Transformer Block
We talked about attention method. Now let's construct the architecture of transformer!
First, it uses Multihead Self-Attention method to get the context of the input sentence. Also, it adds residual connection for grandient stabilization.
Next, it normalize the context vectors.(softmax)
Third, it applies MLP(Multi-Layer Perceptron), usual fully-connected network. Residual connection is also applied to stabilize gradient.
Finally, it normalize the outputs.
Using transformer blocks, we can consist complex LLM such as GPT-3.
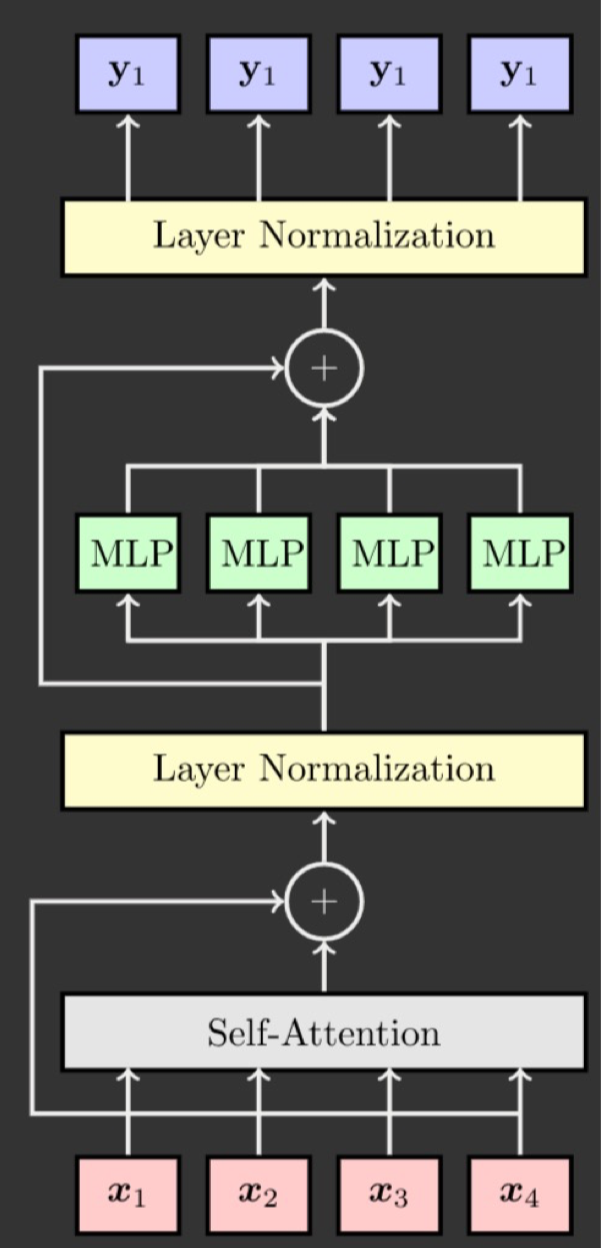
Transformer Model Implementation

KAIST CS Major