 수를 늘릴 수는 있지만, 파티션 수를 줄일 수는 없다
명령어를 입력해서 파티션 수를 줄이면, 에러가 난다
그 이유는 파티션을 줄이는 과정에서 내부적으로 (데이터 손실, 성능 저하) 등의 문제가 발생하기 때문이다
만약 파티션 수를 줄여야 한다면, 새로운 토픽을 다시 생성해서 파티션수를 다시 설정해야한다
그리고 기존 토픽에 있던 내용들을 새로운 토픽에 마이그레이션 시켜야한다.
✅ 여러개의 파티션에 메시지가 골고루 들어가는지 확인해보기
특정 토픽에 메시지를 넣으면 여러 파티션에 메시지가 적절하게 분산된다.
이 때 메시지의 형태에 따라 파티션에 분배되는 방식이 달라진다.
1 . Key가 포함되지 않는 value 만 있는 형태의 메시지를 넣을 경우
스티키 파티셔닝 방식으로 메시지를 분산한다
-> 하나의 파티션에 메시지가 일정량 채워지면 그 다음 파티션에 메시지를 저장하는 방식
-> ex) 1 파티션에 10개의 메시지가 채워지면 그 다음부터 2파티션에 메시지 10개 채워짐 ....
Kafka 2.4 버전 이전에는 라운드 로빈 방식 (파티션을 번갈아가면서 하나씩 넣는 방식) 으로 분배했었다
하지만 대규모 메시지를 처리할 때는 스티키 파티셔닝 방식이 효율적이라서 변경되었다.
2 . Key 포함된 메시지를 넣을 경우
Key의 해시 값을 기반으로 파티션을 결정하여 메시지를 분배한다.
같은 Key 값을 가진 메시지는 같은 파티션에 들어간다.
이제 위에서 만든 joo 토픽을 기반으로 실시간으로 토픽의 파티션에 저장되는 메시지를 확인해보자
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092
--topic joo.topic --from-beginning --property print.partition=true
= joo.topic 토픽의 모든 메시지를 조회 ( + 파티션 정보도 같이 출력)
이렇게 명령어를 입력한 후 Api 요청을 여러번 보내면 하나의 파티션에만 메시지가 저장되는것이 확인된다
그 이유는 스티키 파티셔닝 방식이기 때문이다.
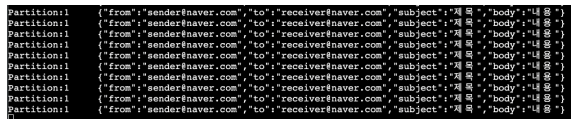
스티키 파티셔닝 방식이 대규모 데이터를 처리할 때는 유리하지만, 작은 규모의 데이터를 처리할 때는
하나의 파티션에만 메시지가 몰리는것은 좋지 않다.
이번에는 라운드 로빈 방식으로 메시지가 저장되도록 변경해보자
Producer 역할을 하는 Springbooat 서버의 application.yml 파일을 수정하면 된다
아래와 같이 properties 부분과 partitioner.class 부분을 수정하면 된다
spring:
kafka:
bootstrap-servers: 15.164.96.71:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
