[논문리뷰] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis (ICLR’24)
[논문리뷰] Diffusion Model
목록 보기
1/2
Abstract


](https://velog.velcdn.com/images/choidaedae/post/e8f4756f-20cd-4530-8389-6725a1402429/image.png)
- Text-to-Image Synthesis를 수행하는 Latent Diffusion Model, SDXL 모델을 제안한다.
- SDXL 모델은 다음과 같은 novelty가 있다.
- 이름에서도 알 수 있듯 Stable Diffusion에 비해 3배가 커진 UNet (주로, attention block의 증가 때문에 발생한다.)
- Multiple novel conditioning (aspect conditioning, crop conditioning)과 Multiple aspect-ratio에 대한 하습
- Refinement Model: Image-to-image 방식으로 이전 UNet이 만든 이미지의 fidelity를 높이는 second UNet
1. Introduction
- SDXL은 이전 버전들과의 user study를 통한 비교실험에서 유의미한 차이를 갖고 가장 좋은 성능을 보여주었다.
- 본 technical report에서는 성능을 향상시킬 수 있었던 design choice들을 발표한다: 그 choice들은 다음과 같다.
- 3배 큰 UNet
- 단순하지만 강력한 2가지 conditioning techniques
- Diffusion 기반의 refinement model (noising-denosing 방식)
2. Improving Stable Diffusion
- Stable Diffusion architecture에서 개선된 점들을 이야기한다.
2.1. Architecture & Scale

- Jonathan Ho의 DDPM으로부터 착안되어 UNet 기반의 denoiser는 가장 지배적인 구조이고, self-attention과 upscaling layer을 개선하고, text-to-image synthesis task에서 text embedding과의 cross attention을 추가하여 발전해왔다.
- 이 구조에 더해서 UNet을 lower-level feature에서 attention 연산을 추가했다. (Simple Diffusion 논문을 인용)
- 또한, 효율성 측면에서 highest UNet에서의 attention block을 제거했고, x8 downsampling을 하지 않는다. (x4 까지만)
- text conditioning 을 강화하기 위해서, 더 powerful한 text encoder(OpenCLIP ViT-bigG)를 기존의 text encoder(CLIP ViT-L)에 추가한다. 이는 다른 두 모델에서 나온 embedding을 channel-wise로 concat하는 방식으로 수행된다. 또한, OpenCLIP ViT-bigG에서는 pooled embedding을 수행한다.
2.2. Micro-conditioning
Conditioning the Model on Image Size
- LDM에서는 2-stage training(VAE-UNet) 때문에 Minimal Image size에 제약이 있다. (실제로 stable diffusion에서는 256x256 이미지를 VAE가 64x64로 downsampling하고, UNet이 x8 downsampling하므로 8x8까지 latent가 축소된다.)
- 이 문제를 해결하려는 2가지 시도가 있다:
- minimal resolution을 넘지 못하는 이미지는 모든 training image를 버린다. (예를 들어, SD1.5에서는 512 pixel보다 작은 이미지는 모두 버린다.) -> 이렇게 되면 데이터의 적지 않은 비중을 버리게 되는데, 성능과 generalization 측면에서 좋지 않다.
- 데이터를 무작정 사용할 수 있는 resolution으로 upsampling해서 모두 사용한다. -> 이렇게 되면 model의 sample에서 upscaling artifact들이 나타날 수 있다. (쉽게 말해, blurry sample)
-
이 대신, SDXL에서는 버리는 이미지 없이 이미지를 upsampling해서 학습에 사용하지만, UNet model에 original image resolution에 대한 condition을 주는 방법을 택한다.
-
더 자세히는, 모델에 을 conditioning한다. 각 component는 fourier feature encoding을 통해 임베딩되고, 이 encoding들은 하나의 single vector로 concat된 뒤 timestep embedding에 더해진다.
-
Inference 때는 사용자가 이 size conditioning을 통해 원하는 apparent resolution을 지정할 수 있다.
