
🖥️ Basic concepts
- Motivation: maximum CPU utilization(활용률) obtained(얻은) with multiprogramming and multitasking
- Resources (including CPU) are shared among processes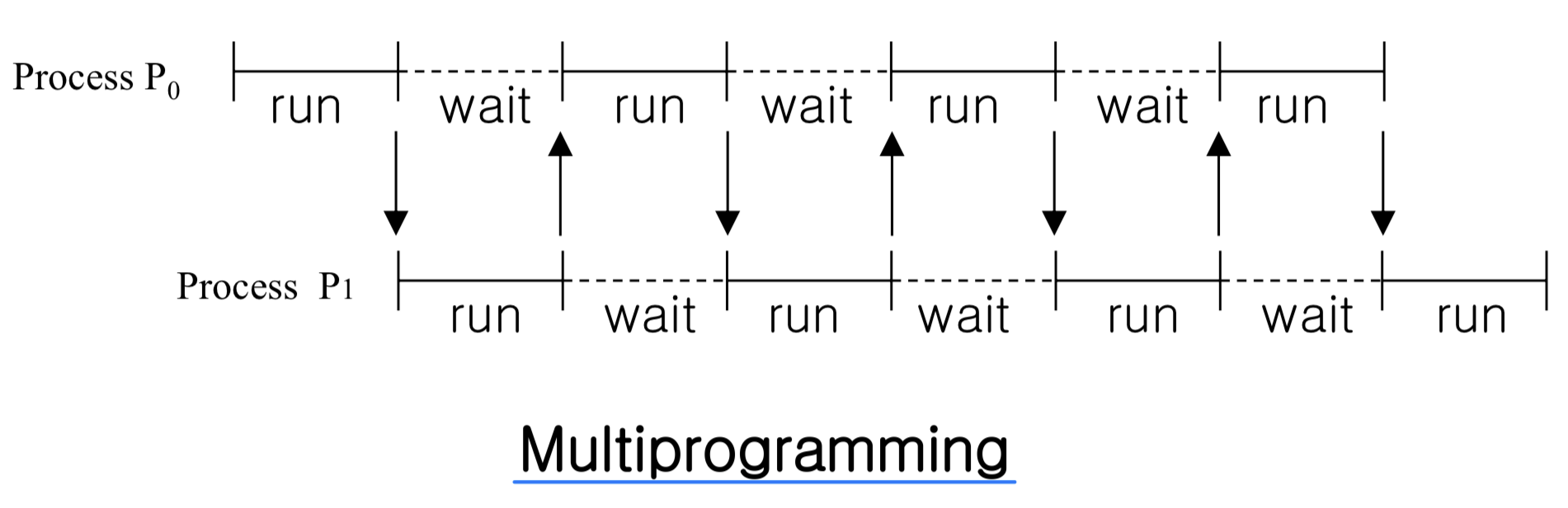
CPU-I/O Burst Cycle
- Process execution consists of cycle of CPU execution and I/O wait
- First and last bursts are CPU bursts - Types of processes
- I/O-bound process ( Ex_ Vi ... )
- Consists of many short CPU bursts - CPU-bound process ( Ex_ comprler ... )
- Consists of a few long CPU bursts - Ex_ CPU burst 100, I/O는? → 99
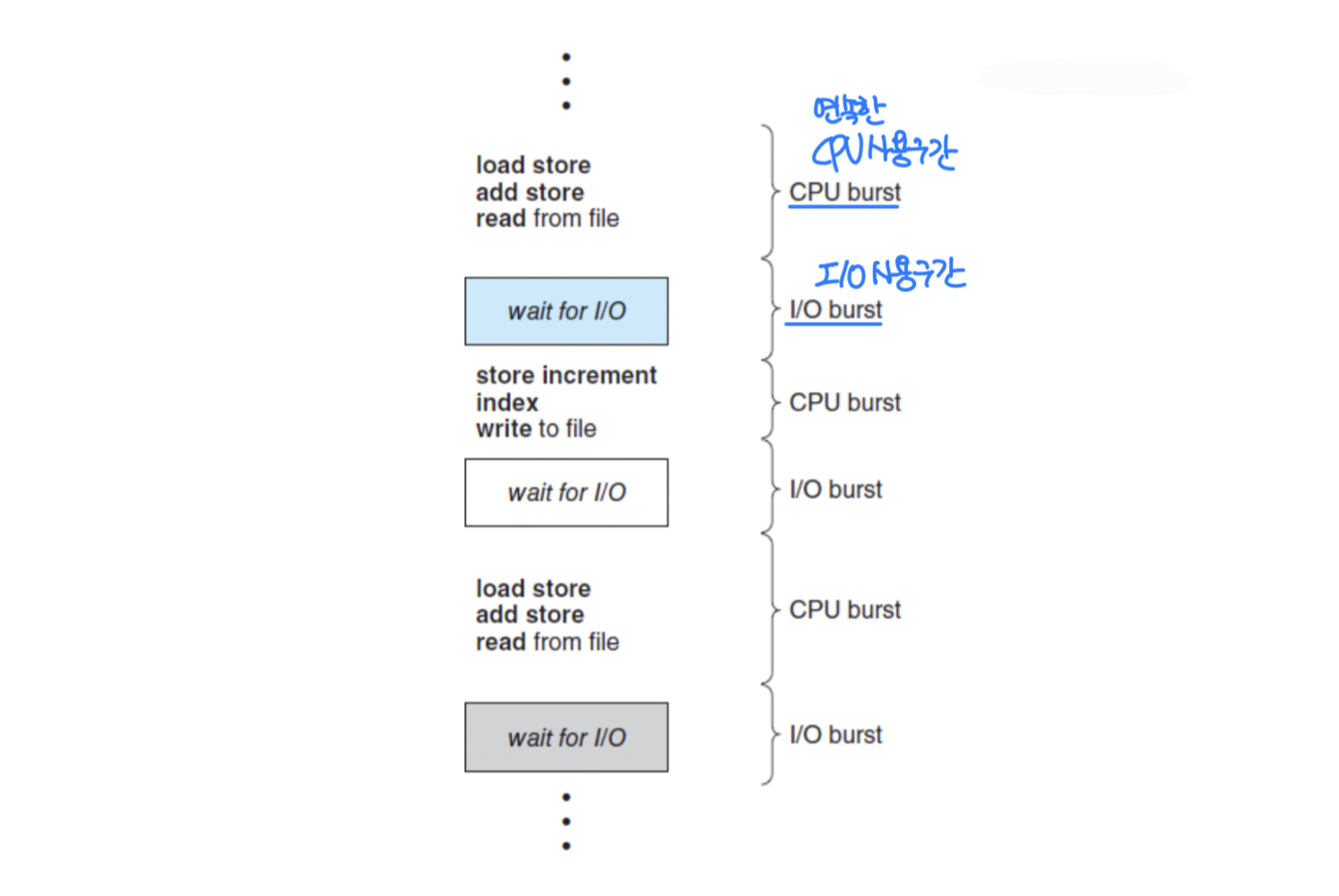
- I/O-bound process ( Ex_ Vi ... )
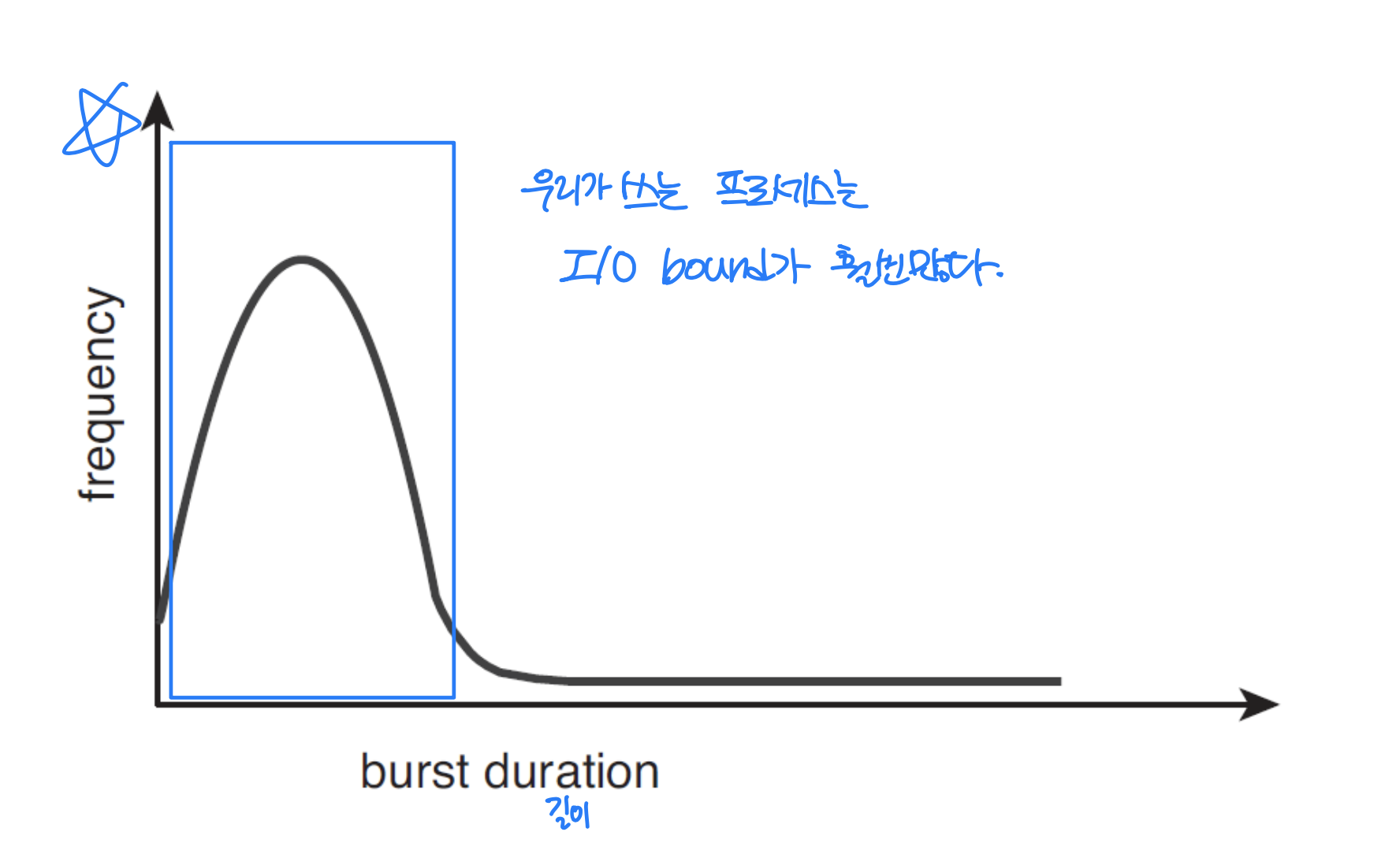
Histogram of CPU-burst Durations
- Exponential or hyper exponential
CPU Scheduler
- CPU scheduler (= short term scheduler)
- Selects a process from ready queue and allocate CPU to it - Implementation of ready queue
- FIFO, priority queue, tree, unordered linked list- Each process is represented by PCB

- Each process is represented by PCB
Preemptive scheduling
- Preemptive scheduling: scheduling may occur while a process is running
→ 실행중에 강제 스위칭을 할 수 있다.