partitioner.class: org.apache.kafka.clients.producer.RoundRobinPartitioner ## 라운드로빙 방식이렇게 수정한 후 다시 api 요청을 여러번 보내면 아래와 같이 파티션에 메시지가 골고루 쌓인다
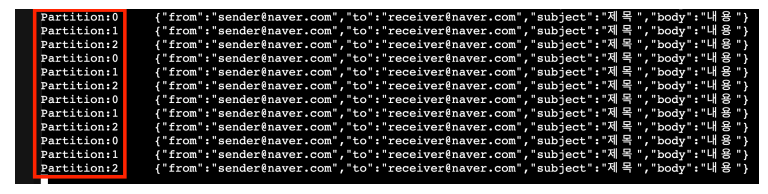
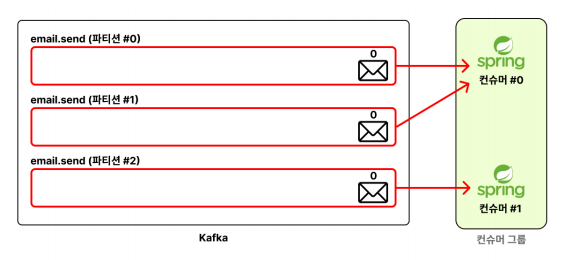
✅ 여러개의 컨슈머 서버로 메시지를 병렬적으로 처리하기
파티션이 여러개 있는 상태에서, 컨슈머 서버를 여러개 추가하면
컨슈머 서버의 개수에 맞게 알아서 파티션을 분배하는 것을 확인할 수 있다
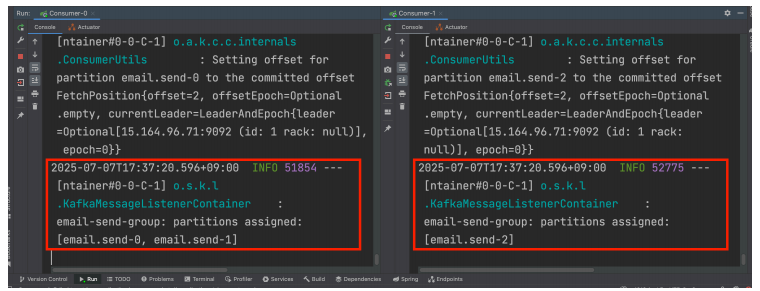
왼쪽 서버에는 파티션 0,1 로 분배되어있고, 오른쪽 서버에는 파티션 2가 분배되어있다
이와 같이 컨슈머 서버가 한대일때보다 여러대일 경우 메시지를 병렬적으로 처리하는것을 확인할 수 있다
아까 파티션이 하나였을 경우는 컨슈머 서버가 여러대여도 소용이 없었다
그 이유는 하나의 파티션은 하나의 컨슈머 서버에서만 담당하기 때문이다

하지만 파티션을 늘리면, 각 컨슈머 서버가 담당할 수 있는 파티션이 생기기 때문에
컨슈머 서버도 늘리면 메시지를 병렬적으로 처리할 수 있다. 대형마트로 비유하면 계산할 수 있는 카운터가 많아진 것이고 계산을 기다리는 손님을 빠르게 처리할 수 있는 것이다.
💡 하지만 컨슈머 서버가 메시지를 처리할 때 사용하는 리소스(CPU, 메모리) 가 부족한 상태이면
컨슈머 서버를 늘리는 것이 맞다. 하지만 무거운 작업이 아니고, 리소스가 부족하지 않은 상태라면
하나의 컨슈머 서버에서 여러 파티션을 병렬적으로 처리하는 방법을 사용해야한다.
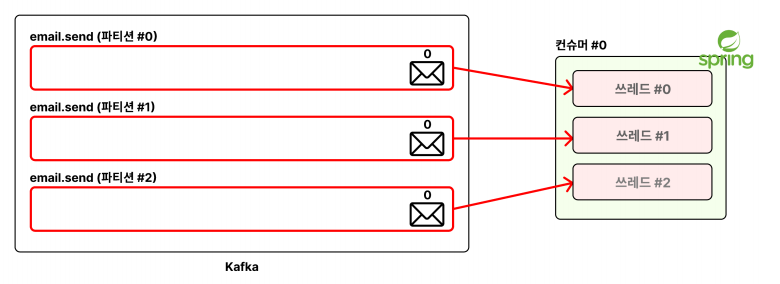
✅ 하나의 컨슈머 서버로 메시지를 병렬적으로 처리
위에서 만들어놓은 코드를 수정하면 된다 -> (멀티쓰레드 개수 증가)
@KafkaListener(
topics = "email.send",
groupId = "email-send-group",
concurrency = "3" // 멀티 쓰레드를 활용해 병렬적으로 처리할 파티션의 개수
)이렇게 설정한 후 다시 API 요청을 3번 보내면, 동시에 처리되는것을 확인할 수 있다
그럼 API 요청을 5번 보내면 어떻게 될까?
쓰레드가 3개이기때문에 3번의 요청은 바로 처리가 될것이고, 나머지 2개의 요청은, 메시지의 후순위에 있기 때문에, 다 처리된 후에 작업이 실행될 것이다.
그럼 쓰레드를 더 늘리면 되는것인가?
현재 파티션은 3개이기 때문에, 쓰레드를 더 늘린다고 해도 병렬적으로 메시지를 처리할 수 있는
메시지의 개수는 최대 3개밖에 안된다. 그러므로 5개요청을 병렬적으로 처리하고 싶다면
파티션의 개수부터 증가시키고 그 이후 쓰레드도 증가시키면 된다
💡 그럼 병렬적으로 처리하기 위해서 파티션을 많이 넣으면 되는것이 아닌가?
