Very Deep Convolutional Networks for Large-Scale Image Recognition (VGGNet)
Very Deep Convolutional Networks for Large-Scale Image Recognition
1. Introduction(서론)
Convolutional networks(ConvNet)은 이미지 인식 분야에서 ImageNet과 같은 공개된 대규모 이미지 저장소와 고성능 컴퓨팅 시스템 덕에 성공을 했다. 특히 ImageNet 대규모 영상인식 챌린지(ILSVRC)에 나온 고급 deep 영상 인식 아키텍처가 중요한 역할을 했다. ILRSVRC의 경우 고차원 shallow feature encoding에서부터 deep ConvNet 등의 대규모 영상 분류 시스템들의 훌륭한 실험소가 되었다.
ConvNet이 컴퓨터비전에서 흔하게 통용되기 시작하면서 Krizhevsky의 2012년 논문의 원본 아키텍처를 개선해 정확도를 높이려는 몇몇 시도들이 있었다. 예를 들어 ILSVRC-2013에서 가장 성능이 좋았던 모델들의 경우 첫번째 convolutional 계층에 작은 receptive window size와 작은 stride를 사용했었다. 다른 개선사항들은 네트워크에 대한 훈련 및 검증을 전체 영상을 몇가지 크기로 꼼꼼하게 진행했던 것들 등이 있다. 이 논문의 경우 ConvNet의 깊이를 연구 했다. 아키텍처의 매개변수들을 몇 가지 고치고 네트워크에 convolutional(합성곱) 계층을 추가하는 식으로 점진적으로 깊이를 늘렸다. 이는 모든 계층에 적용되는 매우 작은 (3✕3) convolutional 필터 덕에 가능하다.
결과적으로 더 정확한 ConvNet 아키텍처를 얻을 수 있었다. 이 아키텍처는 ILSVRC(ImageNet 대규모 영상인식 챌린지) 분류와 지역화 부문에서 가장 최고 수준의 정확도를 보였을 뿐만 아니라, 다른 영상인식 데이터 집합에 대해서도 상대적으로 간단한 파이프라인의 일부(예시: fine-tuning하지 않은 선형 SVM을 사용한 deep 특징 분류)로 사용되었음에도 훌륭한 성능을 보여, 다른 데이터 집합에도 적용 가능함을 보였다. 모델 중 가장 성능이 좋은 두 모델을 공개해서 연구에 도움이 되고자 한다.
2. ConvNet Configurations(설정사항)
ConvNet에서 깊이를 늘림으로써 발생한 성능 개선을 정확하게 측정하기 위해 ConvNet 계층 설정은 Ciresan의 2011년 논문과 Krizhevsky의 2012년 논문과 같은 원칙으로 설정사항을 설정했다. 2장에서는 ConvNet 설정사항의 일반적인 레이아웃을 보고(2.1장), 검증에서 사용할 세부적인 설정사항들을 보자(2.2장). 설계를 할 때 선택한 부분들에 대해서는 다른 모델들과 비교해서 설명한다(2.3장).
2.1. Architecture(아키텍처: 일반적인 레이아웃)
ConvNet의 입력값은 고정된 크기의 224x224 RGB 이미지이며 전처리는 training set의 각 pixel에 평균 RGB 값을 빼주었다. 입력 이미지는 3x3 filter가 적용된 ConvNet에 전달되고, 또한 비선형성을 위해 1x1 convolutional filters도 적용했다. stride=1이 적용되었고 공간 해상도를 보존하기 위해 padding을 적용했다. 일부 conv layer에는 max-pooling(size=2x2, stride=2) layer를 적용했다.
convolutional layers 다음에는 3개의 Fully-Connected(FC) layer가 있고, 첫 번째와 두 번째 FC는 4096 channels, 세 번째 FC는 1000 channels를 갖고 있는 soft-max layer 이다.
모든 은닉 계층(hidden layer)에는 활성화 함수로 ReLU를 이용했다. AlexNet에 적용된 LRN(Local Response Normalization)은 VGG 모델의 성능에 영향이 없기 때문에 적용하지 않았다.
2.2. Configurations(설정사항: 세부적인 레이아웃)
Table 1에 깊이를 서로 달리한 모델 A~E의 배치가 나와있다. 11~19 범위의 깊이로 실험이 진행되었고, 넓이(channels)는 각 max-pooling layer 이후에 2배씩 증가하여 512에 도달한다.
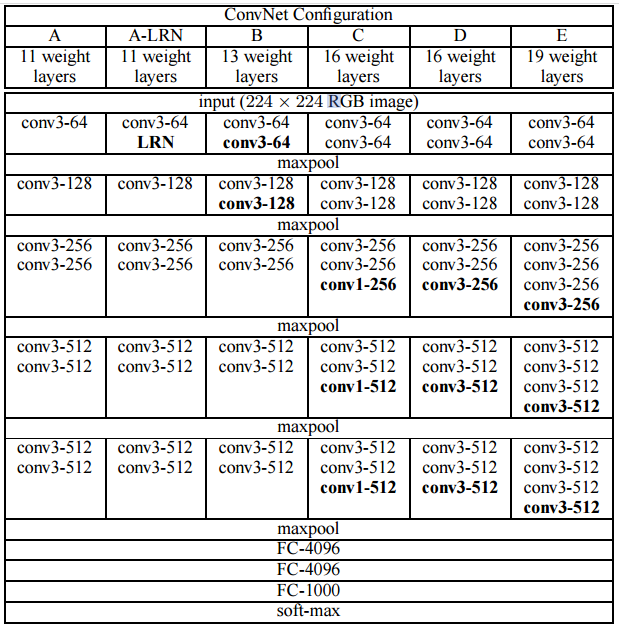
Table2는 각 배치의 parameter(매개변수) 개수가 나와있다.