
💾 낯가림이 심한 데이터베이스
웹 상에는 수 없이 많은 웹 서비스가 24시간 다양한 곳에서 운영되고 있습니다.
A 서비스는 하루에 사용자가 10명 남짓한 반면 대중적인 B 서비스는 하루에도 수 천명이 집 드나들듯 접속합니다.
그럼 두 서비스에 대한 DB 설계를 완전히 동일하게 하면 될까요?
정답은 아닙니다. ❌
서비스를 설계함에 있어 데이터베이스 설계 부분은 개발자에게는 쉽지 않은 일입니다. 서비스의 성격을 잘 고려해서 어떤 데이터베이스를 써야 할까? Cache 서버는 필요할까? 향후 유지보수를 위해 어떤식으로 진행해야 할까? 등 개발자는 데이터베이스에 많은 시간과 노력을 쏟아 부어야합니다.
그렇지 않으면 서비스 운영시 데이터가 손실되기도 하며, 심지어는 부하가 심해 모든 데이터베이스의 내용이 날라가기도 합니다. 😱
동시 이용자가 많지 않다면 서버 프로그램을 통해 DB 접근을 하는 횟수가 많지 않아 DB 부하가 심하지 않지만, 많은 이용자가 DB에 동시 접근을 한다면 DB 가 견디기 힘들어 하겠죠?
🧑🏼💻 " 해당 서비스는 사용자가 많겠군... 일반적인 DB 설계로는 부족해 " (B 서비스 개발자 최군)
B 서비스를 설계하는 도중 최군은 이와 같이 생각을 했으며, 이때부터 Cache 서버에 도입을 적극적으로 검토하게 됩니다. (캐시 서버가 생소하시다면 캐시서버란? 을 참고해주세요.)
web server 와 DB 사이에 cache 서버를 도입하면 직접적으로 DB 에 데이터를 요청하는 것 보다 더 빠른 속도로 DB에 부하를 줄이면서 DB 작업이 가능해졌습니다.
자 이제 B 서비스 개발자 최군은 고민합니다. 캐시 서버를 어떤 식으로 구현할까?
👨💻 " Redis 사용하면 되지! " (지나가던 개발자 김군)
그렇습니다 이번 글에 핵심 소재인 Redis 를 사용하여 캐시 서버를 구현 할 수 있습니다.
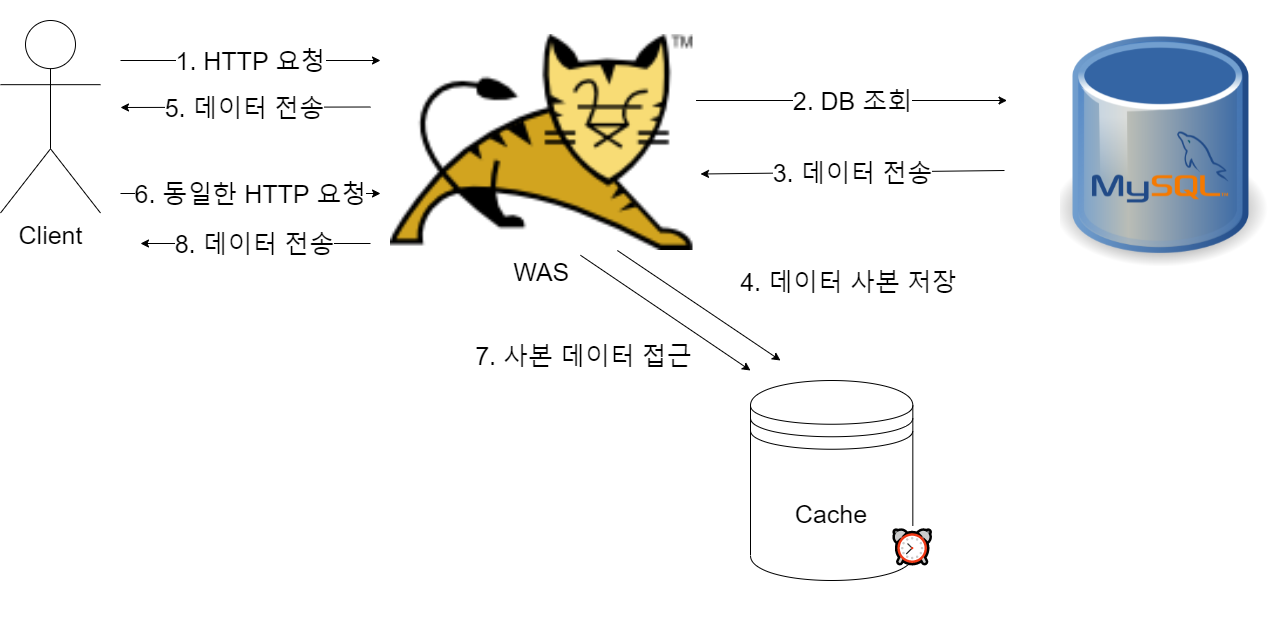
해당 이미지에서 Cache 가 Redis 라고 생각하시면 됩니다💡
💾 Redis(Remote Dictionary Server) 란?
