
기사에서 검사-> Copy -> Copy selector
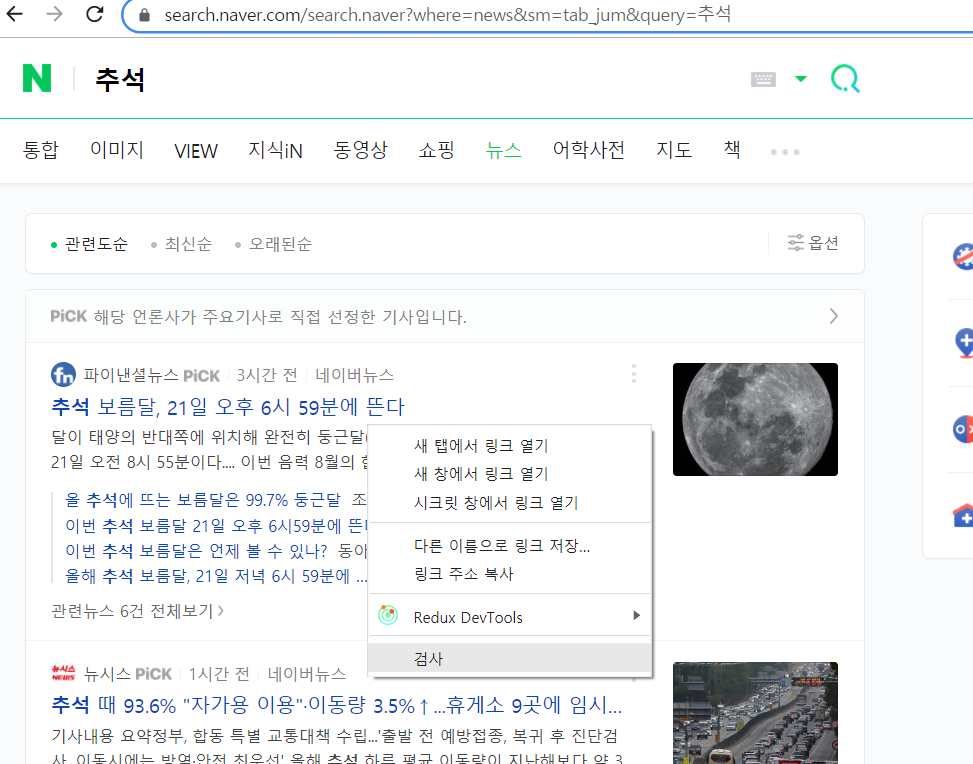
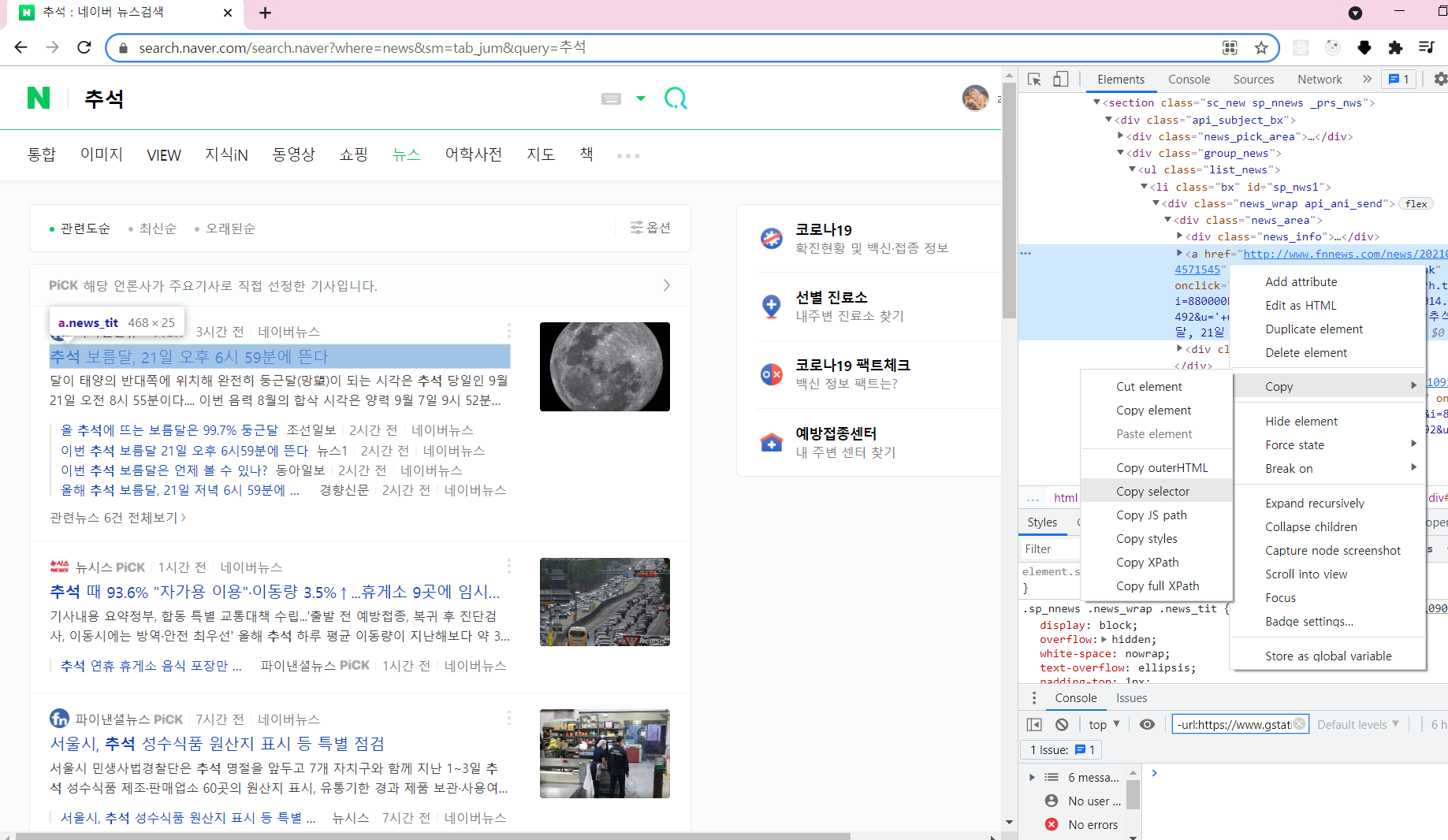
기사 타이틀 크롤링
팁
- 처음에 어디까지 select_one에 줘야하는 지 '범위지정'에서 애먹었는데
하다보니까 감을 잡았다. 일단 모르겠으면 네이버에서 마우스 오른쪽 -> 검사 눌러서 들어가면 범위지정이 빠르다. - 그리고 한번에 정답을 찾는다는 생각말고 계속 실행하면서 맞춰가는 것이 빨리 찾는 방법이다.
