
🖥️ Datasets & DataLoaders
Dataset
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()수동으로 Datasets에 리스트 형식으로 인덱싱 할 수 있다.
Custom Dataset
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label커스텀 Dataset을 만들기 위해서는 init, len, getitem을 구현하여야 한다.
DataLoader
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
Dataset은 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한 번에 진행
모델을 학습할 때, 일반적으로 샘플들을 《미니배치(minibatch)》로 전달하고, 매 에폭(epoch)마다 데이터를 다시 섞어서 과적합(overfit)을 막고,Python의multiprocessing을 사용하여 데이터 검색 속도를 높인다.
DataLoader는 이러한 복잡한 과정을 알아서 처리해준다.
데이터를 불러오고 필요에따라 순회가 가능하다. 각 순회마다 피처와 레이블을 포함하는 배치를 반환한다.
🖥️ Transforms
ToTensor
transform = ToTensor()PIL 이미지나 Numpy array를 Tensor로 변환한다.
Lamda
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))사용자 정의 람다함수를 할당
🖥️ Build the Neural Network
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms신경망은 데이터에 대한 연산을 수행하는 계층(layer)/모듈(module)로 구성되어 있다.
torch.nn네임스페이스는 신경망을 구성하는데 필요한 모든 구성 요소를 제공합니다.
PyTorch의 모든 모듈은nn.Module의 하위 클래스(subclass).
신경망은 다른 모듈(계층; layer)로 구성된 모듈이다.
이러한 중첩된 구조는 복잡한 아키텍처를 쉽게 구축하고 관리할 수 있다.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
Raw 예측 값들을 softmax 함수를 통과시켜 예측 확률을 구한다. 직접 forward 함수를 호출해서는 안된다
Model Layers
input_image = torch.rand(3,28,28)
print(input_image.size())
FashionMNIST 모델의 계층을 살펴보기 위해 28 * 28 크기의 이미지 3개로 구성된 배치를 불러온다.
nn.Flatten
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
28 * 28 의 2차원 이미지를 784의 연속된 배열로 변환
nn.Linear
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
weight 와 bias를 사용하여 선형변환 하는 단계
nn.ReLU
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")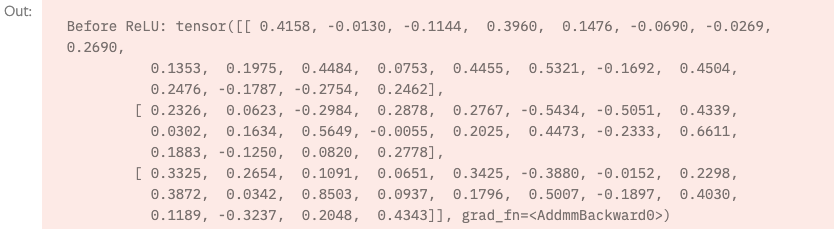

ReLU 와 같은 비선형 activation 함수를 사용하여 mapping을 진행
nn.Sequential
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)데이터를 순차적으로 전달시켜주는 모듈의 컨테이너
nn.Softmax
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)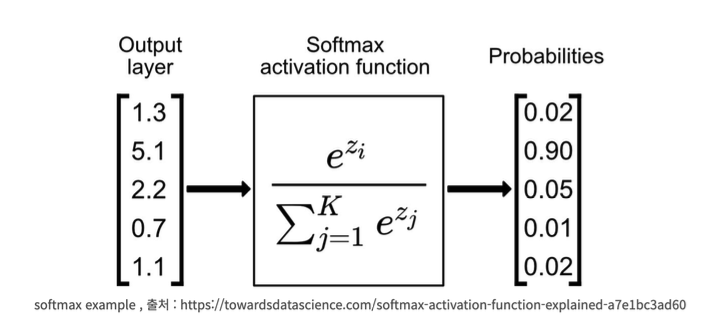
Raw 데이터 값을 [0, 1] 사이의 범위로 변환하여 출력해주어 확률처럼 만든다
Model Parameters
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")
신경망 내부의 모델들은 자동으로 파라미터화 되고 최적화된 weights 와 bias 에 연관된다.
이 파라미터들은 자동으로 추적되며 parameters 또는 named_parameters로 추적 가능하다.
출처 : PyTorch Tutorials https://tutorials.pytorch.kr/beginner/basics/data_tutorial.html
https://tutorials.pytorch.kr/beginner/basics/transforms_tutorial.html
https://tutorials.pytorch.kr/beginner/basics/buildmodel_tutorial.html

아주 유용한 정보네요!