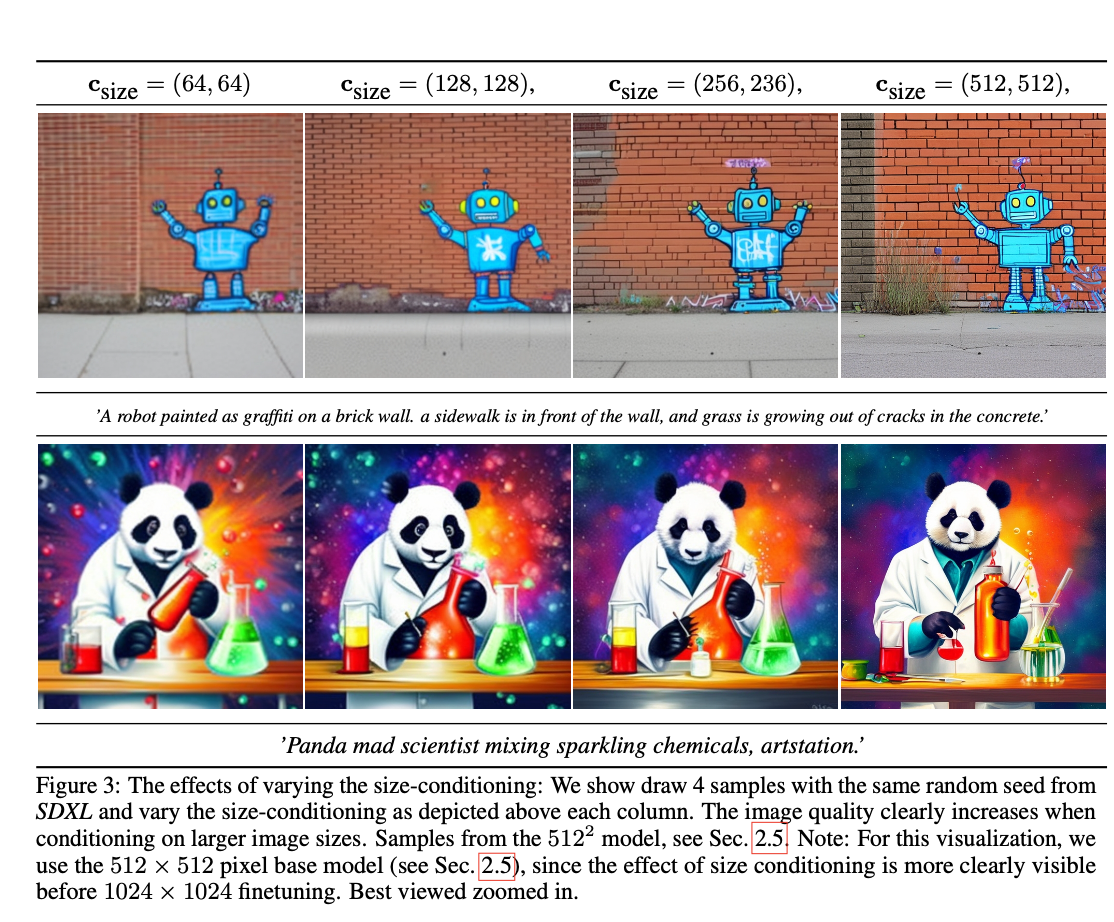
-
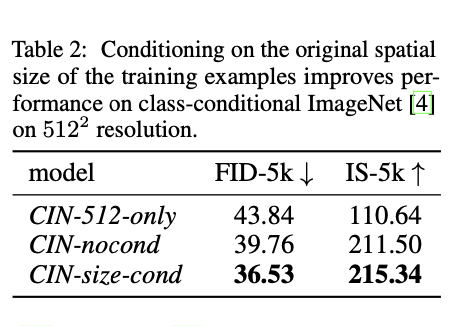
해당 conditioning에 대해 실험을 해 보았는데, 512-512 이미지를 학습하는 모델을 학습하면서 1) embedding을 항상 512-512로 줌. 2) embedding을 주지 않음. 3) size conditioning을 넣어줌. 등의 3가지 다른 세팅으로 모델을 학습한 뒤 결과를 측정하였을 때 적절한 size conditioning을 넣어주는 것이 FID, IS 측면에서 가장 좋았다.
Conditioning the Model on Cropping Parameters
- 기존 SD1.5, SD2.1에서의 failure case 중 하나로 생성된 이미지 속 object가 잘리는 것이 있었다. 이것은 전형적인 processing 방식: i) target size과 근접하게 resize함. ii) 더 긴 쪽을 random crop함. 때문에 기인한다. 즉, 학습할 때 random cropping된 이미지를 보고 학습하기 때문에 inference 때도 잘린 이미지가 생성되는 경우가 생긴다.

