
안녕하세요 오늘은 데이터베이스에서 중요한 개념인 인덱스에 대해서 배워보겠습니다 👨💻
📄 인덱스란?
오늘날의 데이터베이스는 중요한 역할을 하고 있으며, 나날히 발전하고 있습니다.
현재 데이터베이스의 성능적인 측면에서 가장 중요한 것은 속도입니다.
과거의 경우, 속도와 더불어 데이터베이스의 저장 용량 또한 중요했지만 컴퓨터 기술의 발전으로 저장 용량은 더이상 문제가 되지 않지만 좀 더 빠르게 효율적으로 데이터를 다룰 수 있는 데이터베이스의 속도 성능은 여전히 발전할 길이 많이 남아있습니다 🔥
이러한 속도 성능을 향상시키기 위해 인덱스(Index) 라는 데이터베이스에 특화된 자료구조가 탄생합니다 🐥
인덱스(Index) 란 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조입니다.
예를 들어 Member 라는 테이블을 하나 생성해봅시다
Create Table Member (
id BIGINT Primary key,
name VARCHAR(50) not null,
gender VARCHAR(2) not null,
age INT
)
수백개의 Member 데이터를 저장하고 특정 조건의 Member 데이터를 조회한다고 가정해봅시다!
인덱스 가 없다면 처음부터 마지막 데이터까지 모두 조회해야합니다.
이렇게 처음부터 끝까지 하나하나 조회하는 방식을 Full Scan 이라고 합니다 👨💻
하지만 데이터의 크기가 엄청난 용량을 차지하는 데이터베이스에 Full Scan 방식은 효율적이지 못한 방식입니다.
인덱스 를 통한 인덱싱 기술은 (데이터와 데이터의 대한 위치 정보) 를 포함한 자료구조 즉 인덱스 를 생성하여 빠르게 조회하도록 돕는 기술입니다.
여기서 데이터는 Key가 되며 데이터에 대한 위치 정보는 Value 로 설정합니다.
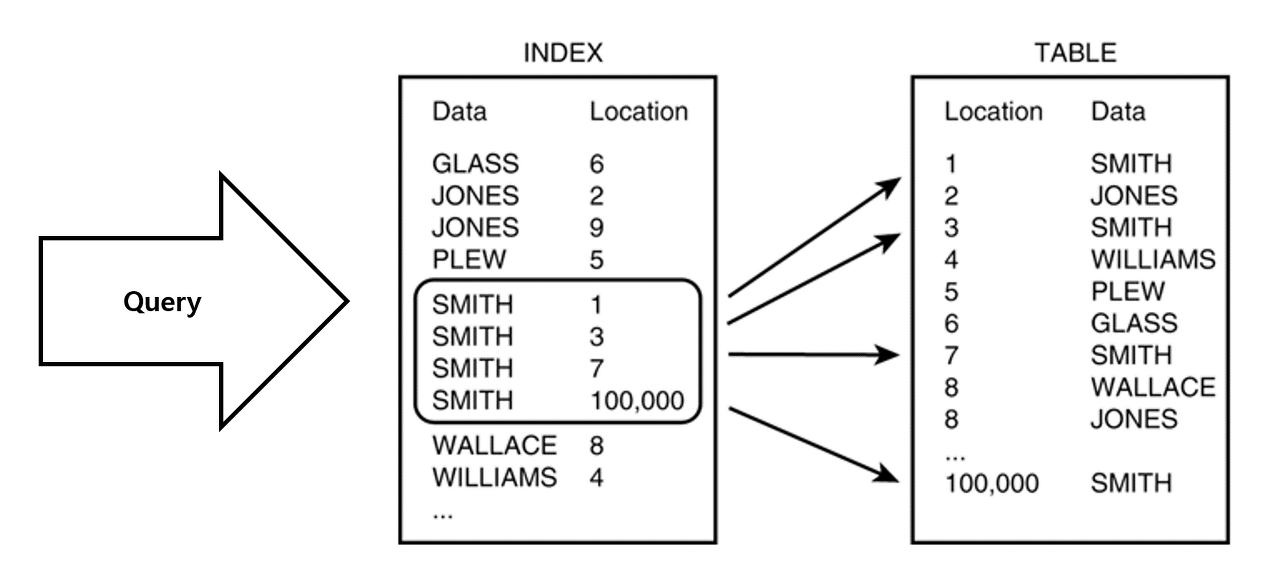
해당 이미지는 인덱스 구조를 이해할 수 있는 이미지입니다 🤓
INDEX 구조를 보시면 Data(Key) 로 데이터를 가지며 Location(Value) 로 해당 데이터의 위치를 가지는 것을 확인할 수 있습니다.