Ex) interrupt, process with higher priority
When Scheduling Occurs?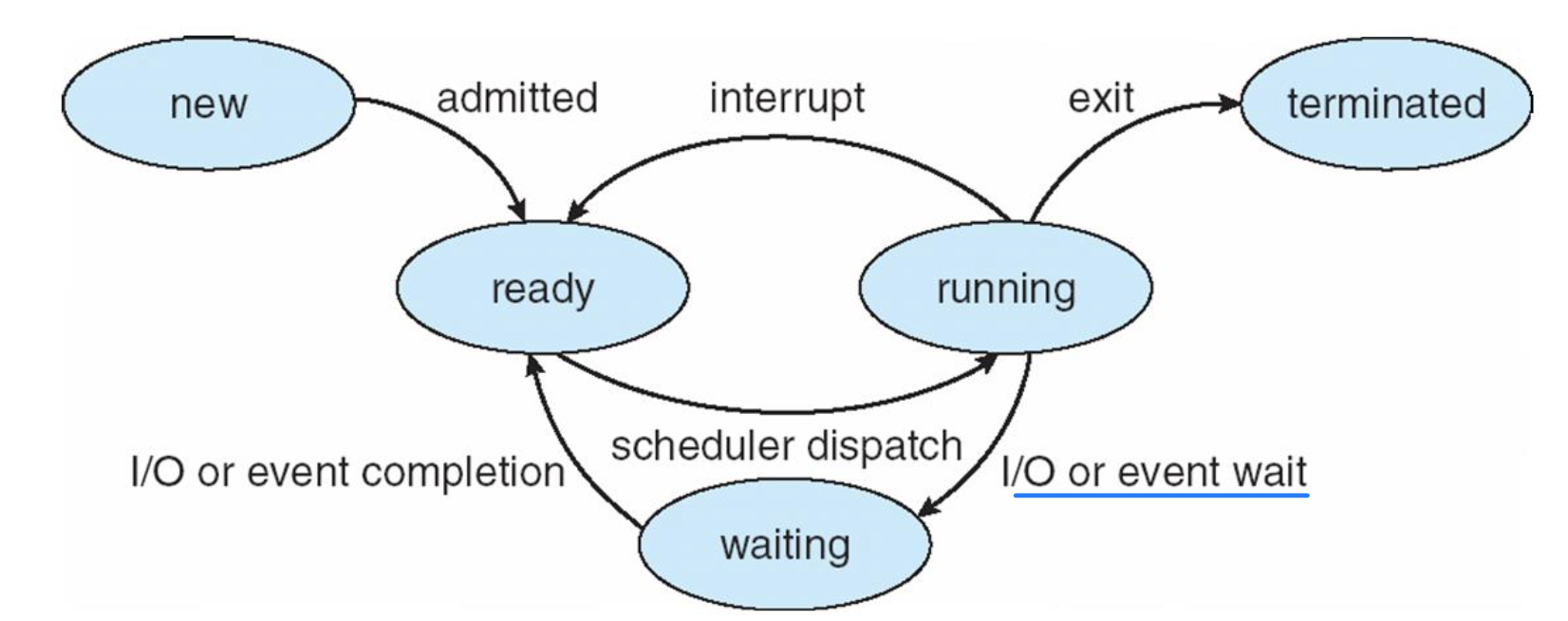
- When a process switches from running state to waiting state → CPU가 놀게됨
- When a process switches from running state to ready state
ex) an interrupt occurs - When a process switches from waiting state to ready state
→ ready로 갔을 때 priority가 높아서 scheduling
ex) completion of I/O - When a process terminates
→ 1 and 4 are inevitable(필수), but 2 and 3 are optional
- Non-preemptive (or cooperative) scheduling
- Scheduling can occur at 1, 4 only
- Running process is not interrupted. - Preemptive scheduling
- Scheduling can occurs at 1, 2, 3, 4
- Scheduling may occur while a process is running
- Requires H/W support and shared data handling
- Preemptive scheduling can result in race conditions when data are shared among several processes- 일종의 버그, 잡기 어려움 → 잡기 위해서 Synchronization
Preemption of OS Kernel
- Preemptive kernel: kernel allows preemption in system call
- Responsive ⬆️. Desirable(적합) real time support application (로봇, 자율주행), but performance ⬇️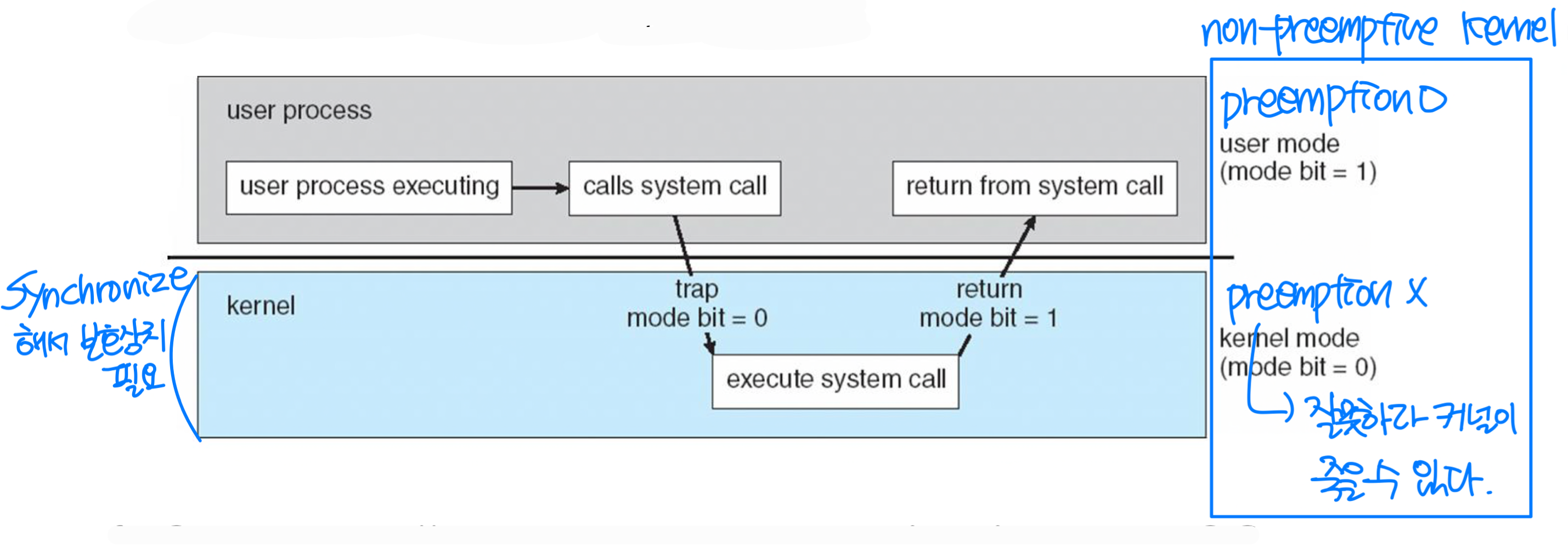
- cf. System calls are non-preemptive in most OS.
- Keeps kernel structure simple
Dispatcher
- Dispatcher: a module that gives control of CPU to the process selected by short-term scheduler
- Switching context
- Switching to user mode
- Jumping to proper location in user program - Dispatch latency: time from stopping one process to starting another process

Scheduling Criteria
- CPU utilization: keep the CPU as busy as possible
- Throughput: # of processes completed per time unit
- Turnaroundtime: interval(간격) from submission of a process to its completion
레디큐에 들어갈 때부터 완료까지의 시간 - Waiting time: sum of periods spent waiting in ready queue
- Response time: time from submission of a request to first response
→ Importance of each criterion vary with systems
🖥️ Scheduling algorithms
First-come, first-served (FCFS) scheduling
- Process that requests CPU first, is allocated CPU first
- Non-preemptive scheduling
- Simplest scheduling method - Sometimes average waiting time is quite(상당히) long
- CPU, I/O utilities are inefficient(비효율적)
Ex) Three processes arrived at time 0
Shortest-job-first (SJF) scheduling
- Assign to the process with the smallest next CPU burst
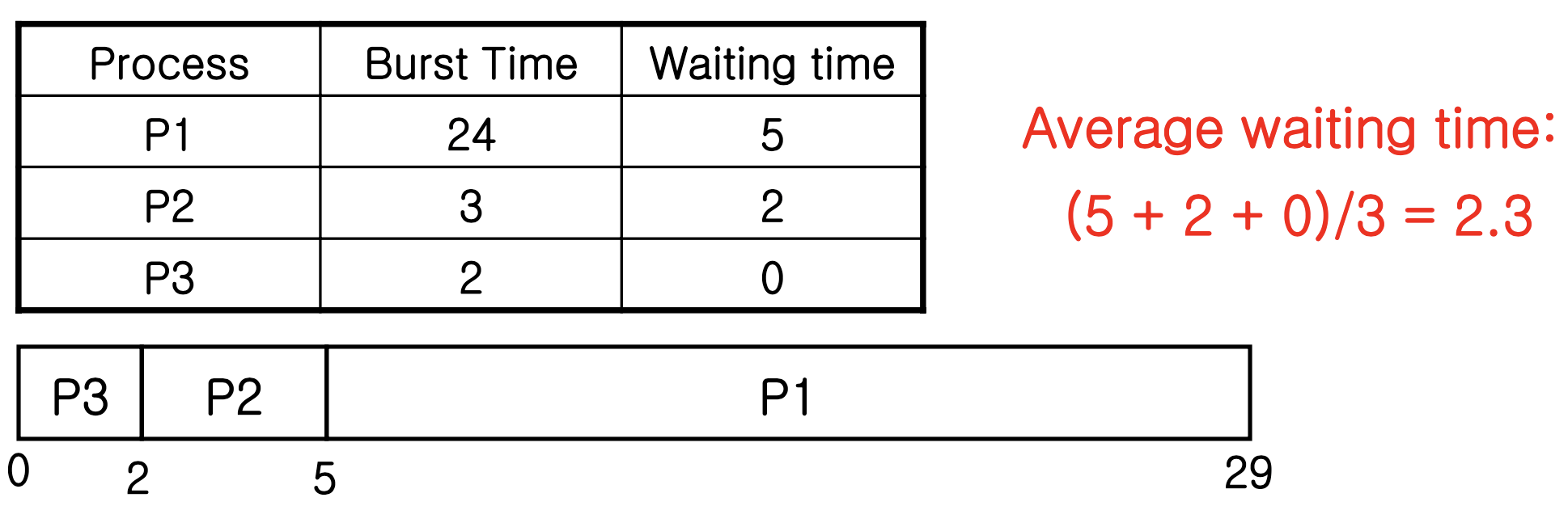 - SJF algorithm is optimal in minimum waiting time