- 이를 극복하기 위해 crop을 할 때 '어떤 좌표로 cropping을 했는지'를 model에게 conditioning하는 방식을 제안한다. 앞서 제시했던 것처럼 conditioning은 형태로 처리되며 (생각해 보면, 두 좌표만 주어지면 crop을 완전히 정의할 수 있다.) 이를 Fourier feature embedding하여 size conditioning의 embedding과 channel-wise로 concat한다.

2.3. Multi-Aspect Training
- Real-world 데이터셋은 다양한 크기와 aspect-ratio (종횡비)에 분포되어 있다. 그러나, text-to-image 모델들의 output resolution은 512x512나 1024x1024 등 고정된 정사각형 이미지인 경우가 많고, 이는 부자연스러운 선택이다.
- 이에 영향을 받아, multiple aspect-ratio을 처리할 수 있도록 모델을 fine-tuning한다.
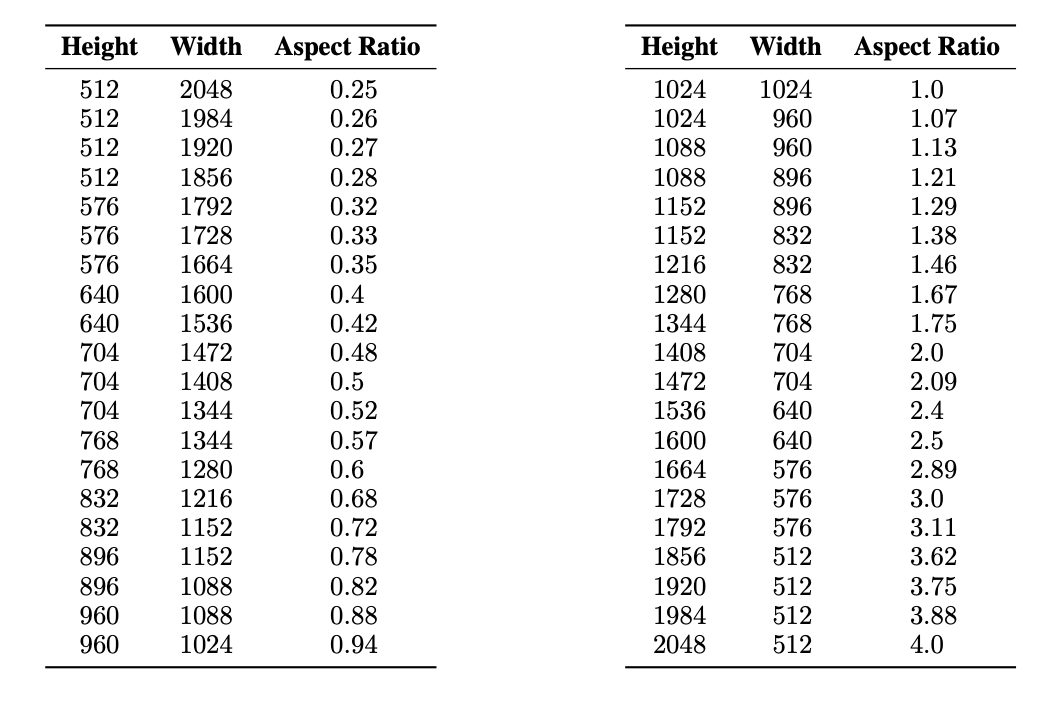
- 이전의 시도들처럼 데이터를 aspect ratio를 기준으로 나눈 bucket에 partitioning한다.
- pixel의 수는 1024x1024에 근접하도록 각 bucket을 유지하였다.
2.4. Improved Autoencoder
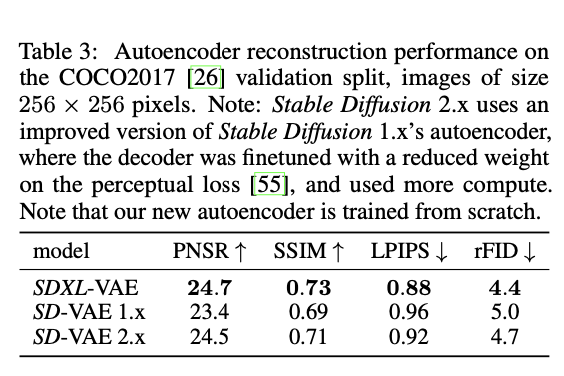
- SD를 비롯한 Latent Diffusion Model들은 latent space 상에서 denoising을 수행하는데, Autoencoder는 Image->latent의 Semantic한 composition을 가능하게 한다.