데이터베이스를 조회 하는 기능은 Select 외에도 Update, Delete 쿼리에도 사용합니다.
수정이나 삭제를 하려면 대상이 되는 데이터를 조회해야하기 때문이죠 🏋️♀️
인덱스 관리
DBMS 는 인덱스 를 항상 최신의 정렬된 상태로 유지해야 빠르게 원하는 값을 찾을 수 있습니다.
만약 CRUD 가 빈번히 일어나는 DB 라면 그만큼 인덱스를 관리하는 동작이 필요하며 그에 따른 오버헤드가 발생합니다.
- INSERT : 새로운 데이터에 따른 인덱스를 추가합니다.
- UPDATE : 수정하고자 하는 데이터에 인덱스를 사용하지 않음 처리하고, 새로운 인덱스를 추가합니다.
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않음 처리합니다.
인덱스 관리 방식에 대해서 눈에 띄는 점은 UPDATE, DELTE 연산은 해당 인덱스를 삭제하지 않고 사용하지 않음 처리함으로써 완전히 삭제하지 않는다는 점입니다 ❗️
인덱스 장점 & 단점
인덱스 구조를 이용한 데이터베이스 관리 방식은 다양한 장점이 있지만 단점 또한 존재합니다.
-
장점 :
1) 테이블을 조회하는 속도와 그에 관련된 성능을 향상시킬 수 있습니다.
2) 전반적인 데이터베이스 시스템의 부하를 줄일 수 있습니다. -
단점 :
1) 인덱스를 관리하기 위해 데이터베이스의 약 10% 해당하는 추가적인 저장공간이 필요합니다.
2) 인덱스를 관리하기 위한 추가 작업이 필요합니다.
3) 인덱스를 잘못 사용할 경우 전반적인 성능이 오히려 저하됩니다.
예를 들어 CREATE,UPDATE 그리고 DELETE 연산이 빈번하다면 인덱스의 크기는 엄청나게 비대해져서 성능이 오히려 저하되는 현상이 발생할 수 있습니다.
여기서 성능 저하를 일으키는 주된 연산은 UPDATE 와 DELETE 연산입니다.
앞에서도 알아보았듯이 기존 인덱스를 사용하지 않음 처리만 할 뿐 제거하지 않기 때문이죠 🤔
인덱스를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- CRUD 연산이 빈번하지 않는 테이블
- 데이터의 중복도가 낮은 테이블
- JOIN 이나 WHERE 또는 ORDER BY 연산이 자주 발생하는 테이블
이처럼 인덱스는 사용하는 것과 더불어 인덱스를 관리하는 측면에서 많은 노력이 들어갑니다 💪
만약 오랫동안 쓰이지 않은 인덱스는 바로 제거를 해주어야 인덱스의 성능에 따른 여러가지 이점을 더욱 얻을 수 있습니다.
인덱스 개념 정리
인덱스는 데이터 파일에 대한접근 경로(Access Path)라고 불립니다.인덱스는 <필드 값, 레코드에 대한 주소> 로 구성된엔트리를 저장한 파일입니다.인덱스를 구성하는 엔트리는 실제 데이터 파일의 레코드보다 크기가 훨씬 작기 때문에, 인덱스 파일은 데이터 파일보다 훨씬 적은 디스크 블록을 차지합니다.인덱스에 대한 이진탐색으로 데이터 파일의 해당 레코드에 대한 주소를 얻을 수 있습니다.
