Going deeper with convolutions
요약
"인셉션Inception"이라는 이름의 deep CNN 아키텍처를 제안한다. 인셉션은 ImageNet 대규모 시각 인식 대회 2014(ILSVRC14)에서 분류와 검출 부문에서 최신의 기술 수준을 제시했다. 이 아키텍처에서 제일 중요한 달성 사항은 네트워크 내의 계산해야할 리소스들을 더 나은 방법으로 사용했다는 점이다. 이는 네트워크의 깊이나 너비는 키우면서도 계산에 필요한 비용을 일정하게 유지하는 정밀한 설계 덕에 가능하다. 품질을 최적화하기 위해 아키텍처에 대한 결정들은 헤비안Hebbian 원칙과 대규모 처리의 직관을 바탕으로 내려졌다. 우리가 ILSVRC14에 출품한 출품작 중 하나는 GoogLeNet으로, 계층이 22개나 되는 깊은 네트워크이며, 분류와 검출 부분에 출품을 했다.
01 서론
지난 3년간 심화학습의 발전으로 더 견고한 convolutional 네트워크나 이미지 인식과 물체 검출의 품질이 급격하게 발전하고 있다. 좋은 소식은 최근 이러한 발전이 하드웨어의 발전이나, 더 많은 데이터 집합이나 더 큰 모델 덕분이라기 보다는 새로운 아이디어, 알고리즘, 그리고 발전한 네트워크 아키텍처 덕분이라는 것이다. 예를 들면 ILSVRC 2014 대회에서 검출을 위한 목적의 분류 데이터를 제외하고는 좋은 성능을 보인 출품작들은 다른 새로운 데이터를 사용 하지 않았다. 우리의 GoogLeNet은 2년 전 우승한 Krizhevsky의 아키텍처보다 12배나 덜 매개변수를 사용하면서도 더욱 좋은 정확도를 보였다. 물체 검출에서의 좋은 결과는 deep한 네트워크나 거대한 모델도 있지만, Girshick의 R-CNN 알고리즘과 같은 깊은 아키텍처와 고전 컴퓨터 비전과의 시너지 덕도 있다.
최근 모바일과 임베디드 컴퓨팅의 발전으로 우리의 알고리즘의 효율, 특히 그 전력과 메모리 사용이라는 면에서 중요성을 얻고 있다. 이 논문에서 제안하는 deep 아키텍처의 설계에는 단순히 정확도라는 숫자에만 집중하지 않고 이러한 점도 고려하고 있다는 점을 알아주기 바란다. 대부분의 실험의 경우 모델들은 추론 시간 때 15억 개의 곱셈/덧셈이라는 계산 비용에 맞추도록 설계가 되어 단순히 학술적인 관심사 뿐만 아니라 실제 용도로도, 심지어는 더 큰 데이터 집합을 대상으로도 합리적인 비용으로 사용할 수 있다.
이 논문에서 우리는 인셉션이라는 코드네임의 컴퓨터 비전을 위한 효율적인 DNN 아키텍처에 집중할 것이다. 이 이름은 Lin의 논문에 나온 네트워크와 인터넷의 유명 밈인 "우리는 더 깊숙히 들어가야해"와의 연관성에서 착안하였다. 우리의 경우 "deep"이라는 단어는 두 가지 의미로 사용된다. 우선 우리가 "인셉션 모듈"의 형태로 새로운 조직 level을 소개한다는 점이 있고, 또한 직접적인 의미로 네트워크의 깊이가 깊어졌다는 의미 두 가지이다. 일반적으로 인셉션 모델은 Arora의 논문의 이론에서 영감과 가이드라인을 얻은 이 논문의 논리의 정점이라고 볼 수 있을 것이다. 이 아키턱처의 장점들은 ILSVRC 2014 분류 및 검출 대회에서 현재 최신 성능보다 더 나음을 보여 실험적으로 증명이 되었다.
03 동기와 고수준 고려사항들
DNN의 성능을 높이는 가장 단순하면서 정확한 방법은 크기를 키우는 것이다. 이는 네트워크의 깊이, 즉 계층의 개수와 너비, 즉 각 계층에서 유닛의 개수를 의미한다. 이는 특히 대규모의 라벨링된 훈련 자료를 사용할 수 있을 때 고수준 모델을 훈련하기에 더 쉽고 안전한 방법이다.
허나 이 방법은 두 가지 주요 단점이 존재한다.