- Autoencoder을 개선했고, 이를 통해
- 모델 구조는 변하지 않았고, batch size를 늘려 (9->256)으로 학습하고, EMA로 학습하였다.
2.5. Putting Everything Together
- 위의 방법론들을 모두 적용하여 SDXL을 학습하였다.
- discrete time diffusion schedule, T = 1000
- 3 stage로 학습.
- size conditioning과 crop conditioning 사용, 모든 데이터셋을 사용 (256x256으로 resize & crop), batch size=2048, 600,000 steps
- 같은 방법으로 512x512, 200,000 steps 학습
- Multi-aspect training, offset noise=0.05로 주고 학습
Refinement Stage
- 실험적으로, 위 stage를 거쳐 학습된 SDXL이 local quality가 부족한 경우가 가끔 발생함.
- sample quality를 높이기 위해 별도의 LDM (refinement model)을 학습함.
- 이 refinement model은 high quality, high resolution 데이터에 특화되어있고, 생성된 이미지를 input으로 받아 SDEdit에서 제안된 방법인 noising-denoising으로 refine
- 이를 통해 배경의 디테일, 사람 얼굴 등에서 성능 개선.

Appendix
- 정량적인 실험이 많진 않고, 대부분의 실험 결과가 기존 SD 또는 Midjourney와의 비교에 대한 user study임. (자세한 것은 논문을 참고)
- SDXL + Refinement model > SDXL > SD1.5 > SD2.1 순서로 user preference 기록
- Midjourney에서도 여러 유형의 프롬프트에 대해 상대적으로 더 많은 user preference를 기록
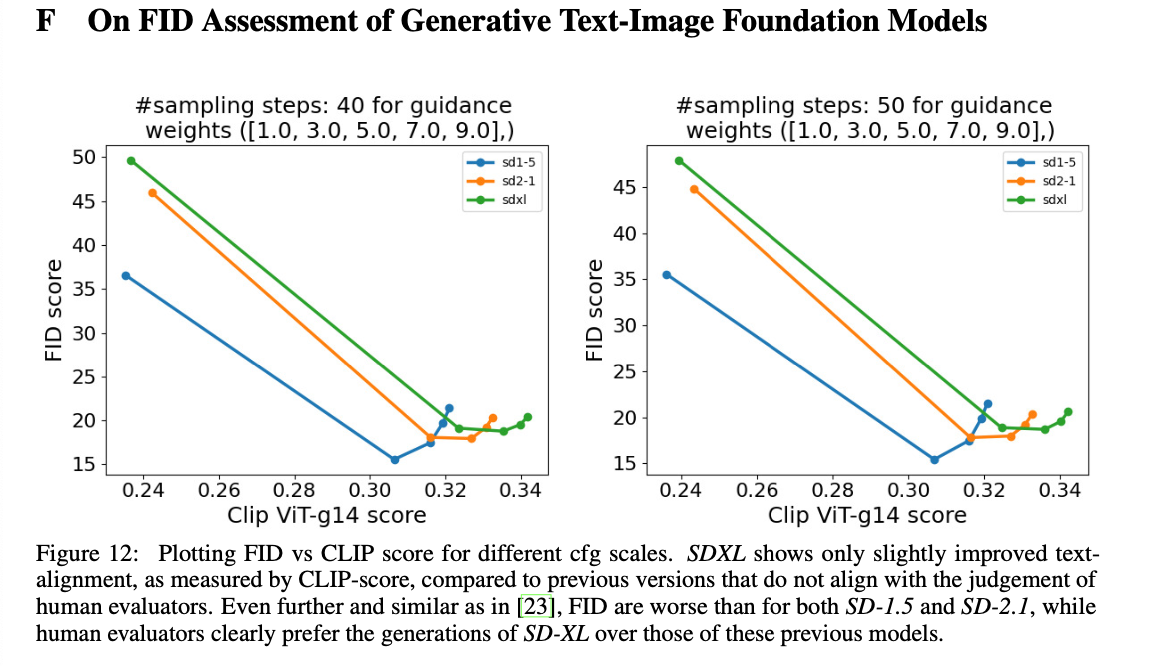
- CFG scale과 FID, Clip score에 대한 실험.
- COCO zero shot FID를 측정
- User study에서 SD를 유의미한 차이로 이겼음에도, SD의 전반적인 FID가 더 나음.

Master Student @ KAIST CS / Generative Modeling