- SJF algorithm is optimal in minimum waiting time
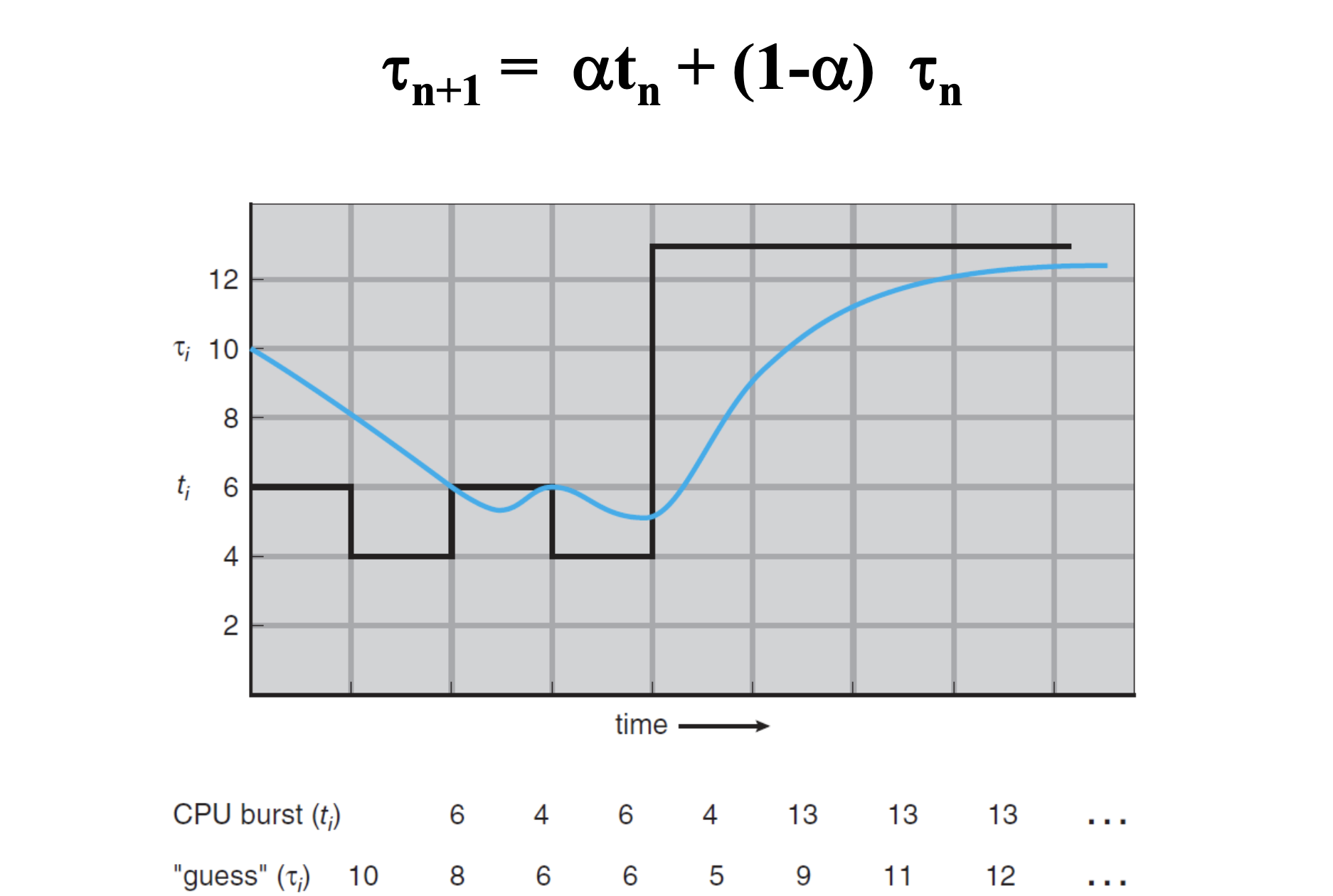
- Problem: difficult to know length of next CPU burst - Predicting next CPU burst from history
- Exponential averaging
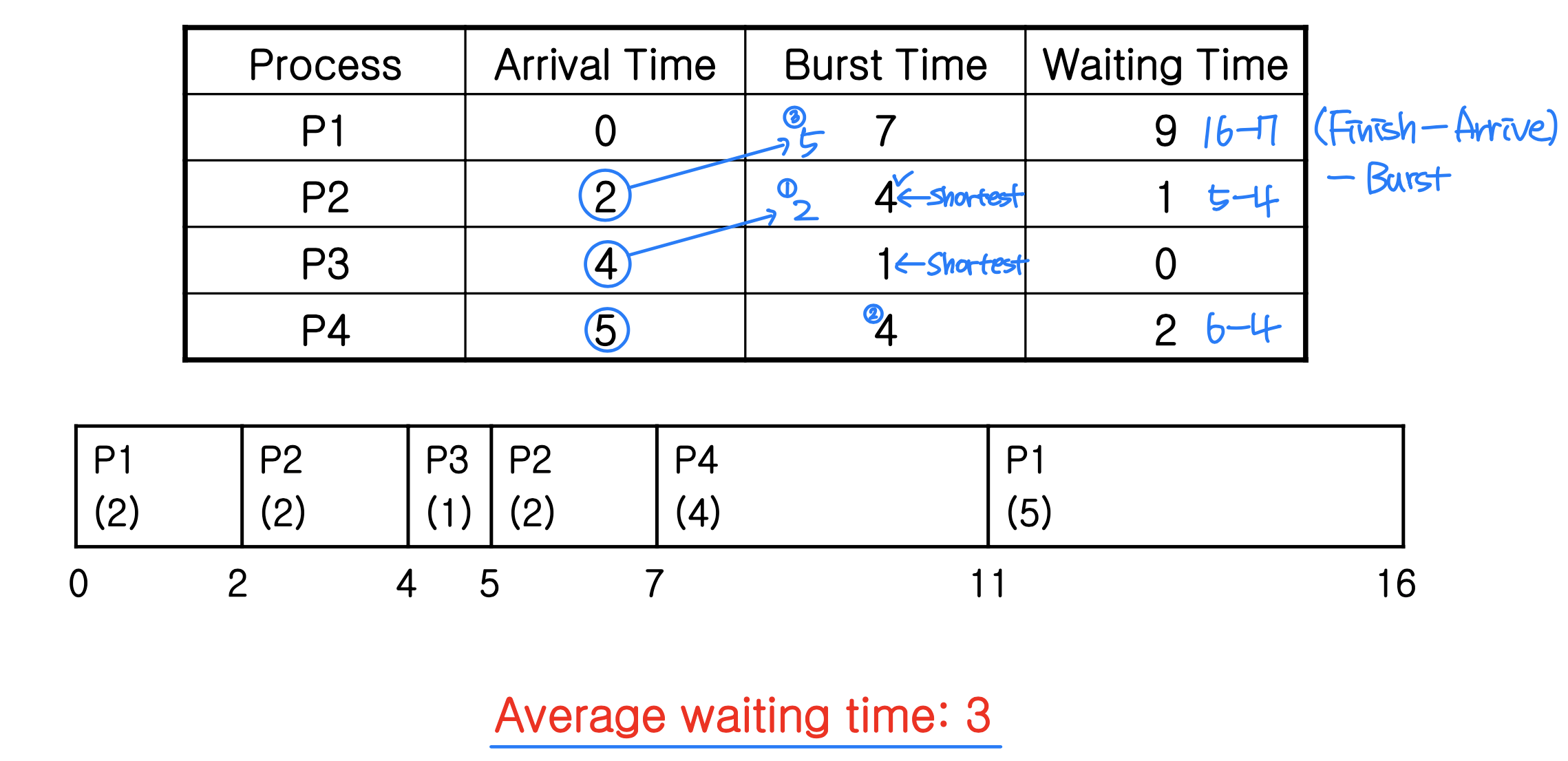
⭐️ Preemptive version of SJF scheduling
- Shortest-remaining(남은)-time-first scheduling
Priority scheduling
- CPU is allocated the process with the highest priority
- Equal-priority processes: FCFS
- In this text, lower number means higher priority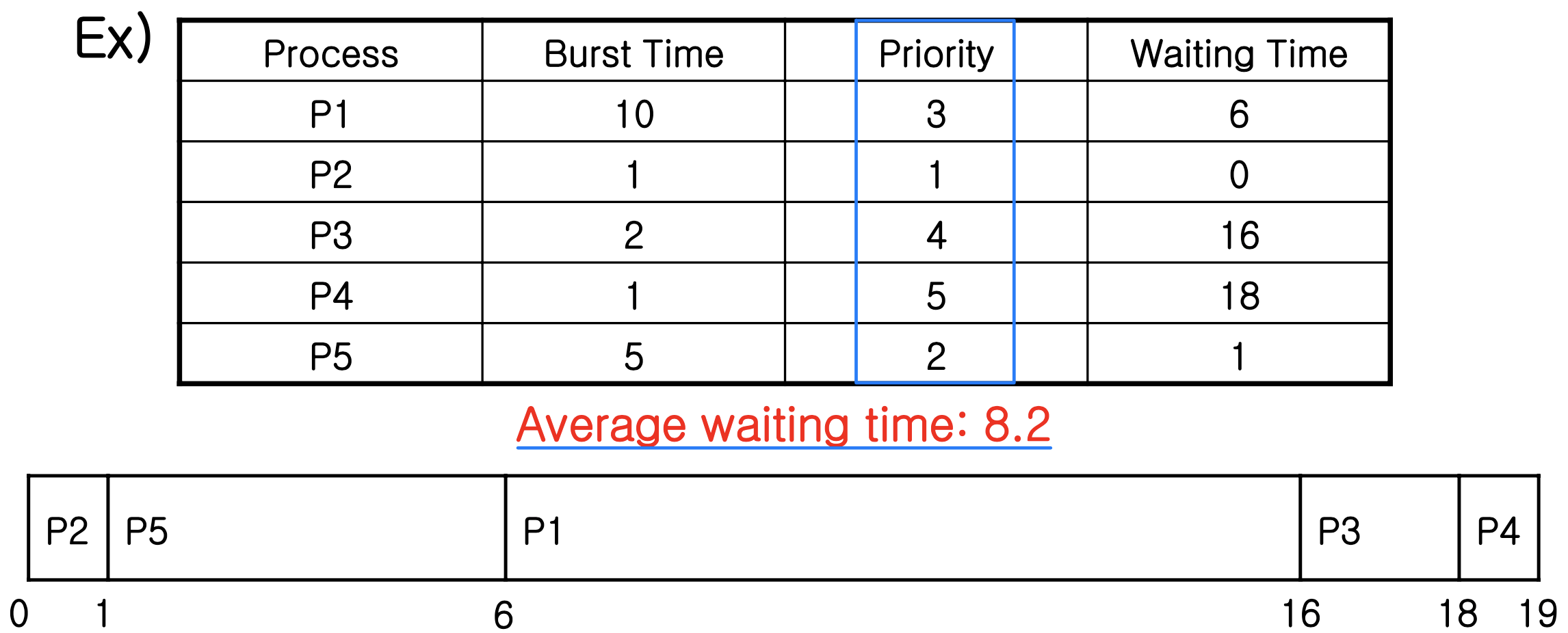
- Priority can be assigned internally and externally
- Internally: determined by measurable quantity(양) or qualities(질)
- Time limit, memory requirement, # of open files, ratio of I/O burst and CPU burst,...
Ex_ gcc(CPU bound), vi(I/O bound) 동시에 → 뭐가 먼저?
→ vi. 사용자와 interact를 해야해서, 우선순위 ⬆️ - Externally: importance, political factor (외부에서 지정)
- Internally: determined by measurable quantity(양) or qualities(질)
- Priority scheduling can be preemptive or non- preemptive
- Major problems
- Indefinite blocking (= starvation) of processes with lower priorities
→ Solution : aging ( gradually(점진적으로) increase priority of processes waiting for long time )
Round-robin scheduling
- Similar to FCFS, but it’s preemptive
- Designed for time-sharing systems
- CPU time is divided into time quantum ( or time slice )
- A time quantum is 10~100 msec
Cf. switching latency: 10 usec (마이크로, msec와 1000배 차이) - Ready queue is treaded(진행) as circular queue
- CPU scheduler goes around the ready queue and allocate CPU time up to 1 time quantum
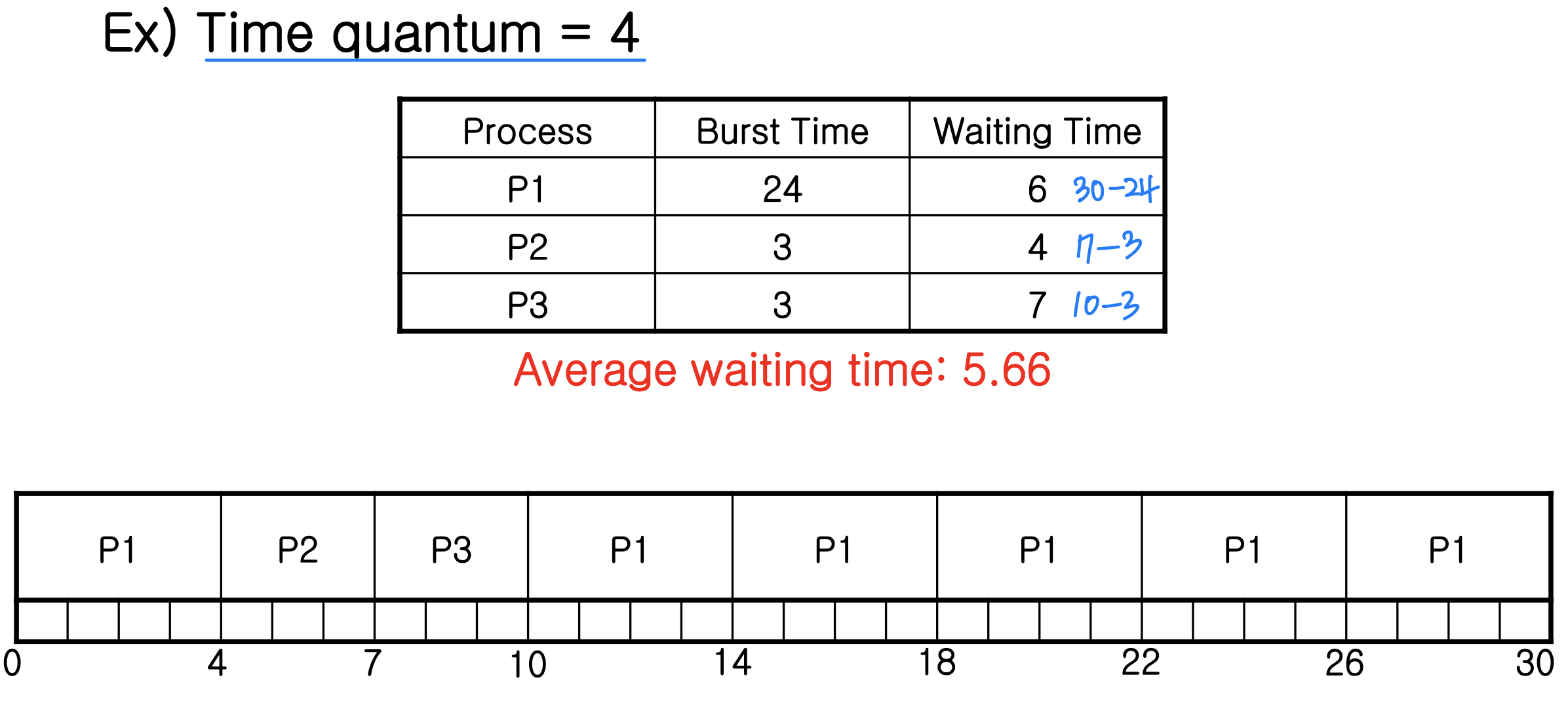
- Performance of RR scheduling heavily depends on size of time quantum
- Time quantum is small: processor sharing → reponsive, switching overhead
- Time quantum is large: FCFS - Context switching overhead depends on size of time quantum
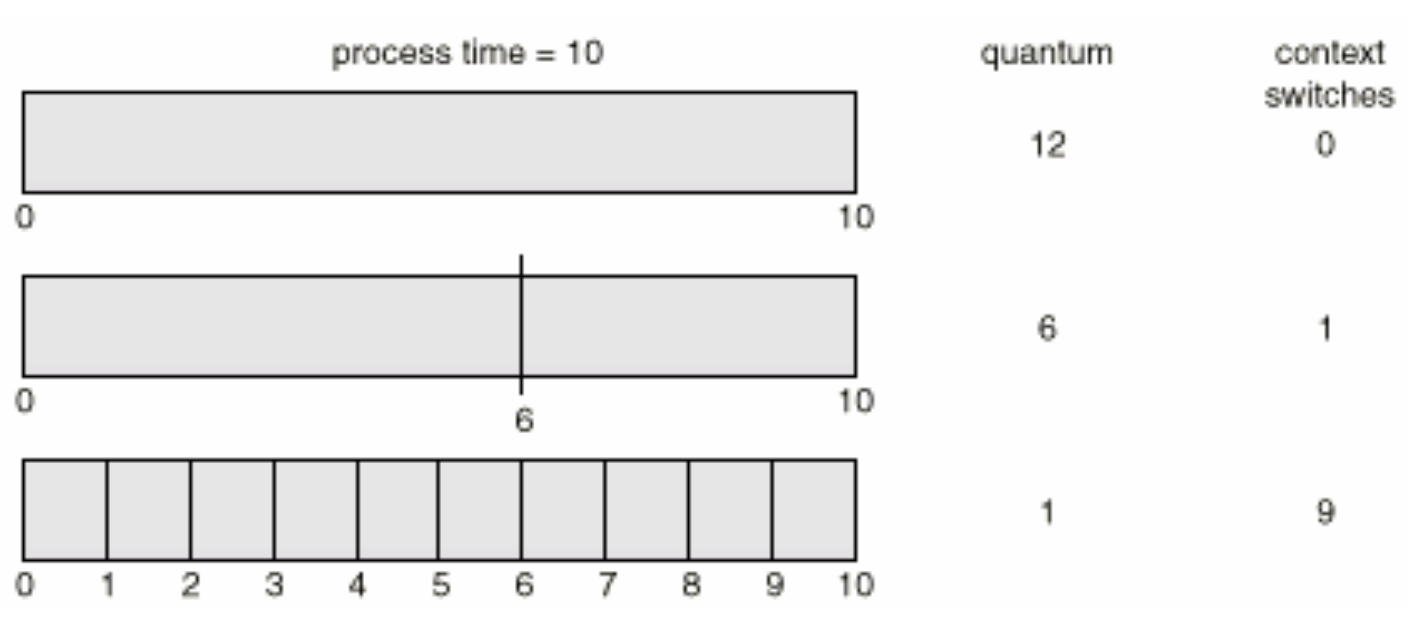
- Turnaroundtime also depends on size of time quantum
- Average turnaround time is not proportional(비례) nor inverse-proportional(반비례) to size of time quantum
- Average turnaroundtime is improved if most processes finish their next CPU burst in a single time quantum
- However, too long time quantum is not desirable(바람직한)
- A rule of thumb(어느정도 통하는 solution): about 80% of CPU burst should be shorter than time quantum- I/O bound는 다들어가지만, CPU bound는 여러번에 들어가게
