[논문리뷰] InstantDrag: Improving Interactivity In Drag-Based Image Editing (SIGGRAPH Asia 2024)
[논문리뷰] Diffusion Model
목록 보기
2/2

Intro

Project page / Code / Arxiv
- 서울대에서 인턴을 하면서 2저자로 참여했던 논문이 ACM SIGGRAPH Asia 2024에 accept되었다.
- 사실 생성모델 쪽 공부와 구현 경험도 나름 있다고 생각해서 연구에 조인하게 됐는데, 거의 처음부터 다시 배우는 수준이었고... 들어와서 6개월동안 배웠던 것이 이전 1년 반 동안 배웠던 것보다 훨씬 많았던 것 같다.
- 두 분 다 포스텍 때부터 봐 왔었는데, 인턴 기회를 주신 박재식 교수님께 감사드리고, 좋은 연구를 잘 마무리하고 나를 나름 쓸만 한(?) 인턴으로 성장시켜 주신 1저자 선배께도 감사드린다.
- 이 좋은 경험을 바탕으로 대학원에 진학해서도, 내 분야에서 석사 때부터 덜 헤매고 빠르게 치고 나갈 수 있는 사람이 되길..
Abstract

- Drag Editing을 기존의 방법들보다 최대 50배 빠르게, 3배 가볍게 수행하는 InstantDrag 모델을 제안한다.
- InstantDrag 모델은 다음과 같은 novelty가 있다.
- Drag Editing이라는 task를, 다음과 같은 2가지 subtask로 나눈다 : 1) Drag Instruction (sparse한 signal)을 plausible한 optical flow (dense한 signal)로 변환, 2) Original Image와 Optical flow에 condition되어 Edit된 이미지를 생성
- Large-scale video로부터 plausible한 motion generation과, motion conditioned diffusion model을 학습하여 generalizable한 모델
- Inversion, CFG을 제외한 guidance 테크닉을 사용하지 않음으로써 fine detail을 보존하면서도 model forwarding으로 간결한 inference -> A6000 기준 1.1초, A100 기준 0.7초 만에 이미지 편집.
1. Introduction
- Diffusion Model의 Sampling을 빠르게 하는 방법들은 최근에 많이 연구되어왔다. ODE Solver, Consistency Distillation, Adversarial Distillation 등... 이를 통해, 50step 이상이 소요되던 Diffusion Model의 forwarding을 1,2,4,8 step 등으로 줄일 수 있게 되었다.
- Image Editing 분야는 여러 문제가 남아있다. Instructpix2pix와 같은 text 기반 editing 방법은 이미지의 전체적인 분위기를 간단히 수정할 수 있지만, 특정 영역을 지정하여 세부적으로 편집하지는 못한다.
- DragGAN으로 시작된 Drag Editing은 움직임을 고려한, 정밀한 수정이 가능하다. 그러나 Drag Instruction으로 대표되는 motion 정보를 잘 이해하기 위해 LoRA, DDIM Inversion, Latent Optimization, Guidance 등 방법론들을 사용하고 이는 편집 속도를 느리게 하는 원인이 된다.
- 이를 해결하기 위해 4가지 문제점을 해결하려 했다. 1) Inference 속도 2) Real Image에 대한 Editing 3) Input Mask 없는 편집 4) text prompt 없는 편집. 이를 해결한다면, 이상적인 Image Editing (Interactivity가 중요하다.) 과 Drag Editing (text prompt를 필요로 하는 것이 unreansonable하다.) 에 가까워질 수 있다.
- Drag Editing을 2가지 task로 나누어, Training-based approach로 접근했다. 1) FlowGen: sparse한 Editing signal인 Drag Instruction을 dense한 signal인 optical flow로 변환하는 GAN 2) FlowDiffusion: input image와 optical flow를 condition으로 받아 conditional denoising process를 거쳐 이미지를 생성하는 Diffusion Model 이다.
- 모델 아키텍쳐를 간소화하고, mask와 prompt를 필요로 하지 않아 interactivity가 훨씬 증대되며, Large scale video로부터 효과적인 학습 방법을 통해 다양한 motion을 배우는 것이 실험적으로 효과가 있음을 입증한다.
- 최종적으로 최대 75배 더 빠르고, GPU 메모리 소모는 최대 5배 빠른 InstantDrag를 소개한다!
2. Related Work