규모가 크다는 것은 보통 매개변수의 개수가 더 많다는 의미이며, 이 때문에 덩치가 큰 네트워크는 특히 훈련 집합에서 라벨된 예시가 제한적일 때 과적합에 취약하다. 고품질의 훈련 집합을 만들기엔 매우 어렵고 비싸고, 특히나 그림1에 소개되듯 ImageNet(부류가 1000개인 ILSVRC의 부분집합에서도)의 visual 카테고리의 매우 지엽적인 부분을 구분해야할 땐 사람인 전문가가 필요할 것이다. 그렇기에 이는 매우 큰 병목 현상을 일으킬 것이다.

네트워크 규모를 증가시킬 때 발생하는 또다른 단점은 계산 자원의 급격한 증가다. 예를 들어 deep vision 네트워크의 경우 두 개의 convolution 계층이 연쇄될 때 그들의 필터의 값이 증가하는 순간 제곱수만큼 계산량이 증가한다. 만약 이렇게 추가된 용량이 비효율적으로 사용된다면(대부분의 가중치들이 사실상 0과 가까워진다면) 엄청난 계산량이 낭비 되는 것이다. 실제로 실제 결과의 품질을 늘리는 것이 주 목적일 때도 계산 비용은 언제나 한정적이며 규모를 무분별하게 늘리는 것보다는 효율적으로 계산 자원을 배분하는 것이 더 낫다.
이 두 가지 문제를 해결하는 근본적인 방법은 convolution에서도 fully connected에서 sparsely connected 아키텍처로 옮기는 것이다.
생물학적 시스템을 모방하는 것 뿐만 아니라 Arora의 논문에 나온 혁신적인 방법에서 나온 이론적 견고함을 더하는 것이다. 그들의 대표적인 결과는 데이터 집합의 확률 분포가 매우 크고 sparse한 DNN으로 표현될 수 있다면 최적의 네트워크 위상은 계층을 쌓을 때 직전 계층의 활성 함수의 상관관계 통계와 상당히 상관관계가 높은 출력값을 갖는 클러스터링한 뉴런을 분석하면서 구성할 수 있다. 강력한 수학적 증명은 강력한 조건을 요구하지만 이 구문이 잘 알려진 "같이 잘 맞는 뉴런은 서로 연결되어있다"는 Hebbian 원칙과 잘 알맞기 때문에 실제로는 덜 강력한 조건에서도 근본적인 아이디어가 적용 가능함을 생각해볼 수 있다.
05 GoogLeNet