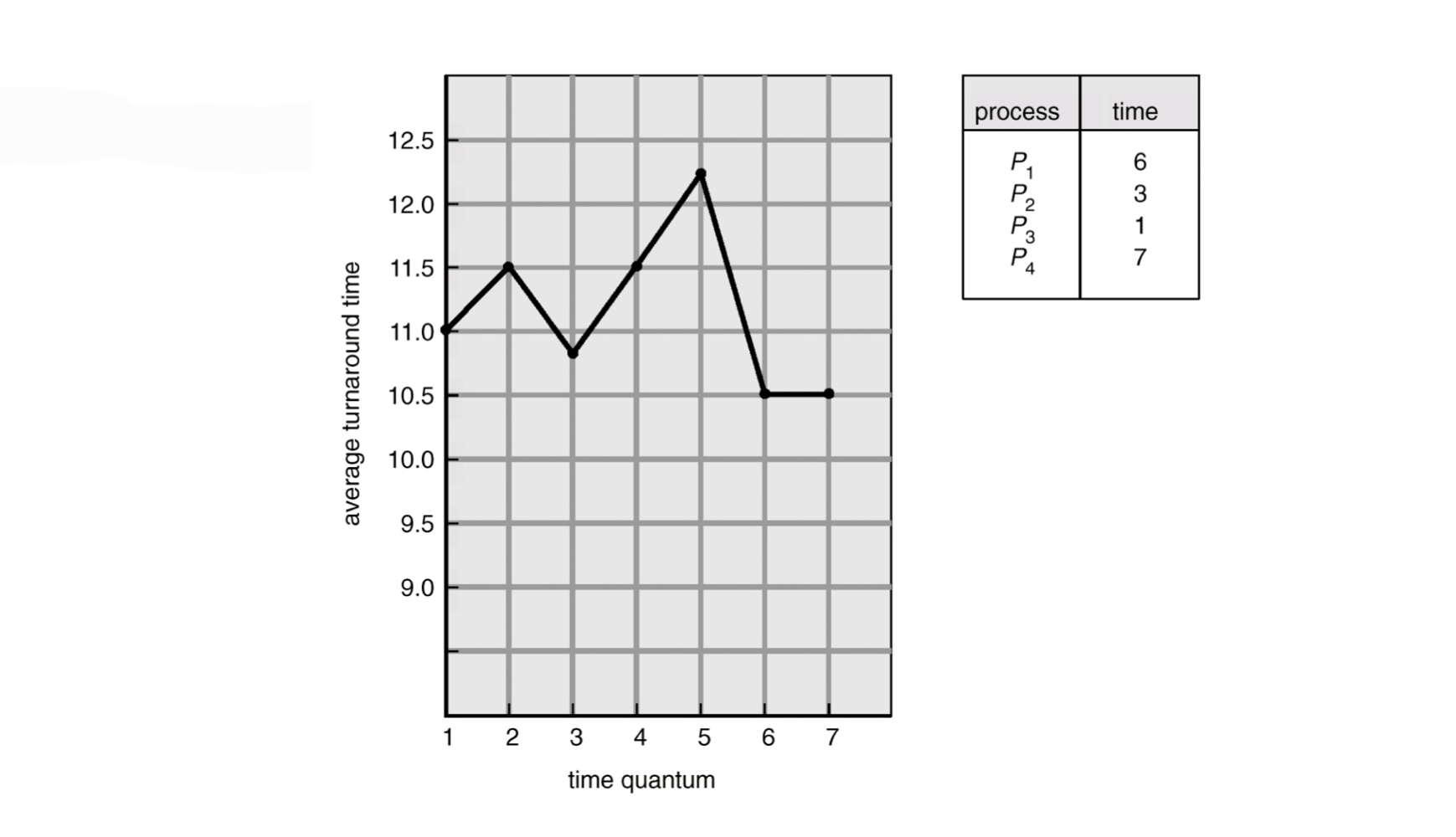 → turnaround time : waiting time + executing time
→ turnaround time : waiting time + executing time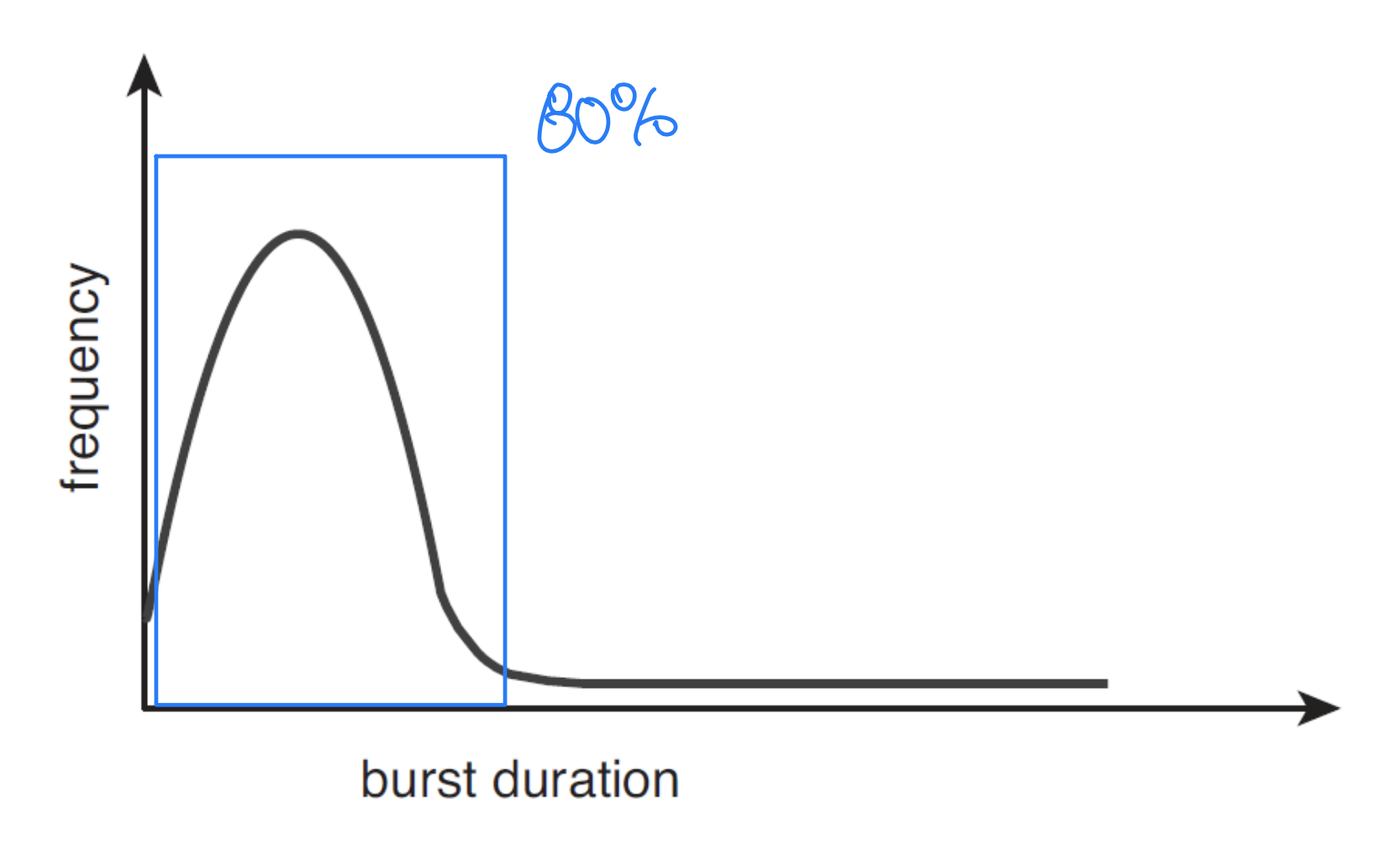
- I/O bound는 다들어가지만, CPU bound는 여러번에 들어가게
Multilevel queue scheduling
- Classify processes into different groups and apply different scheduling
- Memory requirement, priority, process type, ... - Partition(분할) ready queue into several separate queues
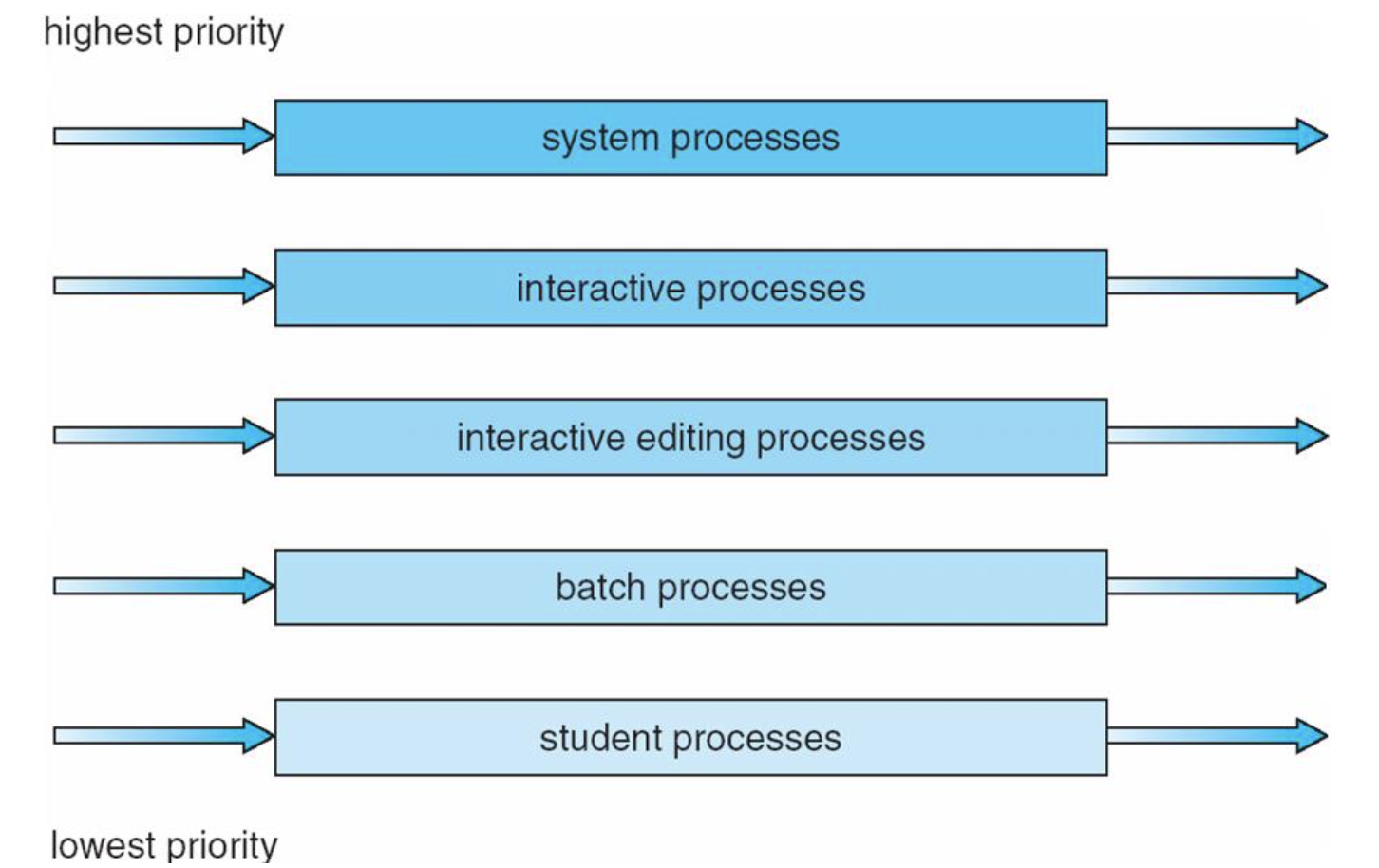
- Each queue has its own scheduling algorithm
- Scheduling among queues
- Fixed-priority preemptive scheduling
- A process in lower priority queue can run only when all of higher priority queues all empty
- Time-slicing among queues
Ex) foreground queue (interactive processes): 80%
background queue (batch processes): 20%
- Fixed-priority preemptive scheduling
- Assignment of a queue to a process is permanent (영구적인) → 위아래로 못옮김
Multiple feedback-queue scheduling
- Similar to multilevel queue scheduling, but a process can move between queues
- Idea: separate processes according to characteristics of their CPU bursts
- If a process uses too much CPU time(CPU bound), move it to lower priority queue
- I/O-bound, interactive processes are in higher priority queues (more interation) - Ex) Ready queue consists of three queues (0~2)
- Q0 (time limit = 8 milliseconds)
- Q1 (time limit = 16 milliseconds)
- Q2 (FCFS)
➔ A new process is put in Q0. if it exceeds time limit, it moves to lower priority queue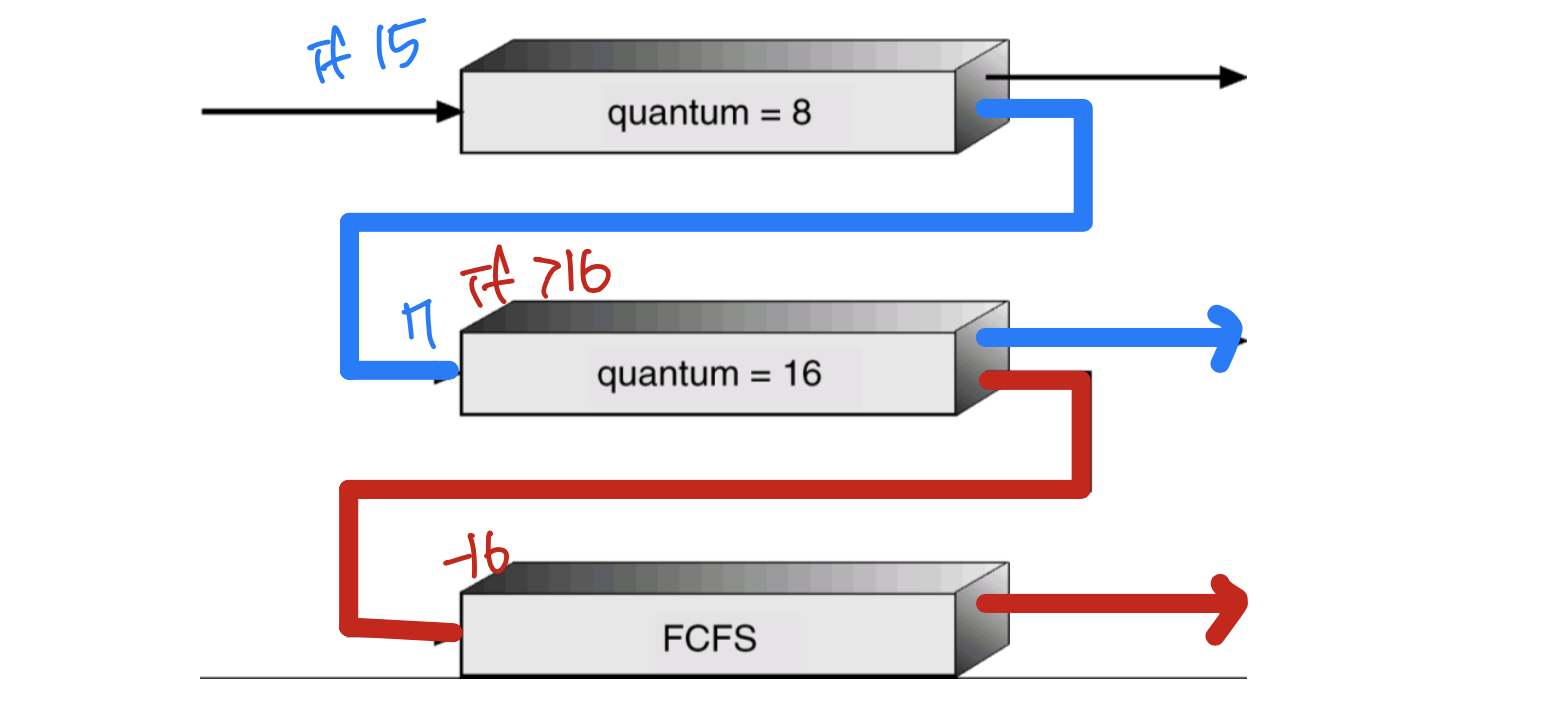
- Parameters to define a multilevel feedback-queue scheduler (options)
- # of queues
- Scheduling algorithm for each queue
- Method to determine when to upgrade a process to higher priority queue
- Method to determine when to demote a process to lower priority queue
- Method to determine which queue a process will enter when it needs service
➔ The most complex algorithm
🖥️ Multiple-processor scheduling
- Multiple-processor(CPU) system
- Load sharing is possible
- Scheduling problem is more complex - There are many trials in multiple-processor scheduling, but no generally best solution
- In this text, all processors are assumed identical(동일)
- Any process can run on any processor - Symmetric vs. Asymmetric Multiprocessing
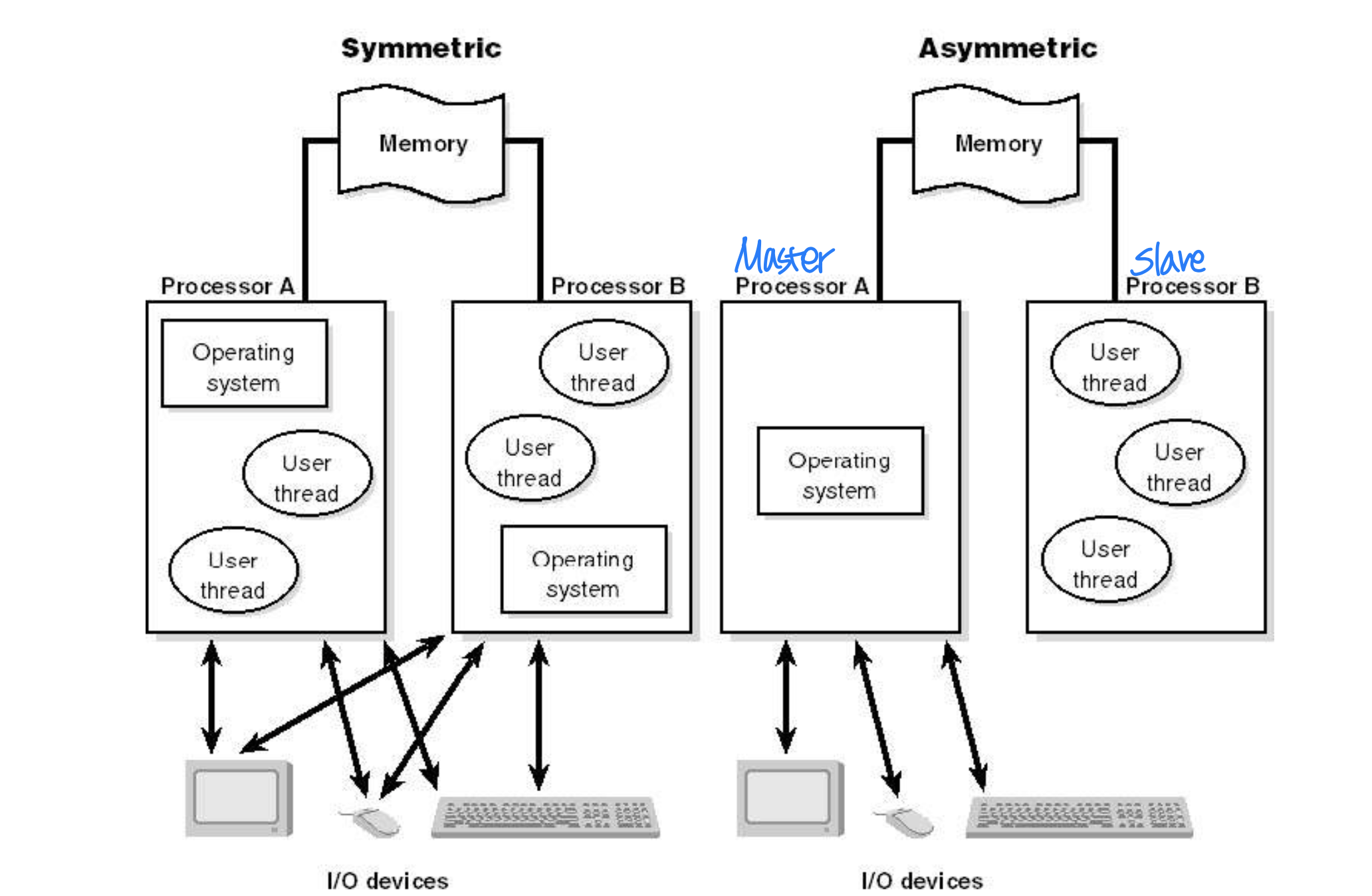
→ 역할이 같냐 다르냐, 대부분 symmetric - Two possible strategies