2.1. Image Editing with Generative Models
- Generative Model은 Image Synthesis 뿐 아니라 Image Editing 분야에서도 꾸준히 연구되어왔다.
- GAN이 지배하던 시절, Image-to-Image Translation을 paired setting(CycleGAN)과 Unpaired setting(Pix2Pix)에 대해 GAN으로 푸는 시도가 있었다. 그러나, GAN 특유의 적은 diversity 때문에 학습된 도메인에서만 유효했고, generalize가 잘 되지는 않았었음.
- Diffusion Model이 발전하고 난 뒤로는 Stable Diffusion을 이것저것 만져서 Image Editing task에 적용하는 시도들이 많아졌다. Edit Signal의 modality도 다양해져서, prompt based editing (Instructpix2pix), 3D-aware Editing (Diffusion Handles) 등의 예시가 있다. Drag Editing은 InstantDrag와 같은 문제를 풀고 있으므로, 아래 섹션에서 다룰 것
2.2. Drag-based Image Editing
- DragGAN이 이 분야에서 pioneering한 work이고, 이후에 DragDiffusion, DragonDiffusion, Readout Guidance, SDE-Drag 등 많은 연구들이 나왔다. 최근에는 ByteDance(틱톡)에서 우리와 비슷하게 빠른 Drag Editing을 타겟한 LightningDrag도 있다.
- 우선 'Drag"라는 새로운 형태의 edit signal을 {source point, target point}의 sequence로 정의했다. StyleGAN의 latent space (w space)를 활용하여, 이미지가 생성된 latent vector w가 있을 때 Drag Editing에 맞게 latent space를 조작한다. 조작하는 방법으로 1) Point tracking과 2) Motion Supervision을 제안하고, 이 2가지를 반복적으로 수행한다.
- DragDiffusion은 사실 방법론 자체는 DragGAN과 같다고 해도 무방하다. 다만 웹 스케일, LAION으로 학습된 Stable Diffusion의 엄청난 capability를 활용하여 성공적으로 다양한 도메인의 Drag Editing을 가능하게 하는 프레임워크를 제시했다.
- 그 이외에도, guidance 기반의 시도들도 있었다. 2개의 diffusion model을 활용하여 guidance를 주는 DragonDiffusion, 가벼운 Readout Head를 plug-and-play 방식으로 활용하여 classifier guidance처럼 noise를 gradient 방향으로 guidance하는 Readout guidance 등이 있었다.
- 선행 연구들은 명확한 단점이 있는데, 첫 번째로 LoRA, latent optimization, Diffusion Inversion 등을 사용하기 때문에 추론 시간이 오래 걸리게 된다. Text-to-Image Generation 분야는 Consistency Distillation 과 더 좋은 Sampler 사용 등으로 요즘에는 적으면 1초, 오래 걸려도 5초면 우리가 원하는 이미지를 생성할 수 있다. 그러나 Drag Editing 연구들은 LoRA 학습, latent optimization, Inversion 등 Edit을 "준비하는" 시간에 상당한 시간을 소요하게 된다. 그래서 가장 적은 시간이 걸리는 모델도 12초 정도가 걸리고, 심한 경우 1분이 넘어가게 되기도 한다.
- 두 번째로 지금까지의 work은 real image를 편집할 때 DDIM inversion을 사용하는데, 이 inversion에 대한 bottleneck이 심하다. (사실 다른 inversion을 사용하더라도, reverse process를 수행하기 전의 latent를 찾는 inversion task가 아직 완벽한 방법이 존재하지 않음. 특히, high-frequency feature를 잃는 문제가 두드러지게 나타남.)
- 이러한 문제를 해결하기 위해서, InstantDrag에서는 pipeline을 간소화하는 대신, Inversion, LoRA 학습 등을 필요로 하지 않게 하기 위해서 모델을 fine-tuning하였다.
- 학습을 하려면 적절한 supervision을 찾는 것이 가장 중요한 요소이다. 그러나 {Image, Drag, Edited Image}처럼 깨끗한 세팅을 찾는 건 쉽지 않다. 그래서 우리는 Large scale Video dataset에서 다양한 모션을 배울 수 있다는 점에 착안하여 비디오 데이터를 전처리하여 우리의 framework를 학습시킬 수 있는 데이터로 만들었다.
3. Method
3.1. Model Architecture