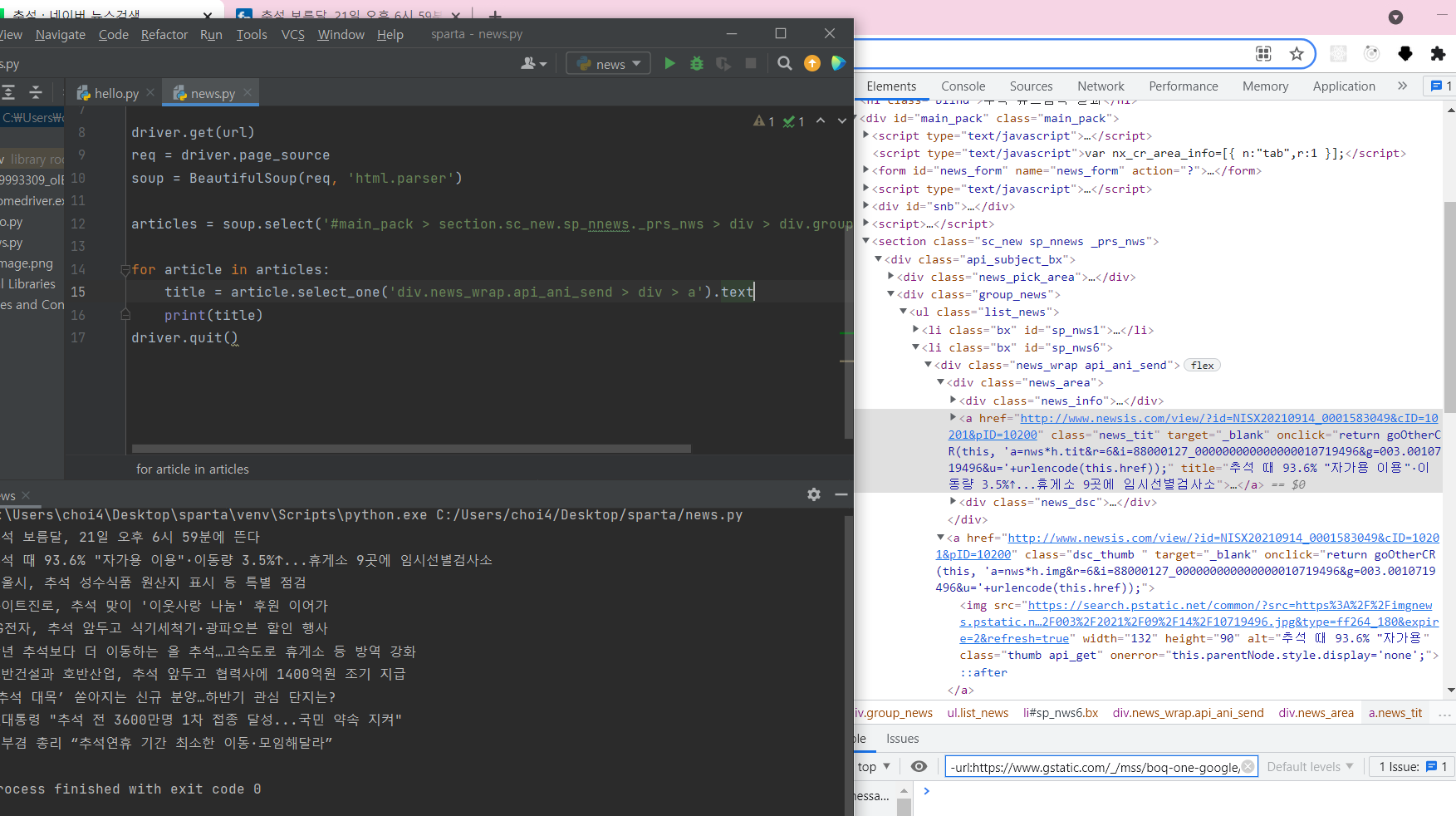
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=추석"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
articles = soup.select('#main_pack > section.sc_new.sp_nnews._prs_nws > div > div.group_news > ul > li')
for article in articles:
title = article.select_one('div.news_wrap.api_ani_send > div > a').text
print(title)
driver.quit()기사 url 크롤링
- 타이틀 스크랩하는 거랑 똑같은데 뒤에 ['href']붙이면 된다.
url = article.select_one('div.news_wrap.api_ani_send > div > a')['href']
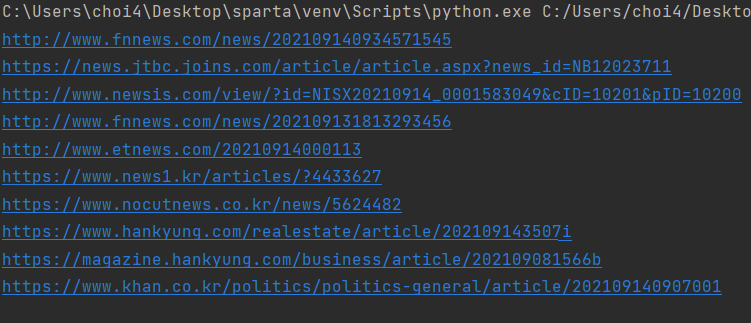
결과
언론사 이름 크롤링
- 언론사 이름만 쏙쏙 빼서 나오게 하기
- .split() 문법과 .replace() 문법을 썼다.