ILSVRC 14 대회에 출품할 때 팀 이름을 GoogLeNet으로 정했다. 이 이름은 Yann LeCun의 혁신적인 LeNet5 네트워크에 대한 경의의 표현이다. GoogLeNet을 대회 출품할 때 인셉션 아키텍처의 한 구현 방법으로서 사용했다. 또한 더 깊고 넓은 인셉션 네트워크를 사용했다. 이는 품질은 덜하더라도 앙상블에 추가했을 땐 더 좋은 결과를 보였다. 이 네트워크에서 아키텍처적인 매개변수들의 영향이 상대적으로 미미하기 때문에 이 네트워크의 세부사항은 여기서 생략하도록 한다. 밑에 가장 성곡적이었던 구현 방법(GoogLeNet)을 표1에 설명해놓았다. 이와 동일한 위상(샘플링 방법만 다르게 훈련되었다)이 우리 앙상블의 7개 중 6개에 적용되었다.
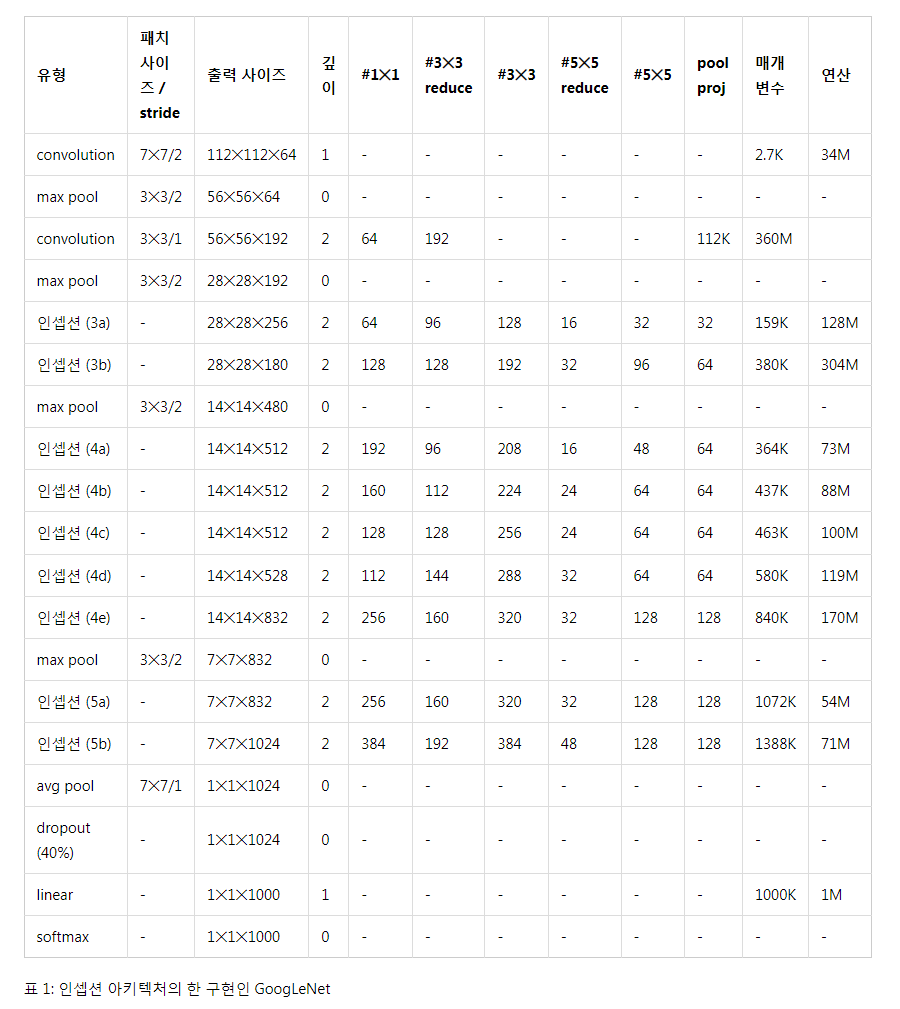
인셉션 모듈 안을 포함한 모든 convolution들은 rectified linear 활성을 사용한다. 네트워크의 receptive field의 크기는 224x224이며 RGB 색 채널에서 평균 뺄셈을 사용한다.
"#3x3 reduce"와 "#5x5 reduce"는 3x3와 5x5 convolution 이전에 사용된 축소 계층의 1x1 필터의 개수를 의미한다. Pool proj 열의 내장된 max-pooling 이후에 있는 projection 계층의 1x1 필터의 개수를 확인할 수 있다. 모든 축소 / projection 계층은 rectified linear 활성을 사용한다.
이 네트워크는 계산적 효율성과 실용성을 중심으로 설계되었으므로 inference는 한정된 계산 자원을 갖는, 특히나 메모리 수준이 낮은 디바이스에서도 실행될 수 있다. 이 네트워크는 매개변수를 갖는 계층만 세었을 때는 22층만큼 깊다(매개변수 없는 계층도 세면 pooling까지 포함해 27층이다). 실제 네트워크를 구성하는데 사용된 독립적인 계층(빌딩 블록과 독립적으로)은 100개다. 허나 이 숫자들은 시스템이 사용하는 기계학습 인프라에 달려있다. 분류기 이전에 평균 pooling 계층을 사용하는 것은 이 논문에 기반을 두고 있으나 우리의 구현 방법은 추가적인 선형 계층을 사용한다는 점에서 구분된다. 이를 통해 우리의 네트워크를 다른 라벨 집합에 대해 손쉽게 적응하고 미세 조정할 수 있게 해주나, 이는 대부분의 경우 편의성을 위함이고, 큰 영향이 없을 것으로 예상한다. FC 계층에서 평균 pooling 계층으로 전환하니 top-1 정확도를 0.6% 정도 증가했으나 dropout의 중요성은 FC 계층이 없음에도 중요한 역할을 보였다.