- InstantDrag는 크게 Sparse Drag Instruction을 Dense Optical Flow로 변환하는 FlowGen, Optical Flow를 condition으로 Edit된 이미지를 생성하는 FlowDiffusion 2가지로 나뉜다.
- Drag Editing 문제를 2가지 subproblem으로 나누어 풀어서, 각 모델들이 각자의 task에 집중할 수 있도록 한 것이 novelty 중 하나이다. 그리고, GAN과 Diffusion Model을 각각 1개씩 사용했다는 것도 재밌는 점 중 하나이다.
FlowGen
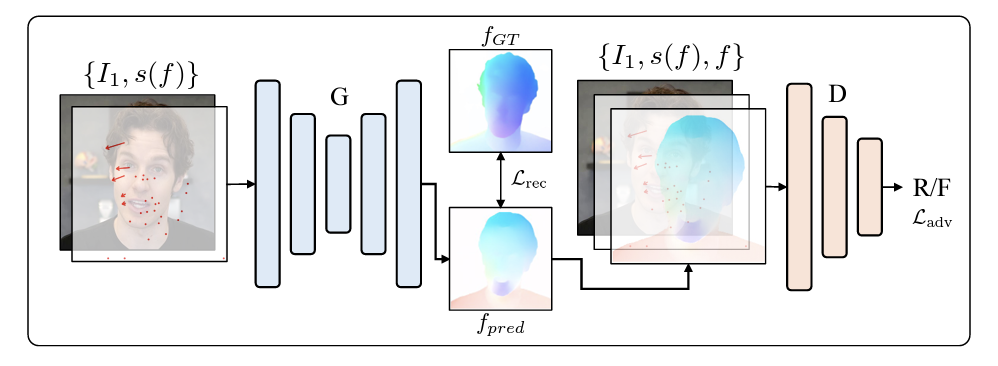
- Drag Instruction을 Optical Flow로 변환해주는 모델로, GAN으로 디자인하였다.
- 5채널 input (Input image, Drag Instruction)을 받아 2채널 output (Optical Flow)을 출력한다.
- Image-to-image Translation 모델인 Pix2pix의 architecture을 차용하였고, Batch Normalization을 Group Normalization으로 바꾸었다.
- PatchGAN 기반의 Discriminator을 사용했고, Drag Instruction은 GT optical flow로부터 point를 랜덤하게 샘플하여 학습에 사용했다. (즉, Input image와 sparse한 Drag Instruction을 input으로 받아, 이를 완전히 dense한 Optical Flow로 변환하는 문제를 푸는 것과 같다.)
- Pix2pix에서 사용했던 것처럼, 2가지 loss를 결합하여 사용하였다: GAN의 고전적인 Adversarial Loss, GT와의 pixel level L1 loss.
FlowDiffusion
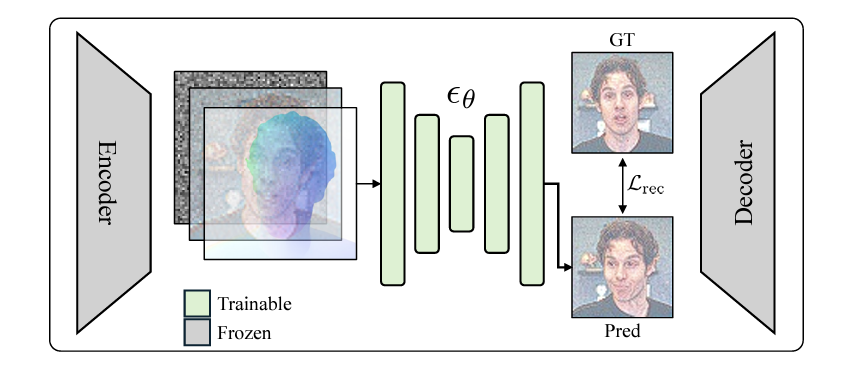
- FlowDiffusion은 FlowGen이 생성한 Optical FLow을 기반으로 실제 이미지를 편집하는 Diffusion Model이다.
- FlowDiffusion은 Stable Diffusion의 architecture을 차용했기 때문에 U-Net 구조로 이루어져 있다.
- input을 10채널로 구성했다. (Image를 VAE Encoder로 인코딩한 latent image, 현재 timestep에서의 latent noise , Optical Flow) 이 input과 timestep을 받아 다음 timestep의 latent 을 예측한다.
- Optical Flow와 Original Image에 대해 CFG (Classfier-Free Guidance)를 적용하였고, 이를 적용하기 위해 학습 과정에서 unconditional term을 학습하기 위해 random하게 condition을 drop하는 과정을 거친다.
3.2. Implementation Detail
- Drag Editing을 supervise할 수 있는 데이터셋이 없다는 어려움이 있었고, 이를 비디오 데이터로부터 획득하고자 했다.
- 영상을 프레임 단위로 샘플랑하여 사용했다. 한 비디오에서 랜덤하게 두 프레임을 선택하여 추출하면, Original Image와 Edited Image로 사용할 수 있다. 그리고, 두 이미지 간의 Optical Flow도 추출하여 사용할 수 있다.
- Facial Text-Video 데이터셋인 CelebV-Text, FlyingChairs, Sintel과 같은 Optical Flow 데이터셋을 활용했다.
- 매우 큰 용량의 데이터셋으로 학습한 만큼 Generalize가 어느 정도 잘 되는 것을 확인했지만, 특정 장면에 대해 성능을 더 높이기 위해 짧은 비디오 데이터셋으로 GAN과 Diffusion Model (LoRA)을 fitting하는 것도 가능하다.
- FlowGen에서는 한 점에 대한 Drag부터 수십 개의 점까지, 어떤 Drag Instruction을 받아도 Optical Flow를 만들 수 있어야 한다. 이를 위해, 학습 도중 여러 case에 대한 Drag Instruction을 샘플링할 수 있는 전략을 세워 학습하였다.
- FlowDiffusion의 경우, 드래그하고자 하는 구역 이외의 identity를 유지하는 것이 매우 중요하다. 하지만 비디오 데이터셋에서는 camera movement가 적지 않게 있었고, 이를 그대로 학습하게 되면 배경 일관성을 유지하기 어려울 수 있다. 이를 위해 학습 중에 각 frame들의 foreground mask를 추출하고, 이를 masking operation에 활용하여 배경이 고정되도록 학습했다. 이를 통해 editing 과정에서 원하는 부분만 drag instruction을 반영하여 움직이도록 하고, 나머지 부분은 움직이지 않게 하는 것이 가능하다.
- Optical Flow는 픽셀 단위의 움직임을 계산하기 때문에 범위가 매우 클 수 있다. FlowDiffusion의 안정적인 동작을 위해 Optical Flow를 -1~1 범위로 Normalization하여 학습 과정에서 학습했다.
4. Experiments
4.1. Settings
- 학습을 위해 CelebV-Text 데이터셋으로부터 800장의 pair를 추출했다.
- 22(12장의 facial, 10장의 general scene)장에 대해 user study를 진행했다.
- GT가 있는 벤치마크를 사용하기 위해 TalkingHeadKH 데이터셋으로부터 random하게 frame pair을 샘플링하여 evaluation에 활용하였다.
- Metric으로는 PSNR, SSIM, LPIPS, CLIP Image Similarity 등 perceptual metric을 활용했다. Drag Editing에서 자주 쓰는 Mean Distance를 사용하지 않은 이유는, 이것이 대응되는 pixel point의 거리에만 충실할 뿐 perceptual한 특성을 전혀 고려하지 않는 metric임을 실험적으로 확인했기 때문이다.
- FLowGen의 parameter는 54M, FlowDiffusion의 parameter는 860M, FlowGen은 256x256에서 Single GPU로 3일간 학습, FlowDiffusion은 512x512에서 8GPU로 약 5일간 학습
4.2. Qualitative Evaluation

