RAMCloud
정의
RAMCloud is a new class of super-high-speed storage for large-scale datacenter applications. It is designed for applications in which a large number of servers in a datacenter need low-latency access to a large durable datastore.
from platformLab
RAMCloud는 데이터 센터의 DRAM을 기존의 HDD나 SDD 대신 사용하는 것이다. 이를 통해, disk의 latency를 극복하면서 상대적으로 큰 저장 공간을 사용할 수 있는 것이다.
배경
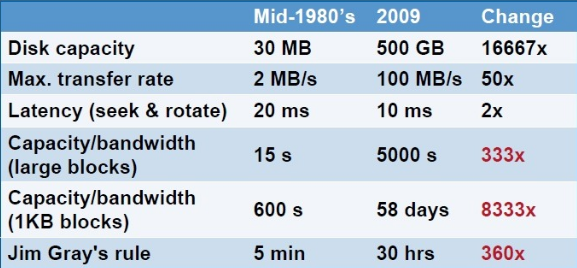
80년대의 디스크 용량은 30MB였다. 하지만 현재에는 몇 TB 수준으로 크기가 증가하였다. 하지만 그에 반해 지연시간은 그 발전의 속도를 따라잡지 못 하고 있다.
특히, HDD 특성 상 회전하는 디스크 위에서 디스크 암이 움직여야 하므로 랜덤 I/O를 위한 접근 지연 시간은 더욱 증가하였다. 80년대 초 15초면 다 읽을 수 있던 것을 지금은 직렬 읽기만 하면 5,000초가 거리고, 랜덤 읽기의 경우 58일이라는 엄청난 시간이 요구된다.
이에 따라 연구자들은 기존 HDD를 대체하기 위해 SSD를 연구해왔고, 이제 SSD는 울트라북, PC 등 널리 이용되고 있다. 하지만, 데이터센터 스케일에서도 SSD를 적용할 수 있을까?
스탠포드대의 연구자들은 램클라우드라는 프로젝트를 통해 SSD나 디스크보다 이제 DRAM을 주요 저장공간으로 활용해야 한다고 역설한다. 이들은 수백, 수천 대의 노드 컴퓨터들을 연결하여 이들의 메인 메모리에 모든 데이터를 저장, 관리 하는 것을 목표로 한다.
개요
짐 그레이의 5분의 규칙이 있다.
짐그레이가 SIGMOD Record에서 언급한 것으로 디스크와 메모리의 접근 시간과 용량을 간단히 수식화하여 약 5분 내 다시 참조될 데이터는 메모리에 올려두는 것이 좋다라고 언급한 것이다.
현대에는 하드웨어의 발전으로 이제는 30시간 내에 재참조 되는 데이터는 메모리에 올려두면 더 좋을 것이라는 결과를 얻게 되었다. 즉, 현재는 가급적이면 모든 데이터를 메모리에 올려두는 것이 효과적이라는 사실이다. 사실 이러한 현실은 이전의 짐 그레이의 예측과도 일치한다.
Memory becomes disk, disk becomes tape, and tape is dead.
이제 현대에는 Disk를 DRAM으로 대체하고자 하는 노력을 하고 있다.
장단점
메모리를 디스크처럼 쓰는 경우 가질 수 있는 장점은 매우 많다.
접근 지연 시간이 현격하게 줄어든다
현재 데이터 센터를 이용하는 인터넷 서비스들은 인터넷 스케일이라는 규모가 큰 request를 처리하는 것을 목적으로 한다. 따라서, 단일 노드로 구성되지 않고 데이터 센터에 많은 노드들을 네트워크로 연결하고 이를 통해 부하를 분산하는 분산 시스템이라는 특성을 가진다. 또한 웹 서비스와 해당 서비스가 처리/제공하는 데이터가 서로 다른 노드에 위치하는 구조로 인해 접근 지연 시간이 단일 시스템 구조보다 느리다. 메모리를 디스크처럼 쓰는 경우 이러한 환경에서도 접근 지연 시간을 줄일 수 있다.