아래는 Redis의 정의입니다.
(Remote Dictionary Server) is an in-memory data structure store, used as a distributed, in-memory key–value database, cache and message broker, with optional durability.
(출처 :https://en.wikipedia.org/wiki/Redis)
간단히 말하면, Redis는 키-값 기반의 In Memory 데이터 저장소입니다.
키-값 기반이기에 따로 쿼리를 작성할 필요없이 결과를 바로 가져올 수 있습니다.
또한 Physical Memory(디스크)에 데이터를 쓰는 구조가 아니라 메모리에서 처리하기 때문에 속도가 상당히 빠릅니다. 또한 일반적인 인메모리 DB 방식과는 다르게 영속성을 보장 할 수 있습니다.
추가적으로 Sigle Thread 로 작동하기 때문에 한 번에 하나의 명령만 처리할 수 있습니다.
Single Thread 라면 느리다고 생각할 수 있겠지만 Redis는 get,set 명령어의 경우 초당 10만 개 이상 처리 할 수 있을 만큼 굉장히 빠르기 때문에 트랜잭션의 ACID 특징을 지키면서 명령을 수행 할 수 있습니다.
트랜잭션에 대한 개념이 생소하시다면 트랜잭션이란? 을 참조바랍니다.😎
🌍 Redis 특징
- key-value 형식의 비관계형 데이터베이스
- In Memory 데이터 베이스
- In Memory 데이터 베이스이지만, 데이터의 영속성을 보장 가능
(RDBMS 만큼의 정합성과 영속성 보장은 ❌ ) - 싱글 쓰레드 방식으로 동작
💾 Redis의 영속성
일반적인 인메모리(In-Memory) 데이터베이스는 휘발성이기에 Application이 종료되면 모든 데이터가 날라갑니다.
하지만 Redis 는 인메모리 데이터베이스임에도 불구하고 영속성을 보장할 수 있습니다.
즉, Redis 을 사용하는 Application이 종료되어도 기존에 저장된 데이터는 날라가지 않는 특성 즉 비휘발성을 보장합니다. 어떻게 가능할까요? Redis 가 영속성을 보장하는 원리에는 2가지 방법이 있습니다.
1. RDB(Snapshotting) 방식
RDB(Snapshotting) 은 이름에서 알 수 있듯이 주기적으로 디스크 기반에 데이터베이스에 접근하여 Redis 의 상태를 옮겨서 저장하는 방식입니다.
디스크 기반에 데이터베이스는 영속성을 보장하기 때문에 Redis 데이터들의 영속성을 보장할 수 있습니다❗️
하지만 해당 방식은 Redis 의 데이터를 옮기는 동안 Redis 가 Blocking 될 수 있으며, 데이터의 손실 가능성이 존재합니다.
2. AOF 방식
AOF(Append-Only File) 방식은 Redis 에 작용하는 모든 Write/Update 연산을 별도의 로그 파일에 기록하는 방식입니다. 이후 Application 이 종료된 후 다시 구동될때 해당 로그 파일을 참조하여 Redis 데이터를 복구 할 수 있습니다.
하지만 해당 방식은 로그 파일을 복구하는데 시간이 걸리며 로그 파일이 계속 커지면서 많은 공간을 차지할 수 있습니다.
일반적으로 두가지 방식을 혼합해서 사용합니다.