com = article.select_one('a.info.press').text.split(' ')[0].replace('언론사','')
결과

전체 코드
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=추석"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
articles = soup.select('#main_pack > section.sc_new.sp_nnews._prs_nws > div > div.group_news > ul > li')
for article in articles:
title = article.select_one('div.news_wrap.api_ani_send > div > a').text
url = article.select_one('div.news_wrap.api_ani_send > div > a')['href']
com = article.select_one('a.info.press').text.split(' ')[0].replace('언론사','')
print(title,url,com)
driver.quit()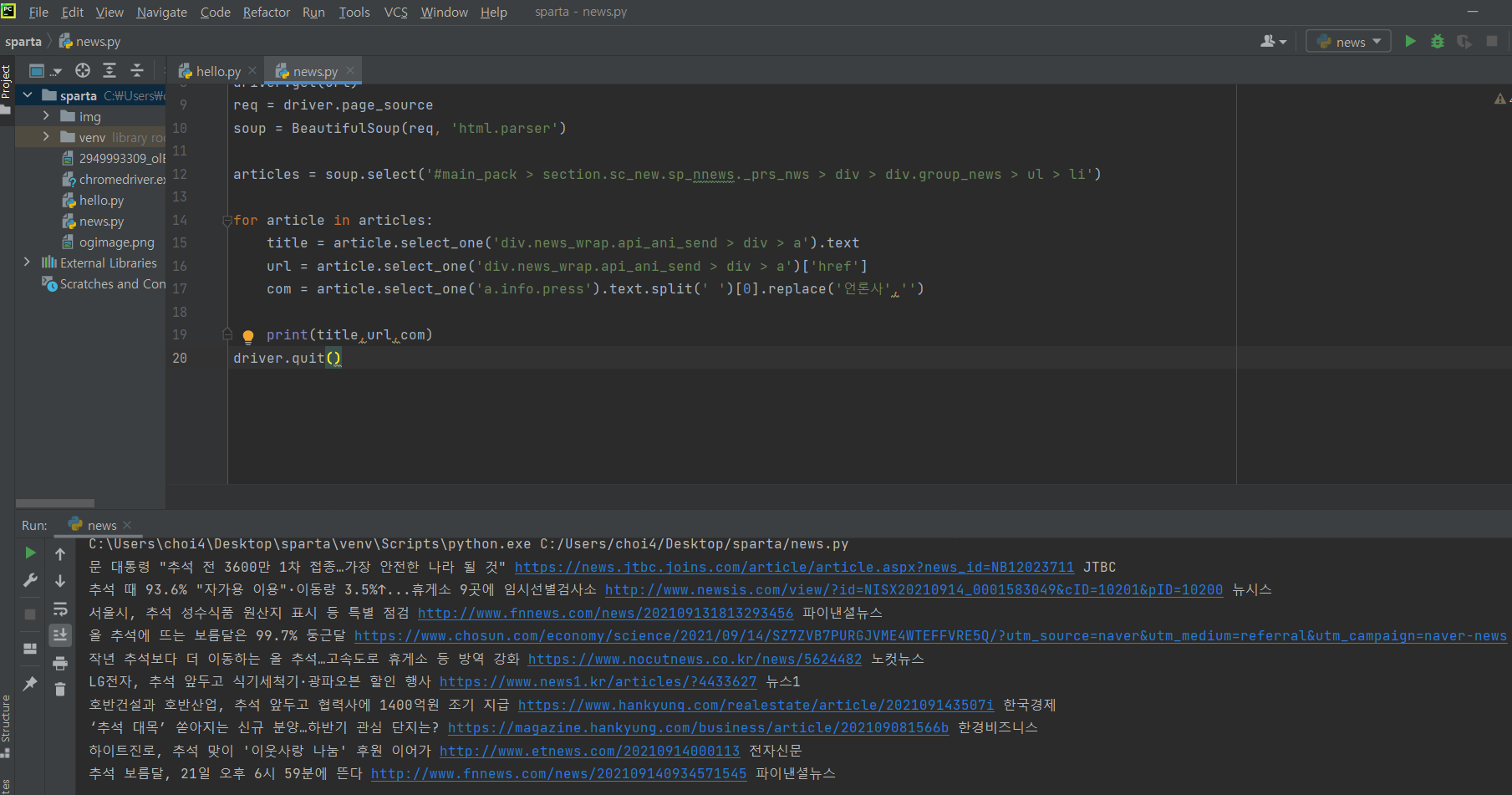
title, url, com이 전부 잘 스크래핑 되었다!
