Categories of Machine Learning
Supervised learning
: from labeled data
Unsupervised learning
: from unlabeled data
➡️ Clustering ( 비슷한것 끼리 묶음 ), reproduction ( auto-encoder ), latent variable models ( hidden factor analysis )
Semi-supervised learning
: Small amount of labeled data + Large amount of unlabeled data
Reinforcement learning
: State, Action, Reward
➡️ Learn actions to maximize reward
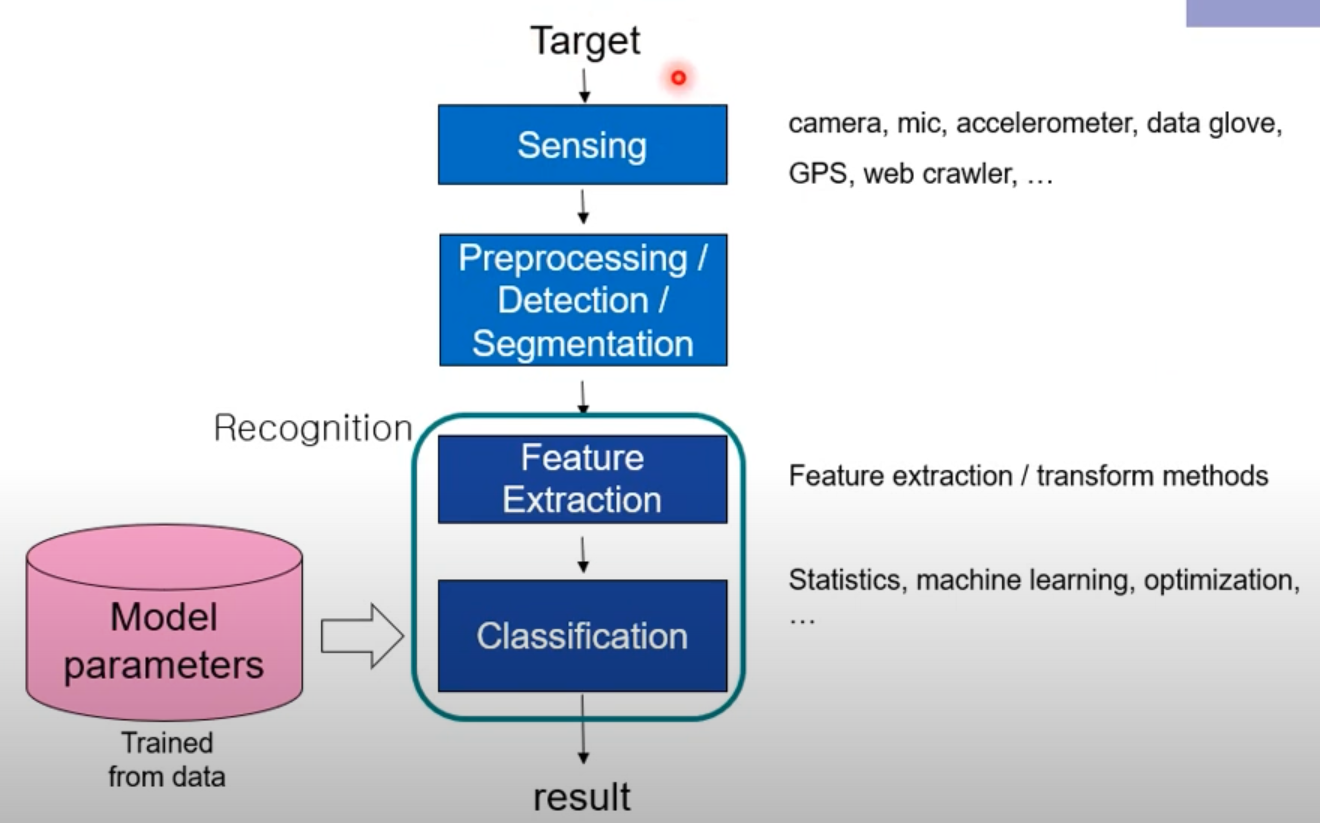
Recognition System
Overfitting
: 너무 복잡한 Model에 나타남 ➡️ 더 많은 Data로 충분한 학습 필요
: Training error decreases, but Test error increases
Bayesian Theorem

HGU - 개인 공부 기록용 블로그
감사합니다. 이런 정보를 나눠주셔서 좋아요.