
파이썬 패키지(package), 라이브러리
- 파이썬에서 패키지는 모듈을 모아 놓은 단위
이런 패키지의 묶음을 라이브러리라고 한다. (보통 패키지와 라이브러리는 혼용해서 많이 씀)
virtual environment (가상 환경)
- venv — 가상 환경 생성
프로젝트별 공구함이라고 생각하면 편함.
공구함에 패키지를 담아두고 쓰면 관리가 편함
ex. 공구함 1에 a,b,c / 공구함 2에 b,c,d
파이썬 용어집
dload 라이브러리
-
dload는 URL로부터 파일 다운로드를 해주는 패키지입니다. 이 패키지를 이용해서 이미지를 내려받을 수 있다. -
file ->settings ->python interpreter -> dload 검색 -> install
사용법🎯
import dload
dload.save("https://spartacodingclub.kr/static/css/images/ogimage.png")이미지 웹 스크래핑(크롤링)
-
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것임 (한국에서는 같은 작업을 크롤링 crawling 이라는 용어로 혼용해서 쓴다.)
-
웹 스크래핑을 하기 위해서는 특정 웹페이지를 구성하는 HTML 정보를 받아와야한다. 여기서는 파이썬으로 크롬 브라우저를 직접 제어하여 웹페이지를 띄우고 HTML을 읽어오는 방식 채택
-
selenium패키지를 이용하면 브라우저를 제어할 수 있다. (dload처럼 설치)
셀레니움을 사용하기 위해서는웹드라이버라는 파일도 필요하다.
(크롬에서 내 버전 확인 후 설치) ▶웹드라이버 설치 링크
selenium 시작 코드🎯
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
driver.get("http://www.naver.com")- 패키지 추가 설치하기 (
beautifulsoup4)
project interpreter에서bs4를 검색해 다운로드
select / select_one의 사용법 알아야함!
beautifulsoup의 select 사용하기🎯
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')최종 코딩
import dload
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver') # 웹드라이버 파일의 경로
driver.get("https://search.daum.net/search?nil_suggest=btn&w=img&DA=SBC&q=%EC%86%A1%EA%B0%95") #송강
time.sleep(3) # 3초 동안 페이지 로딩 기다리기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
thumbnails = soup.select('#imgList > div > a > img')
#select는 리스트기 때문에 for문 돌리면 하나한 접근가능!
i = 0
for thumbnail in thumbnails:
img = thumbnail['src']
dload.save(img,f'img/{i}.jpg')
i += 1
driver.quit() # 끝나면 닫아주기
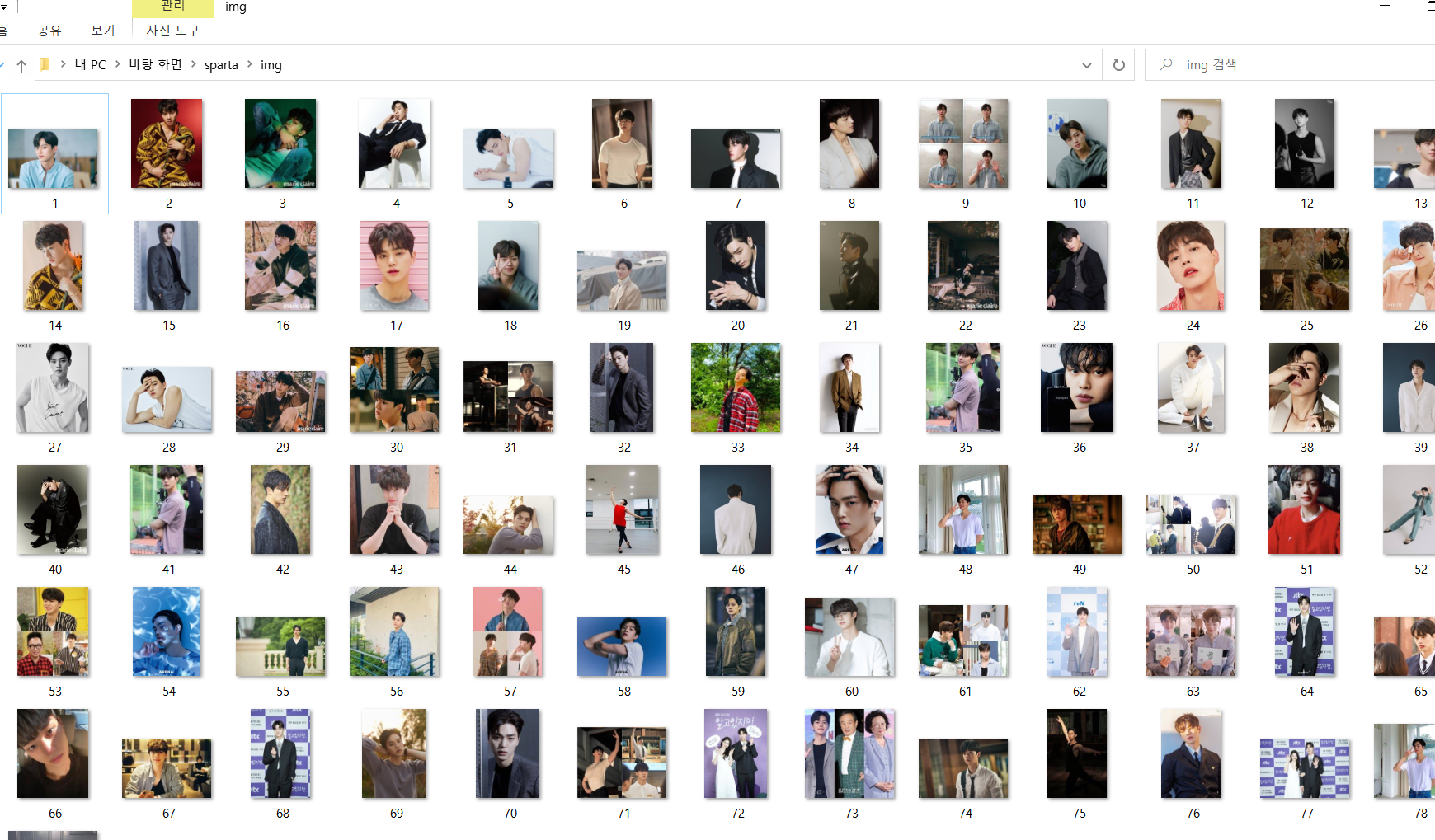
결과
img 파일에서 송강을 볼 수 있다!
스파르타 코딩 클럽의 48시간 코딩미션(무료강의)을 하고 있는데
유익하고 재미있다. 혼자 코딩 배우시는 분들은 한번씩 들으면서
익혀보는 것을 추천!
참고) 스파르타 코딩-파이썬 혼자놀기 노션노트📖

차근차근 채워가는 it일지