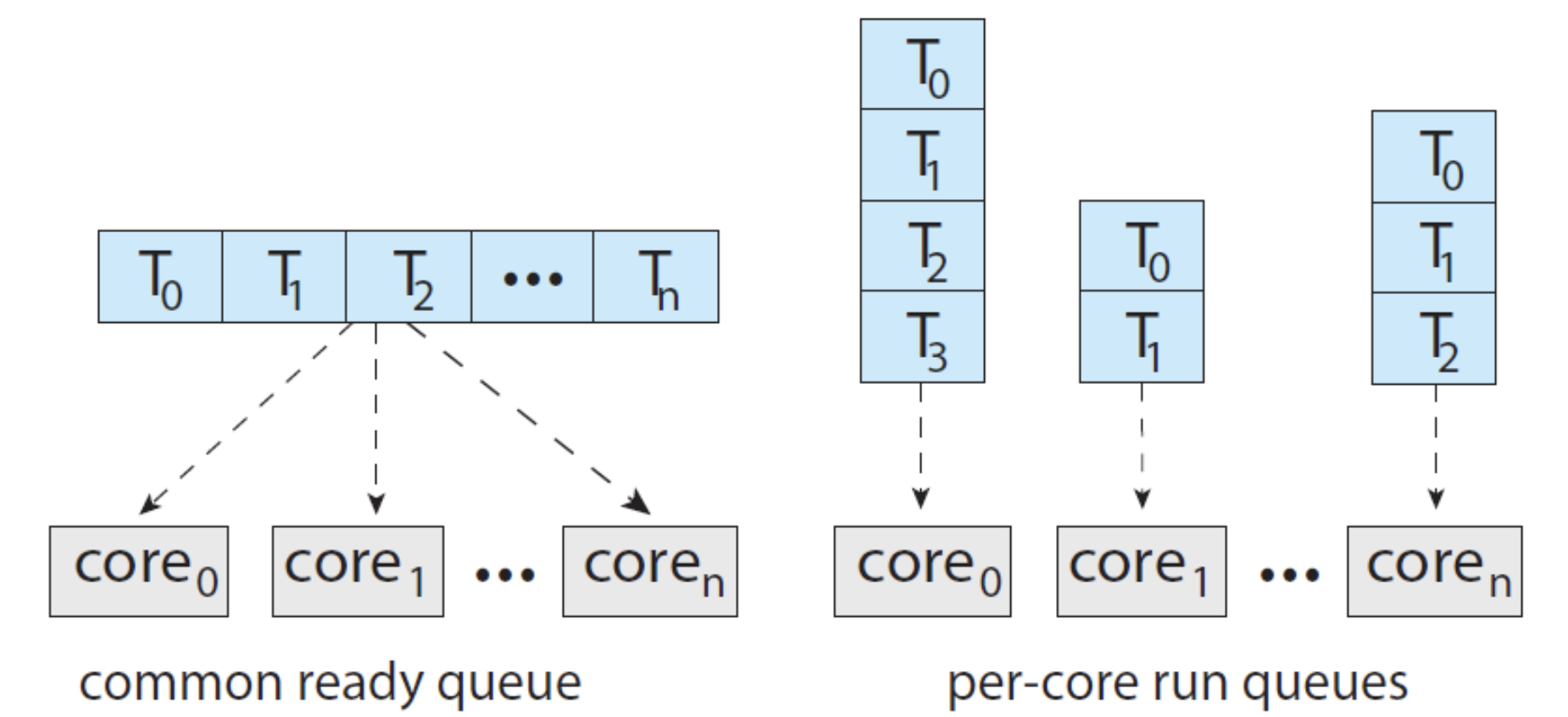
- All threads may be in a common ready queue
- Needs to ensure(보장하다) two processors do not choose the same ready thread nor lost from the queue
- Each processor may have its own private queue of threads
Processor Affinity(친화력)
- Overhead of migration of processes from one processor to another processor
migration : 시스템, 데이터, 어플리케이션 등을 한 장소에서 다른 장소로 이전하는 것을 의미
- All contents of cache should be invalidated(무효화) and re-populated(다시 채움) - Processor affinity: keeping a process running on the same processor to avoid migration overhead
- Soft affinity: Although OS attempts to keep a process running on the same processor, a process may migrate between processors
- Hard affinity: It is possible to prevent a process from being migrated to other processor
→ 절대로 안 옮긴다
Load Balancing
- Load balancing: attempt to keep the workload evenly(고르게) distributed across all processors
- Necessary for system where each processor has its own ready queue (for most modern OS’s) - Two general approaches
- Push migration
- A specific task periodically checks the load on each processor
- If unbalance is found, move processes to idle(게으른) or less-busy processors - Pull migration
- An idle processor pulls a waiting task - Note! Push and pull migration can be implemented in parallel
→ Linux, ULE scheduler for FreeBSD
- Push migration
- Load balancing can counteract(상쇄) the benefit of processor affinity
Multi-core Processors
- Multi-core processor: multiple processor cores on the same physical chip
- Recent trend
- Faster and consume less power than systems in which each processors has its own physical chip - Scheduling issues on multi-core processor
- Memory stall: for various reasons, memory access spends significant(상당한) amount time waiting for the data to become available(사용가능)
Ex) accessing data not in cache
- Remedy(해결): multithreaded processor cores- Two or more hardware threads are assigned to each core
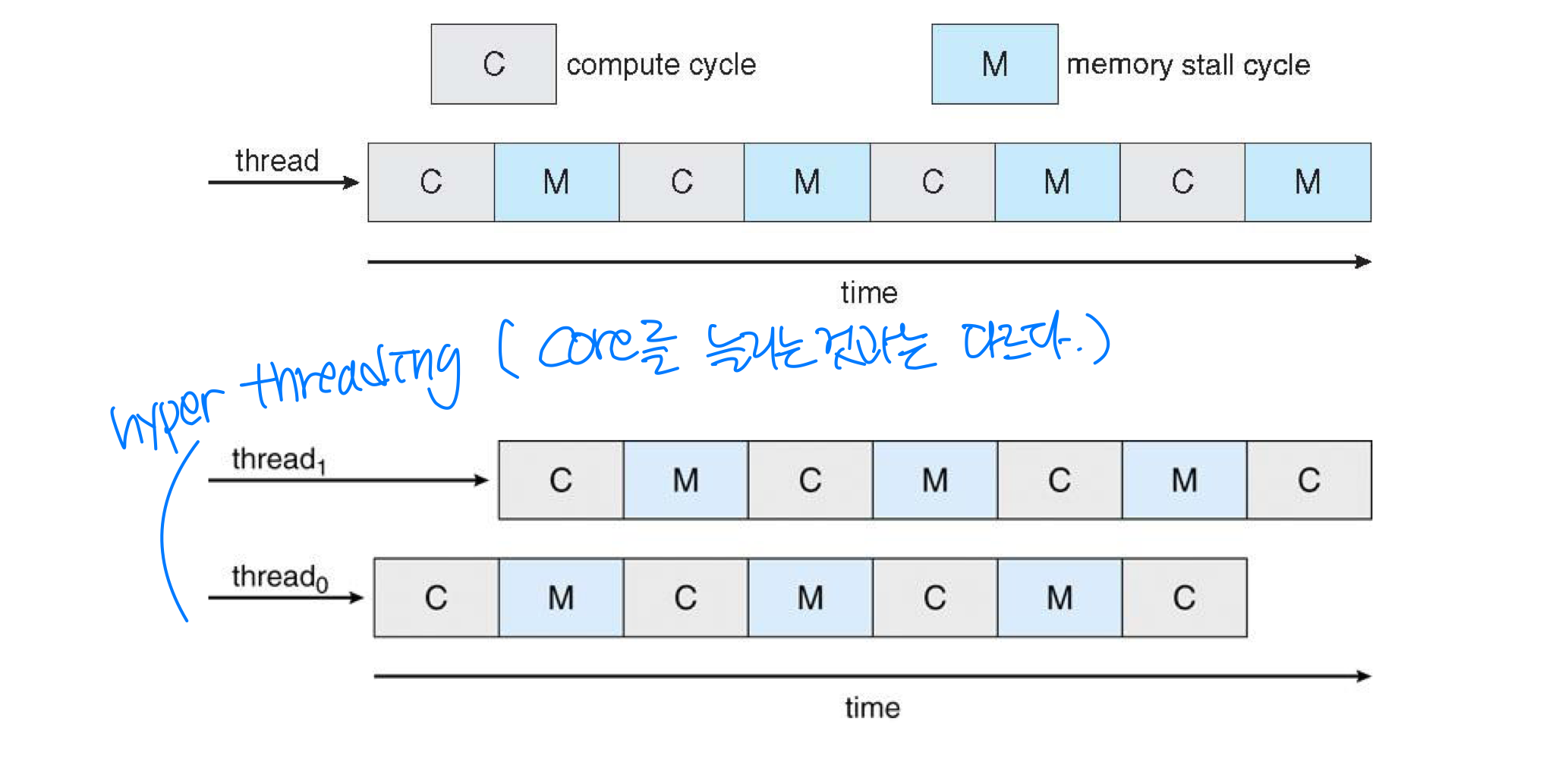

- Two or more hardware threads are assigned to each core
🖥️ Thread scheduling
- Threads
- User thread → supported by thread library
- Scheduled indirectly(간접적으로) through LWP - Kernel thread → supported by OS kernel
- User thread → supported by thread library
- Actually, it is not processes but kernel threads(스케줄링의 단위) that are being scheduled by OS