온라인 트랜잭션 처리 비용 감소
동시 수행되어야 할 트랜잭션의 수가 많을수록 그만큼 트랜잭션들의 일관성을 보장하기 위한 비용은 더 높아질 것이다. 새 트랜잭션의 도착 비율은 시스템의 스케일이 커가면서 계속 커지게 된다. 하지만 각 트랜잭션의 운용 기간은 접근 지연 시간이 낮아짐에 따라 크게 개선되며 따라서 동시 수행되는 트랜잭션 수를 줄일 수 있다.
사실 이러한 아이디어는 상주현 DBMS(in-memory DBMS)라는 형태로 구현되어 왔다. 하지만 상주형 DBMS가 몇 개의 노드를 이용하는 것에 국한되었던 것에 비해 RAMCloud는 최소 수백대의 노드들의 메모리를 하나의 virtual storage로 보고 여기에 데이터를 저장시킨다는 점이 차이가 있다.
Memory Caching vs RAMCloud
인터넷 규모의 ISP들은 Memcached, Redis와 같은 분산 메모리 캐싱을 지원한다. 사실 램클라우드는 인터넷 규모의 서비스 제공에 있어 확장성(Scalability)을 제공하기 위해 분산 메모리 구조를 지원한다는 점에서는 memcached와 같은 기존 분산 캐싱 기술들과 크게 유사하다. 차이점은 램클라우드는 캐싱이 아닌 아예 데이터를 통채로 메모리에 올리겠다는 것이다.
memcached와 같은 경우에는 캐시된 데이터와 MySQL에 저장된 실 데이터 간의 불일치에 따른 일관성 유지 관리의 복잡성이 대두될 수 있다. 또한 데이터가 캐싱되기 쉽지 않은 경우에는 결국 디스크 접근을 필요로 한다. 데이터 접근의 분데이터가 메모리에 캐싱되어 있다면 메모리 접근 지연 시간을 보장할 수 있지만 만약 해당 데이터가 메모리에 캐싱되어 있지 않으면, 디스크에 접근을 하면서 접근 지연 시간이 늦어질 것이다.
단일 사이트에서 동작하도록 설계도니 DBMS의 제한된 확장성은 여러 곳에서 이미 지적된 바 있다. 이러한 문제를 해결하기 위한 현재의 대표적인 기술은 NoSQL이라 볼 수 있다. 하지만 NoSQL은 확장성을 위해 기존의 DBMS가 가졌던 주요한 기능, 관계형 모델 대신 단순한 KV 모델과 제한된 일관성 지원 정책 등의 한계를 갖는다. 그리고 이들 또한 대부분 디스크에 기반한 저장소를 기준으로 설계되어 있으며, 관계형 DBMS만큼 범용적이지도, 호환적이지도 않다.
RAMCloud는 이러한 문제들을 해결하면서, 보다 큰 확장성과 더 짧은 접근 지연 시간을 제공하는 범용의 저장 시스템을 제공한다. 하지만 이렇게 모든 데이터를 메모리에 올려놓았을 때 문제점은 메모리 자체의 휘발성에 따라 장애 시 데이터가 유실될 수 있다는 점이다. 이에 대한 해결책은 크게 다른 데이터 노드의 메모리에 데이터를 복제해 두거나 디스크에 로깅을 생각해 볼 수 있다.
데이터들을 복제해서 모두 메모리에 두는 방식은 synchronous I/O를 가지고도 고성능을 보장할 수 있는 장점이 있지만, 상대적으로 비싼 DRAM이라는 저장장치의 공간을 크게 낭비하게 된다. 반대로, 데이터의 복제나 로그를 디스크에 위치시키는 것은 디스크의 접근지연시간에 따른 비효율성을 피할 수 없다. 때문에 이들은 메모리에의 로그 복제와, 메모리에서 디스크로의 비동기적인 data flushing을 통해 이 문제를 해결하려고 하고 있다.
참고자료: 재미있게 살자~