📄 인덱스의 종류
인덱스 에는 다양한 종류가 존재합니다.
같이 차근차근 알아보겠습니다 🧑🏼💻
밀집 인덱스 VS 희소 인덱스(비밀집 인덱스)
인덱스 를 구성하는 엔트리를 통해 우리가 찾고자 하는 데이터 파일의 레코드(데이터) 를 빠르게 찾을 수 있습니다.
이때 인덱스의 엔트리가 데이터 파일내의 탐색 키를 어떠한 방식으로 갖고 있냐에 따라 밀집 인덱스 와 희소 인덱스(비밀집 인덱스) 로 나뉩니다 🏋️
-
밀집 인덱스(Dense Index) :
데이터 파일내의 모든 탐색 키 값(모든 레코드)에 대한 인덱스 엔트리를 갖습니다.
-
희소 인덱스(Sparse Index) :
데이터 파일내의 일부 탐색 키 값에 대한 인덱스 엔트리를 갖습니다.
보통 인덱스를 종류를 구분할 때에는 크게 단일 단계 인덱스 와 다단계 인덱스 로 나뉩니다 🗂️
단일 단계 인덱스
단일 단계 인덱스는 다시 기본 인덱스, 클러스터링 인덱스 그리고 보조 인덱스 로 나뉩니다.
-
기본 인덱스
- 순서 파일에 대해 정의할 수 있는 인덱스입니다.
- 데이터 파일은 키 필드(Key Field) 순으로 정렬되어 있어야합니다.
- 데이터 파일의 각 블록에 대해 하나의 엔트리를 가지며,
블록 앵커(Block Anchor)라 불리는 각 블록의 첫 번째 레코드에 대한 필드 값을 엔트리로 가집니다. - 모든 키 값이 아니라 일부 키 값을 가리키는 인덱스 엔트리를 가지므로
희소 인덱스에 해당합니다.
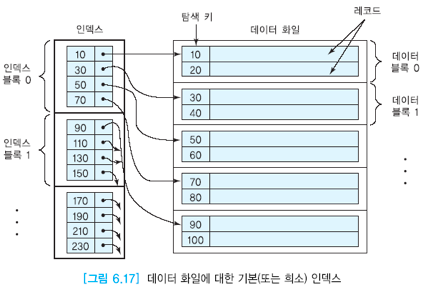
해당 이미지는
기본 인덱스의 구조를 나타내는 이미지입니다.
각 인덱스의 엔트리는 데이터 파일의 특정 블록의블록 앵커레코드만을 가리키고 있습니다.
또한 데이터 파일의 레코드들은 탐색 키값을 기준으로 오름차순으로 정렬되어 있는 것을 확인할 수 있습니다.
-
클러스터링 인덱스
-
순서 파일에 대해 정의할 수 있는 인덱스입니다.
-
데이터 파일은 각 레코드에 대해
구별된 값을 갖지 않은 필드(Non-Key Field)에 따라 정렬됩니다. -
해당 필드에 올 수 있는 각 값의 종류별로 하나의 인덱스 엔트리를 포함하여,
이 엔트리에는 그 필드 값을 가진 레코드들이 저장된 첫번째 블록에 대한 주소를 포함합니다. -
클러스터링 인덱스 또한 모든 데이터 파일의 레코드에 대한 엔트리를 갖지 않고 일부에 대한 엔트리를 가지므로
희소 인덱스에 해당합니다.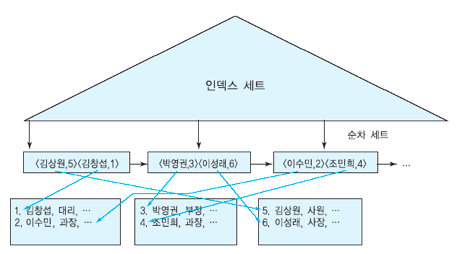
-
-
보조 인덱스
- 정렬되지 않는 파일에 대해 정의할 수 있는 인덱스입니다.