주기적으로 RDB(Snapshotting) 방식을 사용해서 디스크 기반에 데이터베이스에 기록하며
그 외에는 AOF 방식을 이용해서 로그 파일에 기록합니다❗️
ex) 매일 새벽 3시마다 RDB 스냅셧을 생성하고, RDB 생성 이후에 변경되는 데이터는 AOF이용해서 백업
💾 Redis의 SingleThread
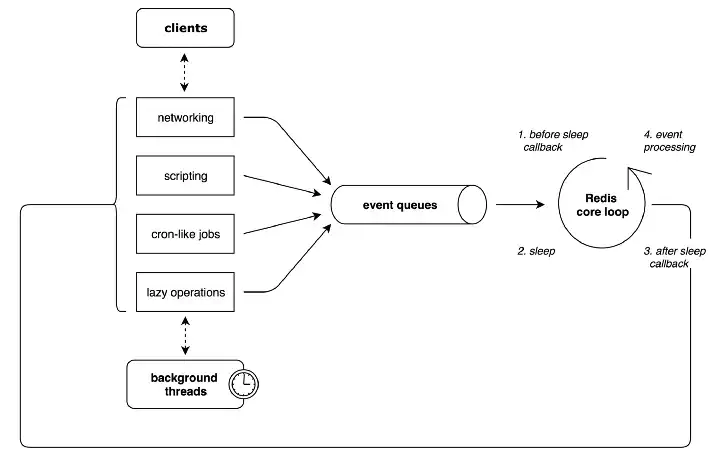
레디스는 Single Thread 방식으로 동작합니다.
사용자들의 실행으로 인해 Redis 서버로 들어오는 요청을 이벤트 루프(Event Loop) 방식으로 처리합니다.
간단하게 이야기 하면 들어온 요청을 이벤트 큐(Event Queue) 에 적재하고 Single Thread 로 하나씩 처리합니다.
그렇다면 Single Thread 로 처리하는데 장점이 있을까요? 🤔
Multi Thread환경이 아니기 때문에Context Switching이 발생하지 않습니다 -> 효율적인 시스템 리소스 사용 가능- 이때문에
Deadlock현상이 발생하지 않습니다.
Deadlock 이란 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태을 말한다.
하지만 Single Thread 방식으로 인한 단점도 있습니다.
- 오버헤드가 큰 요청(ex 전체 데이터 조회) 을 처리하는 동안 다른 명령어는 블로킹된다. -> 응답 속도 저하
💾 Redis의 다양한 아키텍처
Single 모드
📣 가장 간단한 모드로, 하나의 서버 인스턴스로 작동하는 Redis라고 이해 하면 됩니다.
Cluster 모드
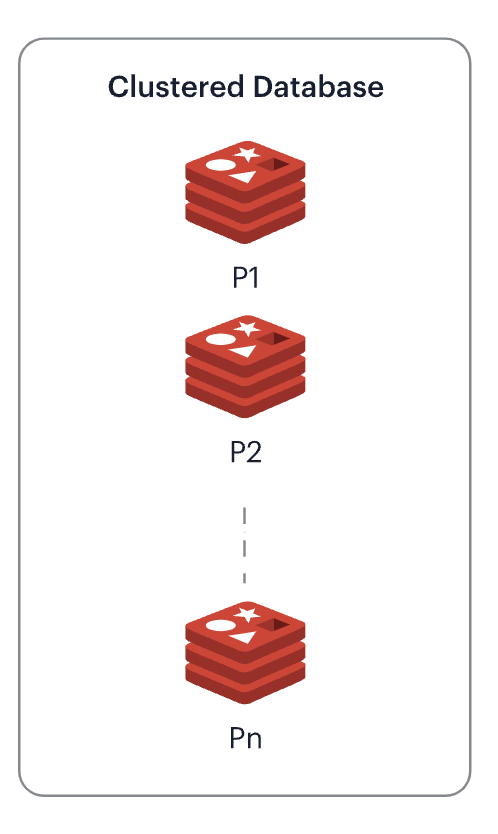
📣 여러개의 서버 인스턴스를 구축하고, 데이터 묶음을 여러개의 노드로 나누어 각 서버 인스턴스에 구성하는 모드입니다.

조금은 어려운 내용이지만 상단에 있는 이미지를 기반으로 Cluster 모드에 대해 간략히 소개하겠습니다.
이미지에는 총 3개의 서버 인스턴스가 존재합니다.
각 서버 인스턴스에는 각 3개의 노드가 존재하는군요!