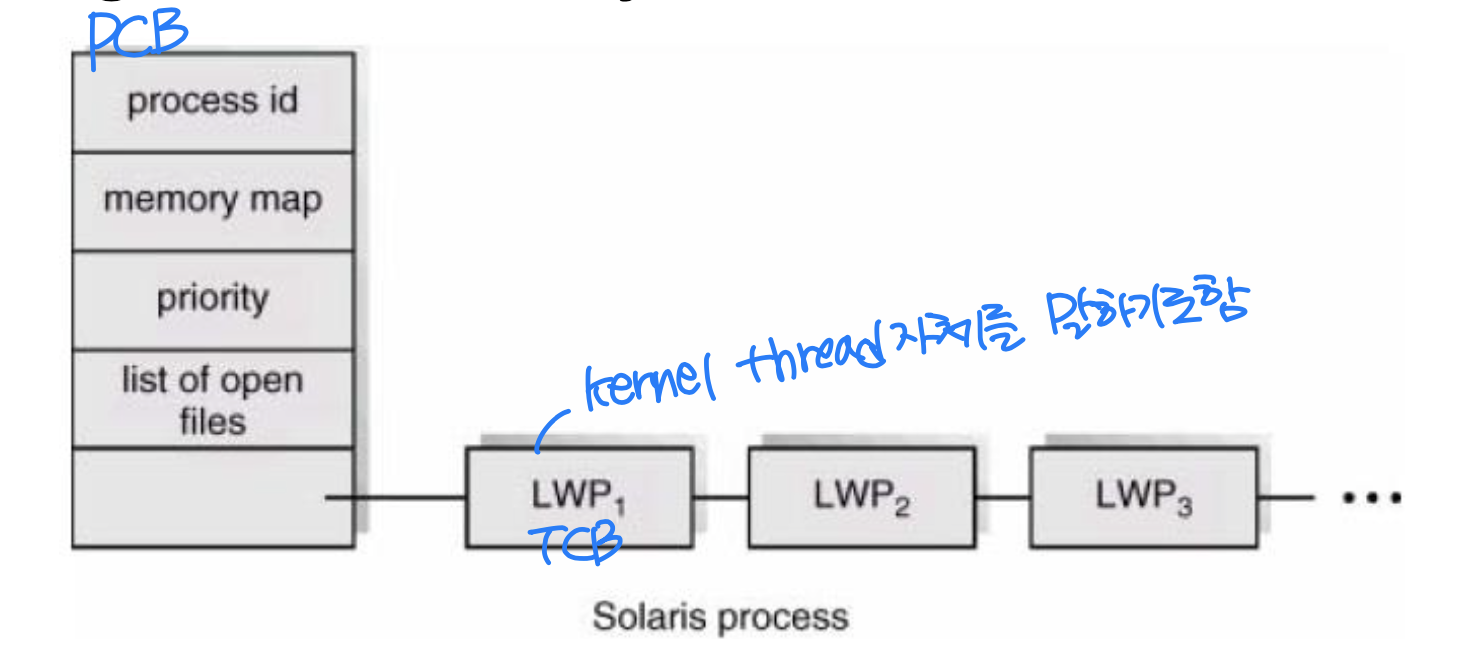
Contention Scope
- Process-contention scope (PCS) → 같은 process 안에서만 경쟁
- Competition(경쟁) for LWP among user threads
- Many-to-one model or many-to-many model - Priority based
- Competition(경쟁) for LWP among user threads
- System-contention scope (SCS) → System 전체
- Competition for CPU among kernel threads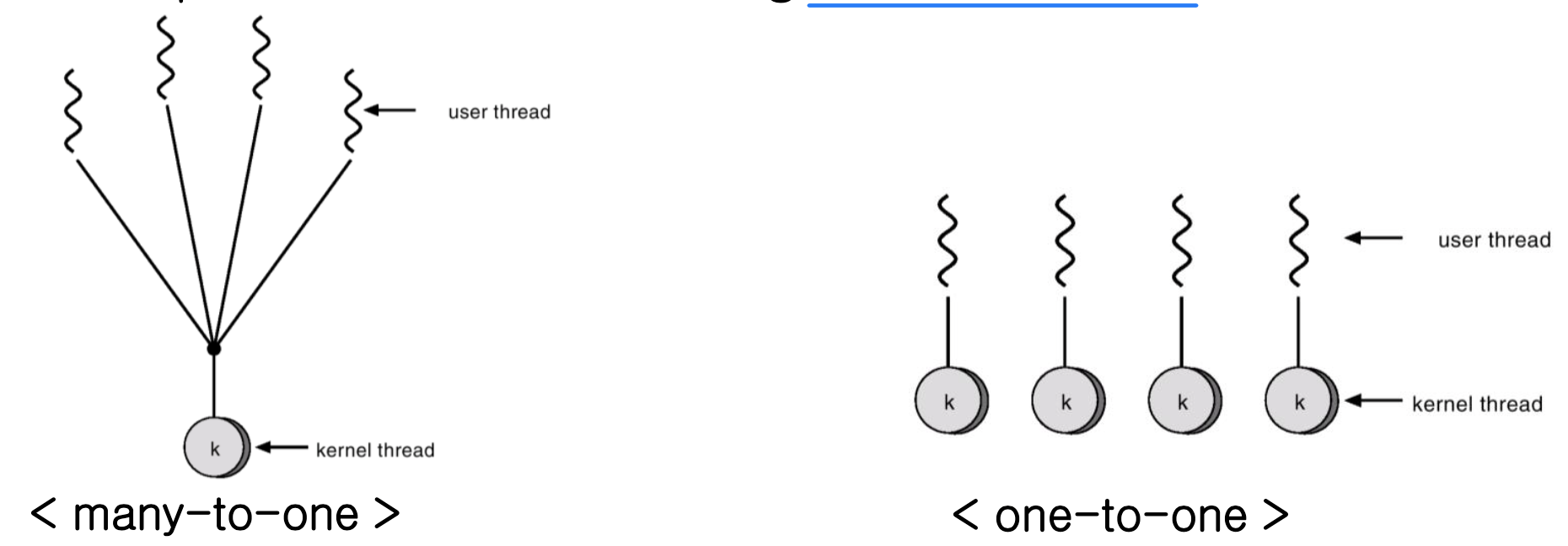
- Scheduler Activation and LWP
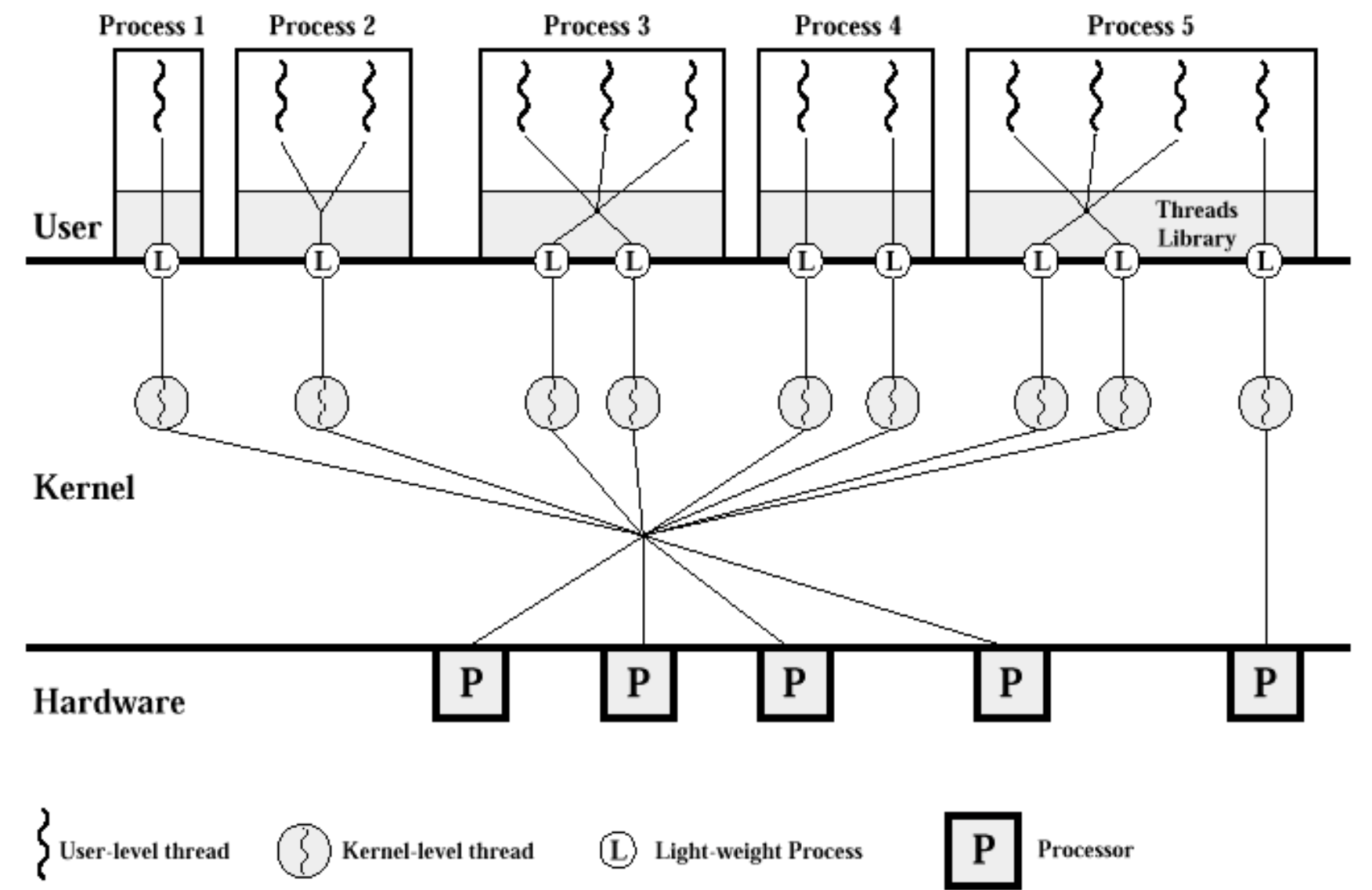
Pthread Scheduling
- In thread creation with Pthreads, we can specify PCS or SCS
- PCS(PTHREAD_SCOPE_PROCESS):
- In many-to-one, only PCS is possible - SCS(PTHREAD_SCOPE_SYSTEM):
- In one-to-one model, only SCS is possible - Note: On certain(특정) system, only certain values are allowed
- Linux, MacOS X
- PCS(PTHREAD_SCOPE_PROCESS):
- Related functions
- pthread_attr_setscope(pthread_attr_t *attr, int scope)
- pthread_attr_getscope(pthread_attr_t *attr, int *scope)
🖥️ Real-time CPU scheduling
- Real-time system : 정해진 time limit안에 request 처리 Ex_ 자율주행, 로봇
- Real-time Operating Systems (RTOS) ➡️ Priority queue
- OS intended to serve real-time systems
Ex) Antirock brake system (ABS) requires latency of 3~5 msec
➡️ Systemcall 빠르게, scheduling ( real-time application high priority ) - Soft real-time systems ➡️ Ex_ Linux
- No guarantee as to when a critical real-time process will be scheduled.
- Guarantee only that the process will be given preference over noncritical processes.
➡️ Deadline 보장은 못하지만, high priority를 줘서 resource 몰아줌 - Hard real-time systems
- A task must be serviced by its deadline
- Service after the deadline has expired is the same as no service at all.
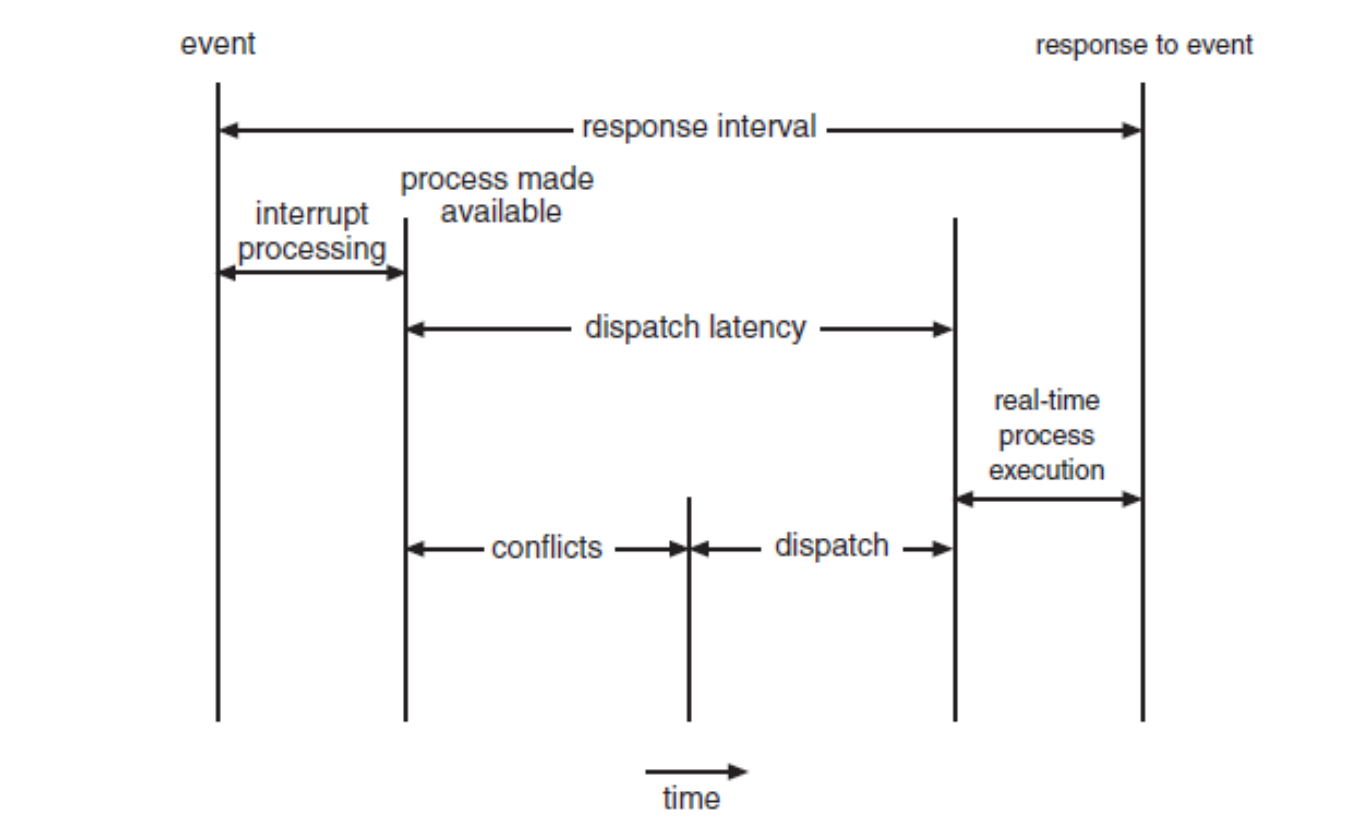
Minizing latency
- Most real-time systems are event-driven system ➡️ modern OS
- When an event occurs, the system must respond to and service it as quickly as possible
- Event latency: the amount of time that elapses from when an event occurs to when it is serviced
- Interrupt latency, dispatch latency (switching latency)
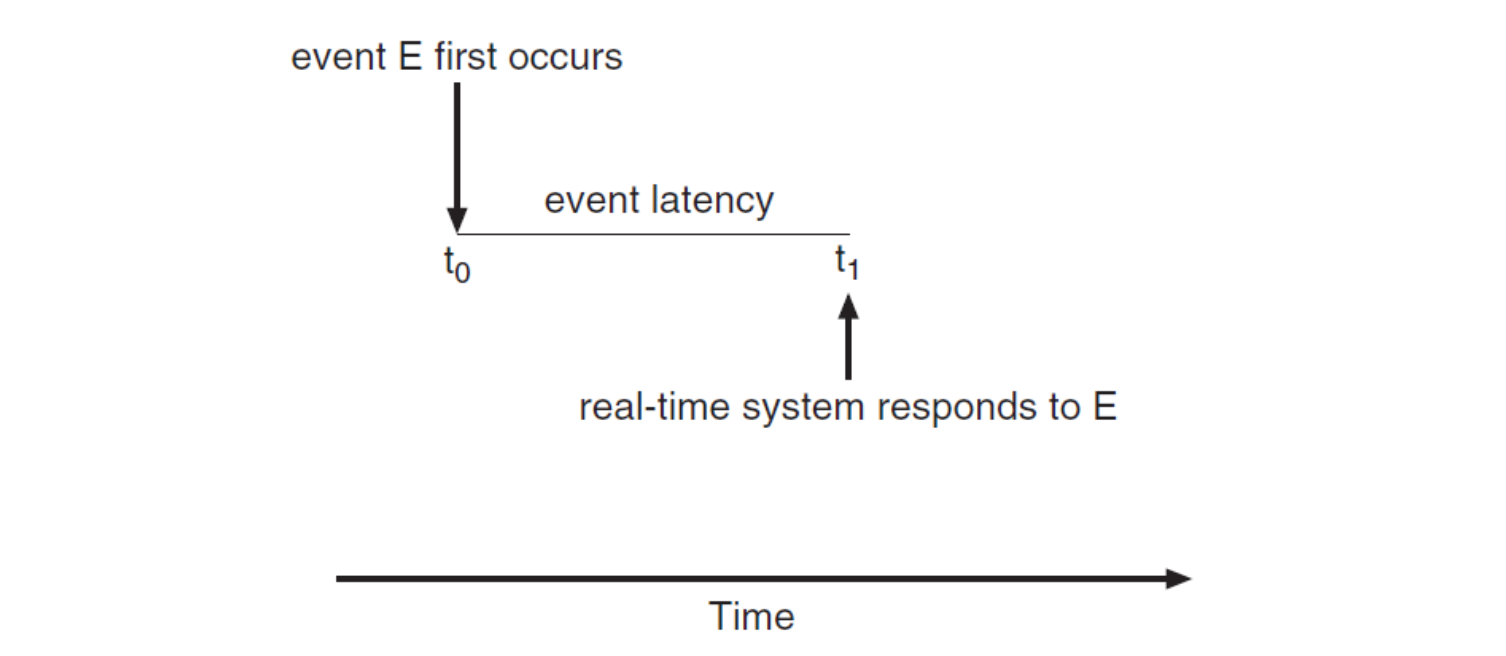
- Interrupt latency, dispatch latency (switching latency)
Interrupt latency
- Interrupt latency: the period of time from the arrival of interrupt at the CPU to the start of the routine that services the interrupt
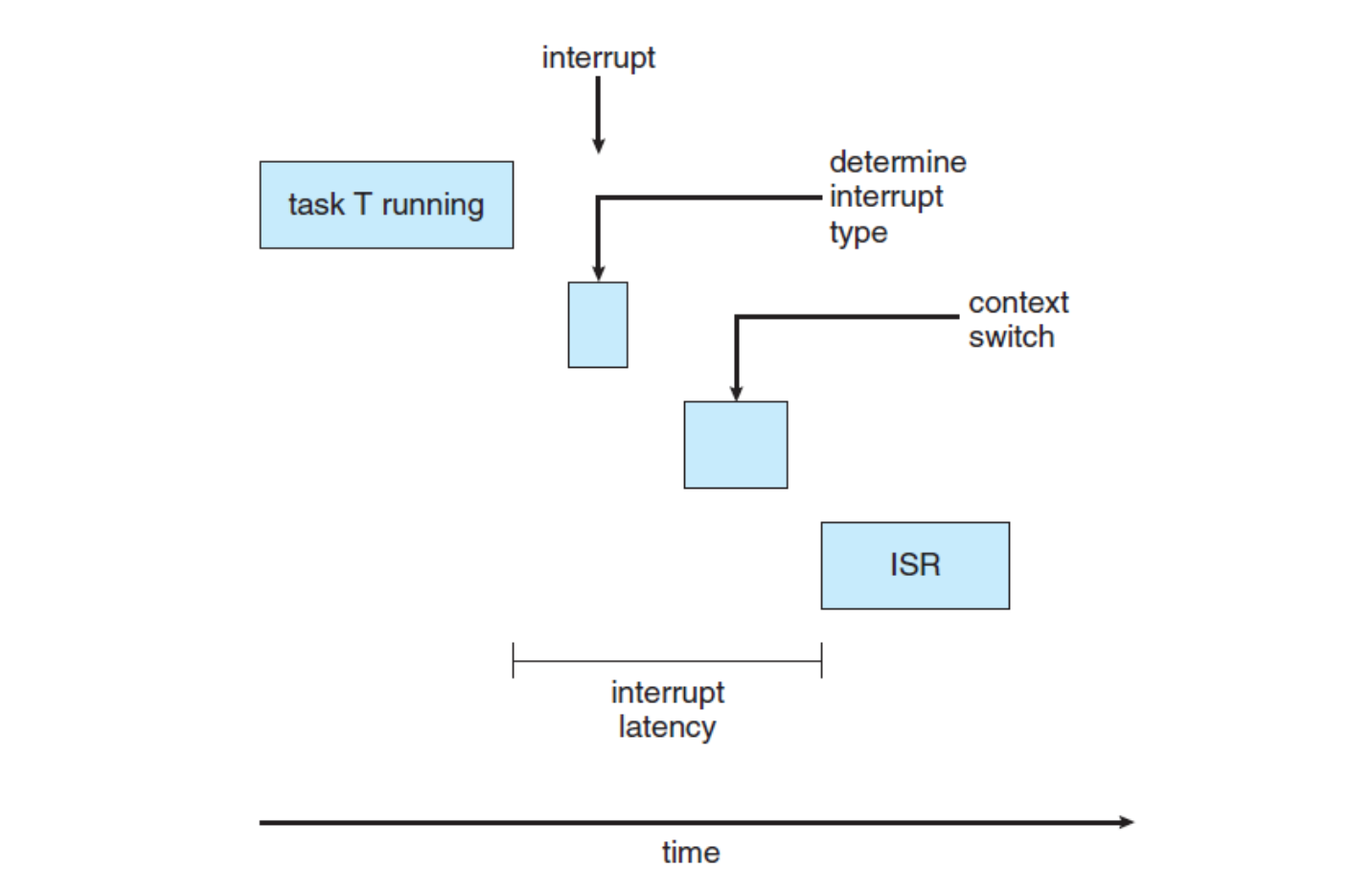
Dispatch latency
-