- 후보 키나 모든 레코드에 대해 유일한 값을 갖는 필드 혹은 중복된 값을 갖지 않는 필드에 대해 만들 수 있습니다.
- 두 개의 필드로 구성된 순서 파일입니다.(1.데이터 타입, 2.블록 포인터 or 레코드 포인터)
- 같은 파일에 여러개의 보조 인덱스가 존재할 수 있습니다.
- 모든 데이터 파일의 레코드에 대한 엔트리를 가지므로
밀집 인덱스에 해당합니다.
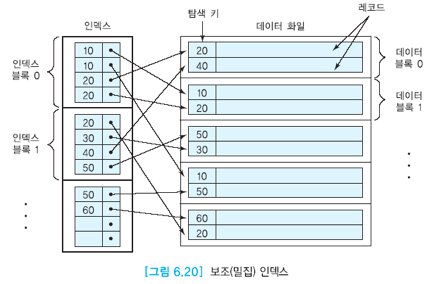
해당 이미지는 보조 인덱스 를 보여주는 이미지입니다.
데이터 파일의 레코드들이 정렬되지 않는 모습을 볼 수 있으며 모든 레코드에 대해 인덱스 엔트리를 갖는 것을 볼 수 있습니다.
다단계 인덱스
땨로는 인덱스 자체가 크다면 인덱스 자체를 탐색하는 시간도 오래 걸릴 수 있습니다.
이를 줄이기 위해, 단일 단계 인덱스 를 디스크 상의 하나의 순서 파일로 간주하고, 단일 단계 인덱스에 대해 다시 인덱스를 정의할 수 있습니다.
다단계 인덱스는 가장 상위 인덱스(마스터 인덱스) 에 모든 인덱스 엔트리들이 한 블록에 들어갈 수 있을때까지 과정을 반복합니다.
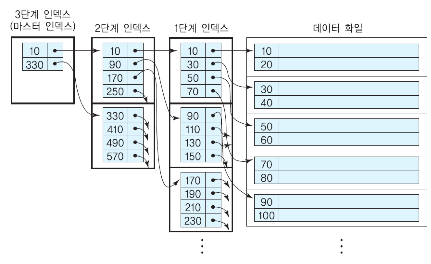
해당 이미지는 다단계 인덱스 를 나타내는 이미지입니다.
3단계 인덱스가 마스터 인덱스에 해당하며 모든 인덱스 엔트리를 포함합니다.
마스터 인덱스로 부터 추가적인 인덱스들을 생성해서 다단계 방식을 인덱스가 구성되는 것을 확인할 수 있습니다 ❗️
여기서 마스터 인덱스에는 단일 단계 인덱스의 어떤 유형이던지 올 수 있습니다.
다단계 인덱스 는 탐색 트리와 비슷한 형태를 갖습니다.
그러나 인덱스의 모든 단계가 각각의 순서 파일 이므로 새로운 인덱스 엔트리에 대한 삽입과 삭제가 매우 복잡하다는 단점이 있습니다 🤔
📄 인덱스의 자료구조
마지막으로 인덱스를 구성하는 자료구조에 대해 알아보겠습니다.
오늘날의 데이터베이스의 인덱스 자료구조는 B-Tree 혹은 B+Tree를 사용합니다.
이에 대해 구체적으로 알아보겠습니다 👨🔬
B-Tree 와 이진 트리
B-Tree 는 이진트리 에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 균형을 맞추는 균형 이진트리 의 확장판입니다 ❗️
이진트리 의 종류에 대해 간단하게 정리해보겠습니다.