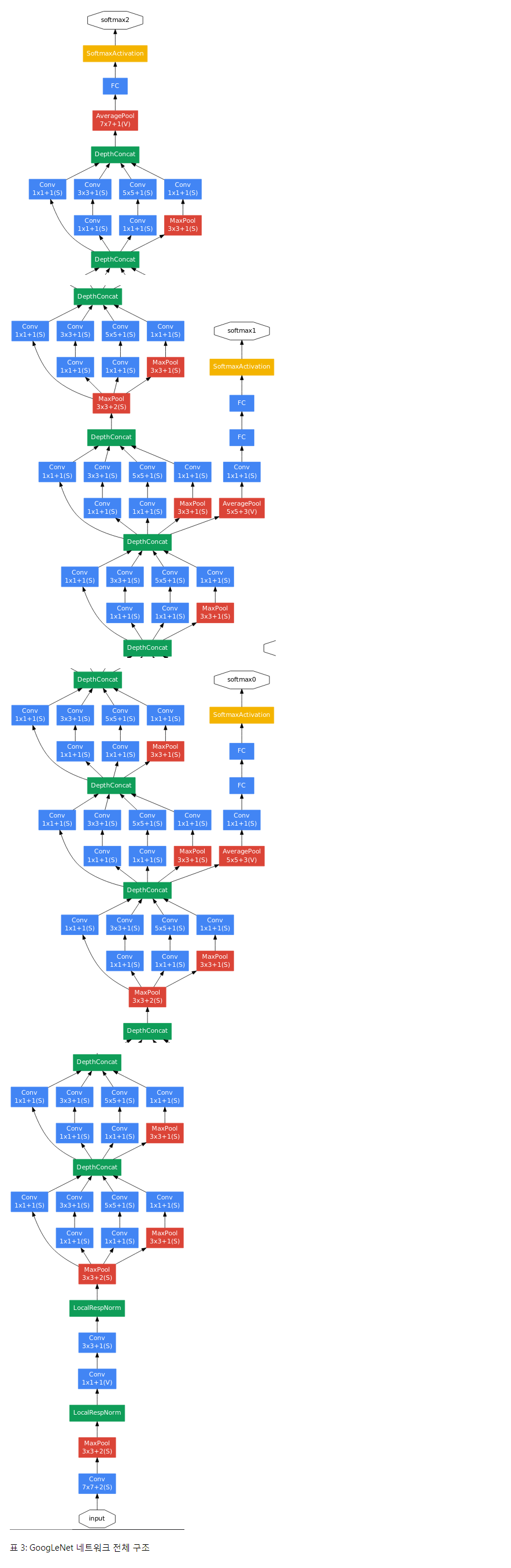
상대적으로 네트워크의 깊이가 깊으므로 모든 계층에 경사를 효과적으로 역전파하는 부분은 언제나 큰 고민이었다. 한가지 흥미로운 통찰은 이 분야에서 상대적으로 얕은 네트워크의 강력한 성능을 봤을 때 네트워크의 중간 계층에서 생성한 특징은 매우 구체적이어야한다는 것이다. 이러한 중간 계층에 예비 분류기들을 추가함으로써 분류기의 저수준에서 분류를 좀 더 원활하게 할 수 있으며 역전파되는 경사 신호를 증폭시키고 추가적인 regularization을 제공할 수 있다. 이러한 분류기들은 작은 convolutional 네트워크의 형태를 띠어 인셉션 (4a)와 (4d) 모듈의 출력 위에 쌓는다. 훈련 도중 생긴 오류들은 할인된(?) 가중치(예비 분류기의 오류는 0.3으로 가중되었다)와 네트워크의 총 오류에 더해진다. Inference 순간에는 이러한 예비 네트워크들은 무시한다.
예비 분류기를 포함한 주변의 추가적인 네트워크의 추가적인 구조는 다음과 같다.
- 5x5 필터 사이즈와 stride 값이 3이며 (4a)에서는 출력이 4x4x512이고 (4d)에서는 4x4x528인 평균 pooling 계층
- 필터가 128개인 차원 축소용 1x1 convolution과 rectified linear 활성
- 유닛 개수 1024인 FC 계층과 rectified linear 활성
- 70% 비율로 출력 drop하는 dropout 계층
- softmax 오류를 분류기로 사용하는 선형 계층 (메인 분류기와 같이 1000개의 부류를 예측하지만 inference 땐 제거된다)
결과적으로 얻은 네트워크는 그림 3에서 확인할 수 있다.
09 결론
우리의 결과는 추측한 최적의 sparse 구조를 준비된 밀집된 빌딩 블록을 통해 근사하는 것은 컴퓨터 비전을 위한 신경망의 성능을 개선하는 현실적인 방법임에 대한 강력한 증거가 되는 것으로 보인다. 이 방법의 최대 장점은 얕으면서 넓은 네트워크에 있어 계산 소요가 얼마 증가 되지 않았음에도 성능이 개선이 되었다는 점이다. 또한 우리의 검출 출품작은 context 혹은 bounding box 회귀를 사용하지 않았음에도 우수한 성능을 보였으며 인셉션 아키텍처의 강력함에 또다른 증거가 된다는 점에 주목할 필요가 있다. 비슷한 수준의 결과가 깊이나 너비가 비슷한 더 확장된 네트워크로도 얻을 수 있겠지만 우리의 방법은 더 sparse한 아키텍처로 옮기는 것은 현실적이며 일반적으로 유용한 아이디어임을 보이는 구체적인 증거가 된다. 이는 이후 이 논문에 근간을 둔 자동화 방식을 통한 좀 더 sparse하고 세련된 구조를 생성하는데에 대한 촉망되는 미래가 있음을 보인다.