엑셀 저장하기
- openpyxl 패키지를 설치한다.
from openpyxl import Workbook # 엑셀 저장을 위한 라이브러리
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=추석"
driver.get(url)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
articles = soup.select('#main_pack > section.sc_new.sp_nnews._prs_nws > div > div.group_news > ul > li')
# 엑셀 저장을 위한 코드
wb = Workbook()
ws1 = wb.active
ws1.title = "articles"
ws1.append(["제목", "링크", "신문사"])
for article in articles:
title = article.select_one('div.news_wrap.api_ani_send > div > a').text
url = article.select_one('div.news_wrap.api_ani_send > div > a')['href']
com = article.select_one('a.info.press').text.split(' ')[0].replace('언론사','')
ws1.append([title, url, com]) # for문 안에 엑셀 저장 코드 넣기
driver.quit()
wb.save(filename='articles.xlsx')결과
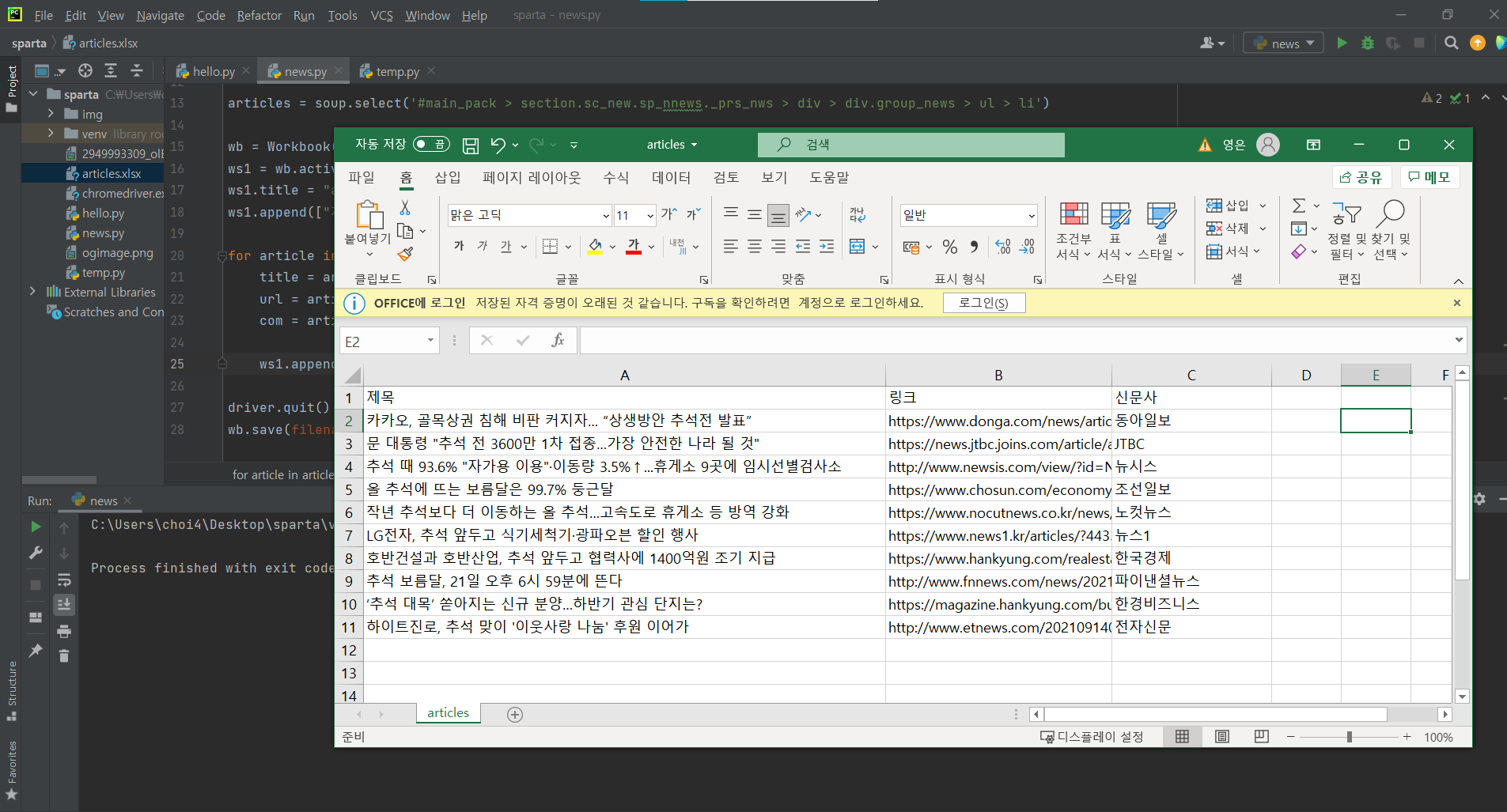
엑셀 파일에 잘 들어간 것을 확인할 수 있다!