정 이진트리: 트리의 모든 자식 노드의 갯수가 0 개 혹은 2개인 이진 트리 구조입니다.포화 이진트리: leaf 노드가 끝까지 정말 꽉 찬 이진 트리 구조입니다.완전 이진트리: 마지막 레벨을 제외한 모든 레벨에서 왼쪽부터 순서대로 노드가 꽉 채워진 이진 트리 구조입니다.균형 이진트리: leaf 노드드르이 레벨 차이가 최대 1차이가 나는 이진 트리 구조입니다.
사실 정 이진트리 , 포화 이진트리, 완전 이진트리 는 이상적인 경우인 트리 구조이기 때문에 잘 사용하지 않으며 균형 이진트리 가 다양한 목적으로 사용됩니다 👨💻
균형 이진트리 는 AVL 트리, 레드 블랙 트리, B- Tree 등이 있습니다.
우리가 알아볼 B-Tree 의 특징에 대해 알아보겠습니다.
B-Tree의 특징
B-Tree 는 이진 트리와 달리 하나의 노드에 많은 정보를 가지거나, 두개 이상의 자식을 가질 수도 있습니다❗️
그리고 그 규칙에 맞게 정해진 범위만큼의 키가 하나의 노드에 포함될 수 있습니다.
이렇게 하나의 노드에 여러 자료를 배치함으로써 기존의 이진 트리보다 훨씬 더 많은 데이터를 더 효율적으로 저장소에 담을 수 있게 되었습니다.
또한 B-Tree 는 앞에서 살펴본바와 같이 균형 이진트리 에 해당되므로 균형을 유지하여 최악의 경우 탐색 시간 복잡도가 O(logN) 의 성능을 보여줍니다.
하드디스크나 SSD와 같은 외부 기억장치는 Block 단위로 파일을 입출력합니다.
이때 하나의 Block 에 여러 데이터를 최대한 꽉 저장할 수 있다면 보다 효율적으로 외부 기억장치를 사용할 수 있을것입니다 💪 이러한 이유로 많은 DBMS에는 B-Tree 가 사용됩니다.
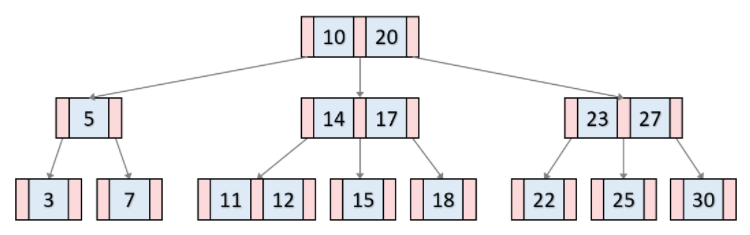
B-Tree 는 몇가지 특징을 가집니다.
- 노드에는 2개 이상의 데이터(Key) 가 들어갈 수 있으며, 항상 정렬된 상태로 저장됩니다.
- 내부 노드(리프 노드가 아닌 노드) 에는 M/2 ~ M개의 자식 노드를 가질 수 있습니다.
여기서 M은B-Tree에서 최대 가질 수 있는 자식의 갯수를 의미합니다. - 특정 노드의 데이터(Key) 가 K개라면 자식 노드의 개수는 K + 1개여야 합니다.
- 특정 노드의 왼쪽 서브 트리는 특정 노드의 Key 보다 작은 값들로, 오른쪽 서브 트리는 큰 값들로 구성됩니다.
- 노드 내에 데이터는 floor(M/2) - 1개부터 최대 M-1 개 까지 가질 수 있습니다.
(여기서 floor() 는 내림차순 함수를 의미) - 모든 리프 노드들은 같은 레벨에 존재합니다.
B-Tree 의 탐색/삽입/삭제 과정을 공부해보고 싶다면 [자료구조] B-트리(B-Tree)란? B트리 그림으로 쉽게 이해하기, B트리 탐색, 삽입, 삭제 과정 를 참고해주세요 🗂️
B+Tree
참고
[DB] 데이터베이스 인덱스(Index) 란 무엇인가?
[Data Base 인덱스란]
데이터베이스의 인덱스
[자료구조] B tree, B+ tree
B+ 트리 위키백과