무작정 과도하게 파티션 수를 증가시키면 반대로 성능에 비효율성을 가져올 수 있다
적절한 파티션 수를 설정하는 것이 중요하다.
✅ 적정 파티션 개수 계산하는 방법
프로듀서가 보내는 메시지량 ≤ 하나의 쓰레드가 처리하는 메시지량 x 파티션 수
1 . 몇개의 쓰레드를 사용해야 처리량이 가장 높아지는 지 측정하기
SpringBoot 서버는 멀티 쓰레드 기반이기 때문에 동시에 요청을 처리할 수 있다.
이 때, 몇개의 쓰레드를 사용해야 요청을 가장 많이 처리할 수 있는지 측정해야한다.
부하 테스트를 통해서 확인하면된다
→ 100 개의 쓰레드를 활용하는 게 가장 효율적이라고 측정했다고 가정하자
2 . 하나의 컨슈머 서버가 처리할 수 있는 최대 처리량을 알아내기
컨슈머 서버가 적절한 쓰레드 개수를 기반으로 요청을 처리한다고 했을 때, 최대 처리량(Throughput)이
얼마나 되는지 측정해야한다.
-> 하나의 컨슈머 서버가(100 개의 쓰레드 활용) 1초에 처리할 수 있는 처리량이 30이라고 가정하자
-> 즉 1개의 쓰레드가 1초에 0.3 개의 요청을 처리한다는 뜻이다
3 . 프로듀서 서버가 보내는 평균 메시지량 알아내기
사용자가 API 요청을 얼마나 보내는 지와 같은 의미로. 사용자가 1초당 평균적으로 얼마나 요청을 보낼지
측정하거나 예상해야한다
-> 사용자가 평균적으로 1초당 100개의 메일을 보낸다고 가정
4 . 처리가 지연되지 않는 선에서 파티션 개수 계산
처리가 지연되지 않으려면 프로듀서에서 들어오는 메시지의 수보다 더 빨리 처리할 수 있어야 한다.
그리고 평균 메시지량이 어느 정도 초과할 것도 예상해서 계산해야 한다.
-> 평균 메시지량이 어느 정도 초과할 것을 예상해서 1초당 120 개 정도를 처리할 수 있게 만드려면,
아래 공식에 의해 적정 파티션 수는 400 개라는 걸 알 수 있다

컨슈머 서버가 메시지를 지연 없이 잘 처리하고 있는지 확인해보자
✅ Lag
- 컨슈머 서버가 아직 처리하지 못한 메시지 (지연된 메시지)의 개수이다
- Lag는 지연(deley) 의미를 가지며, 평소에 컴퓨터가 느려지면 렉걸린다 표현을 할 때 그 렉이다
컨슈머 렉이라고도 부른다
그럼 컨슈머 렉 은 언제 발생할까?
프로듀서 서버의 메시지 생산량 보다
컨슈머의 서버의 메시지 처러량이 작을 때 컨슈머 렉 이 발생한다.
예를들어 메시지가 1초에 3개씩 생기는데, 1초에 메세지를 1개밖에 처리를 못한다면
1초당 메시지 2개씩 계속해서 쌓일것이다.
현업에서는 주로 컨슈머 서버에 장애가 있을 경우 컨슈머 렉 이 발생하는 경우가 많다
이를 해결하려면 컨슈머 렉 을 지속적으로 모니터링 해야한다
먼저 CLI에서 모니터링을 해보자
CLI 에서 컨슈머 서버를 종료시키고 API요청을 보낸 후
그 후에 컨슈머 그룹 세부 정보를 조회하면
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group email-send-group --describe
아래 사진과 같이 LAG 의 개수가 들어있는것을 확인할 수 있다.
이 말은 파티션1 에는 처리되지않는 메시지가 2개, 파티션2,3은 처리되지않은 메시지가 1개씩 들어있다

하지만 24시간 내내 CLI로 컨슈머 렉 이 발생하는지 확인 할 수 없다.
그래서 외부 모니터링 툴을 사용해서 알림을 발생하도록 하는것이 좋은 방법이다.
오픈소스 추천 : 프로메테우스 , 그라파나
지금까지는 카프카를 직접 구축해서 사용했지만, 실제 현업에서는 클라우드(AWS)의 카프카 서비스를
사용하는 경우가 많다. 이 서비스를 사용하면 자체적인 컨슈머 렉 에 대한 모니터링 기능을 제공해준다.