진짜 편리
연습삼아 썸네일도 추가해봤다.
재밌다 ╰(°▽°)╯
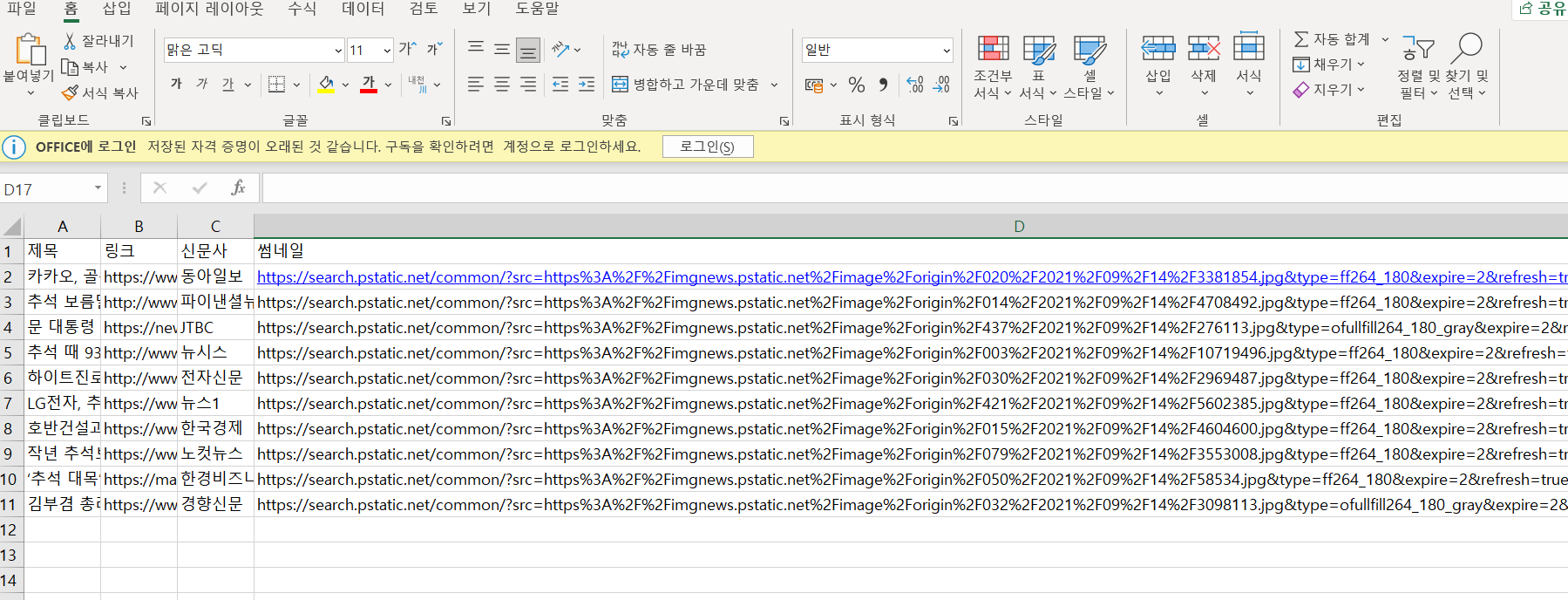
thum = article.select_one('div.news_wrap.api_ani_send > a > img')['src']

차근차근 채워가는 it일지