- 비교 모델: DragGAN/Instructpix2pix, DragDiffusion, DragonDiffusion, SDE-Drag, Readout Guidance
- 원본 이미지의 appearance를 잘 유지하면서도, Drag Instruction에 맞는 edit을 잘 수행한다. 특히, 이미지 내에서 사람의 눈, 코, 입을 수정하는 부분은 fine detail을 필요로 하는데, 이런 부분에서 InstantDrag는 다른 모델들에 비해 강점을 가진다.
4.3. Quantitative Evaluation

- Input Requirements 비교
- Inference time, Memory consumption 측정 및 비교
- PSNR, SSIM, LPIPS, CLIP Image Similarity 측정 및 비교
- time과 memory의 경우 압도적인 강점을 갖는다. (다른 모델들은 12초 ~ 1분이 넘게 걸리던 걸, 1초만에 편집할 수 있다.)
- Perceptual Metric의 모든 지표에서 1,2위 성능을 달성했다.
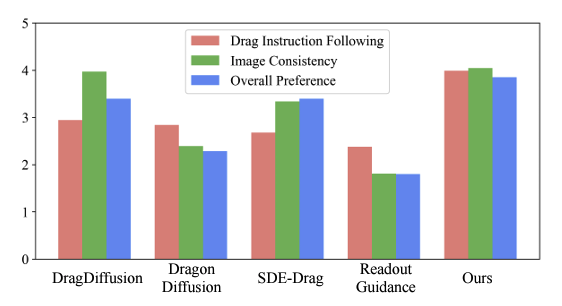
- Drag Instruction following, Image Consistency, Overall Preference를 조사했고 3가지 측면에서 1위를 달성했다.

Master Student @ KAIST CS / Generative Modeling