log-structure memory
정의
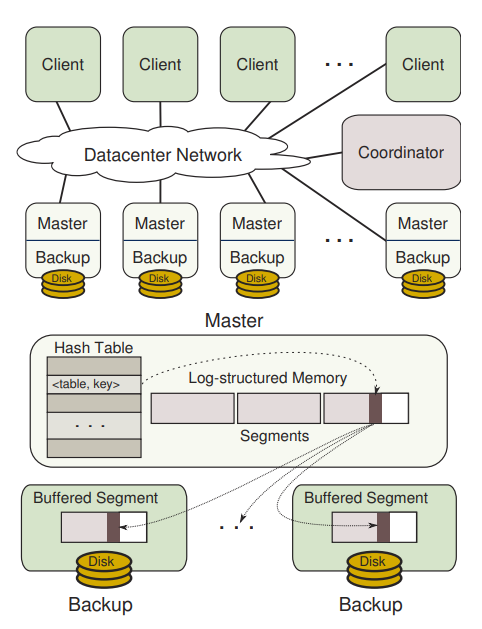
데이터 센터에서는 데이터를 수백~수천에 이르는 노드들을 묶어 DRAM에 데이터를 저장한다. 로그 구조는 이렇게 많은 DRAM을 관리하기 위해 채택한 방법으로, 데이터 센터의 노드들의 메모리를 마스터와 백업 컴포넌트로 나누고, 마스터에는 로그를 두는데 그 안에는 8MB로 이루어진 세그먼트를 둔다.
from usenix: fast14-paper
기존 사례
그리고 기존에 사용하던 객체 할당법과 다르게 새로운 할당법을 사용한다. 기존의 할당법 또한, 분산 메모리 구조를 지원하여 메모리의 확장성을 위해 사용한다는 점은 로그 구조가 추구하는 기준과 비슷하다. 하지만 기존의 할당법은 2가지 종류가 있고 각각은 단점을 가지고 있었는데, 이는 다음과 같다.
- 복사를 이용하지 않는 경우
복사를 이용하지 않는 기존 할당법의 경우, 메모리에 데이터를 캐시하는 방식으로 할당했다. 이러한 방식으로는 Memcached, Redis 등등이 있다. 이 방식은 메모리에 데이터가 한 번 캐시되면, 위치가 변하지 않는 속성 때문에 프레그멘테이션이 발생한다. 또한 메모리 구조를 비효율적으로 활용하기 때문에 메모리 사용률 또한 떨어지게 된다.
- 복사를 이용하는 경우
GC와 같은 것들이 이러한 방식을 이용하게 된다. 메모리에 캐시를 한다는 점은 비슷하지만, 프레그멘테이션을 해결하기 위해 메모리 안을 탐색하면서 빈 공간을 찾고 객체를 복사하여 다시 재정렬한다는 특징이 있다. 이는 프레그멘테이션은 해결하지만, 많은 오버헤드가 발생한다는 단점이 있다.
개선안
이러한 단점을 해결하기 위해 로그 구조를 이용한 새로운 접근법을 사용한다.

먼저 로그가 낭비 되고 있으면, 객체를 복사하여 새로운 로그에 빈 공간 없이 순서대로 붙인다. 이를 하나의 로그 단위로 하여 낭비 되는 세그먼트들에 모두 수행한다.

그런 다음, 각 세그먼트들을 합하여 여러 세그먼트를 하나의 세그먼트로 정리한 후, 남은 세그먼트는 할당 해제 한다. 이후 백업 메모리에 저장하여 로그 정리를 마친다.

장점
이런 방식의 장점은 로그를 통해 메모리를 효율적으로 사용할 수 있으며, 기존 할당의 비효율적인 부분을 극복한다. 그리고 디스크와 같은 구조를 통해 메모리를 단순화 할 수 있다.