Dispatch latency: the amount of time required for the scheduling dispatcher to stop one process and start another
- ⭐️ Preemptive kernels are the most effective technique to keep dispatch latency low
-
Conflict phase
1. Preemption of any process running in the kernel
2. Release of resources occupied by low-priority processes needed by a high-priority process ➡️ priority inversion : 반대상황 ➡️ Aging -
Dispatch phase schedules the high-priority process onto an available CPU.
Priority-based Scheduling
- The most important feature of RTOS is to respond immediately
to a real-time process- The scheduler should support priority-based preemptive algorithm
- Most OS assign highest priority to real-time processes
- Preemptive, priority-based scheduler only guarantees soft real-time functionality
- Hard real-time systems must further guarantee that real-time tasks will be serviced in accord with their deadline requirements
- Requires additional scheduling features
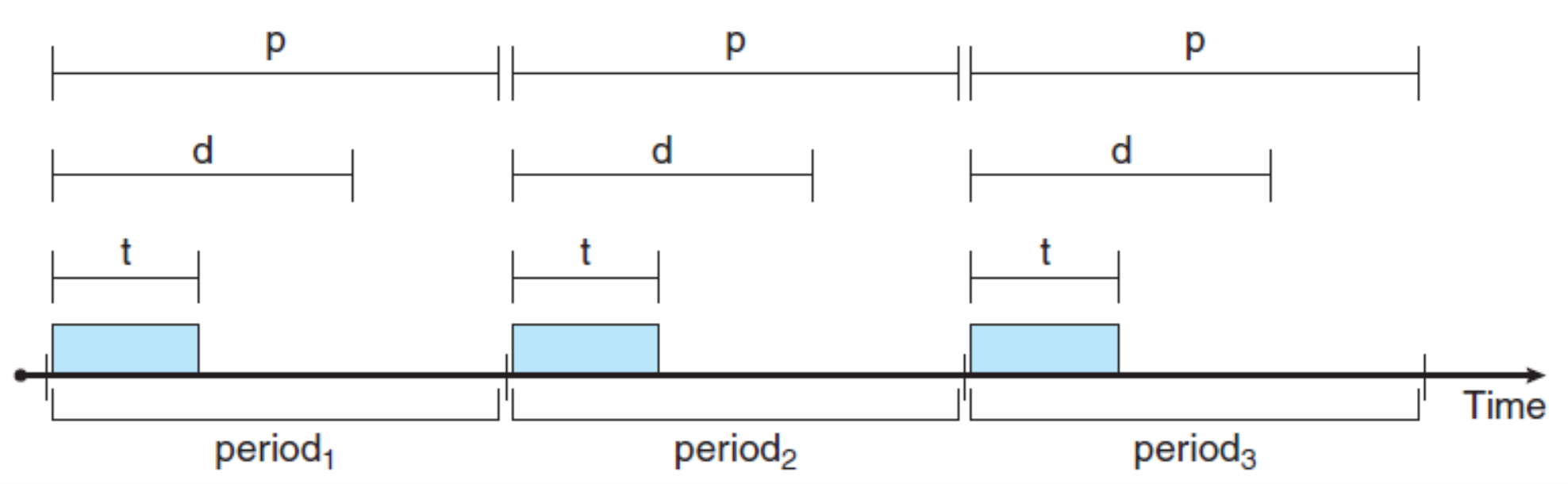
Periodic Process
- Periodic processes require the CPU at constant intervals (periods)
- A fixed processing time 𝑡
- A deadline 𝑑 by which it must be serviced by the CPU ( 무조건 끝나야함 )
- A period 𝑝 ➡️
- The rate of a periodic task( 실행율(빈도수) ): 1/𝑝
Scheduling with Deadline Requirement
- A process may have to announce its deadline requirements to the scheduler
- Using an admission-control algorithm, the scheduler does one of two things:
- Admits the process, guaranteeing that the process will complete on time, or
- Rejects the request as impossible if it cannot guarantee that the task will be serviced by its deadline
Rate-Monotonic Scheduling
- for only period process
- Rate-monotonic scheduling algorithm
- Schedules periodic tasks using a static priority policy with ⭐️preemption 무조건
- Each periodic task is assigned a priority inversely based on its period
➡️ shortest period first - The processing time of a periodic process is assumed the same for each CPU burst
- Rate-monotonic scheduling is considered optimal
c.f SJF is optimal (waiting time)- If a set of processes cannot be scheduled by this algorithm, it cannot be scheduled by any other algorithm that assigns static priorities.
- Limitation
- CPU utilization is bounded, and it is not always possible to maximize CPU resources fully
- Worst-case CPU utilization:
- : # of processes
Earliest-Deadline-First Scheduling
- Earliest-deadline-first (EDF) scheduling
- The earlier the deadline, the higher the priority - Requirements ➡️ deadline assignment 필수, period P가 아니여도됨
- When a process becomes runnable, it must announce its
deadline requirements to the system.
- Does not require that processes be periodic, nor must a process require a constant amount of CPU time per burst. - Theoretically optimal
- Theoretically, it can schedule processes so that each process can meet its deadline requirements and CPU utilization will be 100 percent
Proportional Share Scheduling
- Proportional share schedulers ➡️ share 단위로 나눔 합이 < 𝑇
- Allocates 𝑇 shares among all applications.
- An application can receive 𝑁 shares of time, thus ensuring that the application will have 𝑁 ∕ 𝑇 of the total processor time
- Must work in conjunction with an admission-control policy to guarantee that an application receives its allocated shares of time
- Ex_ 85 / 100 shared, if now require 30 shares ➡️ reject
POSIX Real-Time Scheduling
- Scheduling classes(scheduling policy ➡️ priority) for real-time threads
- SCHED_FIFO: FCFS policy
- No time slicing among threads of equal priority
- The highest-priority real-time thread at the front of the FIFO queue will be granted the CPU until it terminates or blocks - SCHED_RR: a round-robin policy.
- Similar to SCHED_FIFO
- Time slicing among threads of equal priority. - SCHED_OTHER: system-specific ➡️ user define
- Implementation is undefined
- SCHED_FIFO: FCFS policy
- POSIX API for getting/setting scheduling policy
- pthread_attr getschedpolicy(pthread_attr_t *attr, int *policy);
- pthread_attr setschedpolicy(pthread_attr_t *attr, int policy);
int i = 0, policy = 0;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */ pthread_attr_init(&attr);
/* get the current scheduling policy */
if(pthread_attr_getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else {
if(policy == SCHED_OTHER)
printf("SCHED OTHER\n");
else if(policy == SCHED_RR)
printf("SCHED RR\n");
else if(policy == SCHED_FIFO)
printf("SCHED FIFO\n");
}
/* set the scheduling policy - FIFO, RR, or OTHER */
if (pthread_attr_setschedpolicy(&attr, SCHED_FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);HGU 전산전자공학부 김인중 교수님의 23-1 운영체제 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.

HGU - 개인 공부 기록용 블로그