파란색 노드를 Master 노드라고 하고, 흰색 노드를 Slave 노드라고 부르겠습니다. Slave 노드는 Master 노드의 복사본(Replication)으로써, 각각 서로 다른 서버 인스턴스에 존재합니다. 또한 Slave 노드는 읽기 작업만 가능한 노드라고 생각하면 되겠습니다. 👍
만약 1번 서버가 부하로 인해 다운된다면 어떻게 될까요? 🚨
이때 1번 서버 인스턴스의 Master 노드가 죽게 되고, Cluster 모드 정책에 의해 다른 서버에 존재하는 Slave 노드가 Master 노드로 승격하여 기존의 1번 서버의 Master 노드의 역할을 정상적으로 처리하게 됩니다.
Sentinal 모드
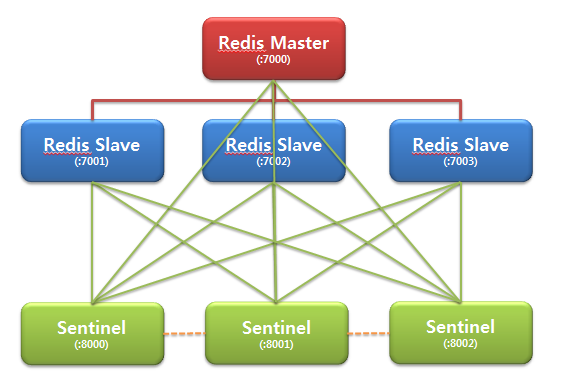
📣 Sentinal 모드는 Cluster 모드와 비슷하지만, 3가지 기능을 가지고 있습니다.
- 모니터링(Monitoring)
- 자동 장애 조치(Automatic Failover)
- 알림(Notification)
위에 이미지 처럼 Redis Master 노드가 각 Slave 노드가 잘 작동하는지 계속 감시하는 형태를 띄고 있습니다.
💡 기본적인 동작 방식-
Sentinal 인스턴스 과반 수 이상이 Master 장애를 감지하면 Slave 중 하나를 Master로 승격시키고 기존의 Master는 Slave로 강등시킵니다.
-
Slave가 여러개 있을 경우 Slave가 새로운 Master로부터 데이터를 받을 수 있도록 재구성 됩니다.
-
과반 수 이상으로 결정하는 이유는 만약 어느 sentinel이 단순히 네트워크 문제로 master와 연결되지 않을 수 있는데, 그 때 실제로 Master는 다운되지 않았으나 연결이 끊긴 sentinel은 Master가 다운되었다고 판단할 수 있기 때문입니다.
위와 같은 동작 방식으로 작동하며 과반수 원리로 문제 발생했다고 판단시,
자동으로 Failover 를 수행하며 이를 알립니다.
사실 Failover와 Notification 에 대한 내용이 추가적으로 있으나, 너무 깊은 내용이라 해당 글에서는 이 부분은 생략하도록 하겠습니다.
혹시 궁금하시다면 Redis 동작원리 를 참고해 주세요!.
📣 결론 : Cluster 모드를 사용하는 편이 확장성 측면에서 유리하기 때문에 Cluster 모드를 사용하도록 합시다!
💾 Redis 사용 용도
-
주 데이터 저장소:AOF,RDB백업 기능과 레디스 아키텍처를 사용해서 주 저장소로 데이터를 저장할 수 있습니다.
하지만 인메모리 특성상 대용량의 데이터를 저장하는데에는 적합하지 않습니다.
-
데이터 캐시: 인메모리 데이터베이스이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터를 읽을 수 있습니다.
여기서 캐시된 데이터는 한곳에 저장되는중장 집중형 구조로 구성하는게 좋습니다. -> 데이터 일관성 유지 가능
-
분산 락(distribution lock): 분산 환경에서 여러 시스템이 동시에 데이터를 처리 할 때는 특정 공유 자원의 사용 여부를 검증하여 Deadlock 방지할 필요가 있습니다.
-
메세지 큐: 최근 Redis 에서는Pub/Sub기능을 제공합니다. 따라서 메세지큐로 사용할 수 있습니다.
💡 참고
다음 단계 로 넘어가 볼까요? Redis에 대해 알아봅시다(실전 편) 이동하기 🚀🚀🚀
