
복습
컴퓨터
CPU, 메모리, HDD, I/O
운영 체제
윈도우(탐색기 -> 클릭), 리눅스(쉘 -> 명령어), 안드로이드, IOS
명령어
이름을 입력해서 실행하는 프로그램
서버
서비스를 제공하는 프로그램
클라이언트
서비스를 이용하는 프로그램
프론트 엔드와 백 엔드는 어떤 기준으로 나누는가????
누구의 컴퓨터에서 실행이 되는가프론트 엔드
HTML, CSS, JS
VUE 프레임워크백 엔드
자바
스프링부트IP주소 : 멀리 있는 컴퓨터를 찾아가는 주소
공유기(네트워크 장치)에 설정된 주소에 맞는 주소로 설정해야 한다.
일반적으로 앞자리는 같고 뒷자리만 다르게
사설 IP : 공유기 내부에서 사용하는 IP주소
공인 IP : 공유기 외부에서 사용하는 IP주소, 공인 IP 하나를 공유해서 사용하는 것
ipv4
subnet mask
default gateway
포트번호 : 남의 컴퓨터가 내 컴퓨터에서 실행 중인 특정 프로그램을 찾아가는 번호
도메인 주소 : IP주소를 외우기 힘드니까 글자 형식의 주소로 매핑시킨 것
DNS 서버 : 도메인 주소를 IP주소로 변경
HTTP 요청 메소드 : GET(데이터가 주소에 포함), POST(데이터가 HTTP 바디에 포함)
공유기에 적어놓는 설정이 포트포워딩설정
시작하기전
내가 무엇을 하고 있는지 생각하면서 하자!
Database
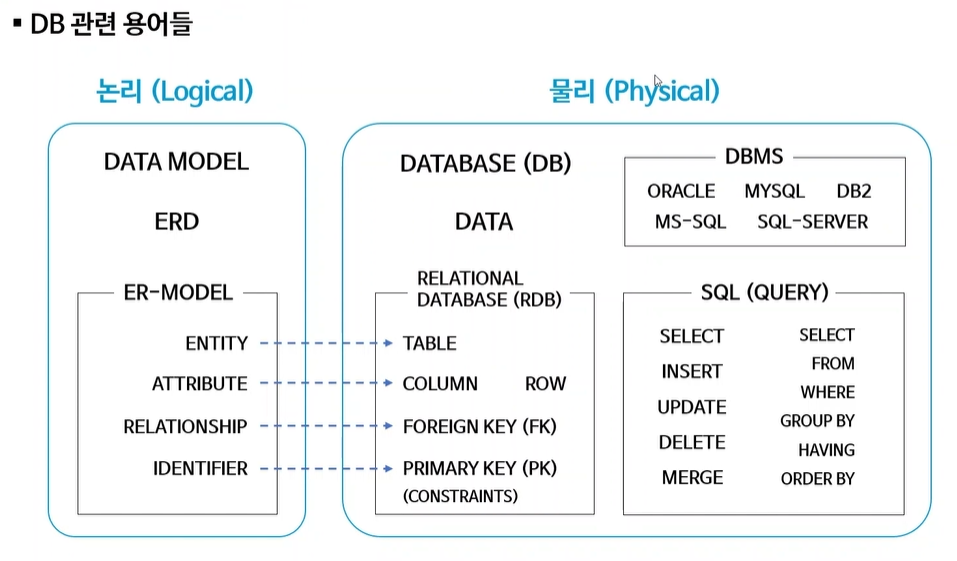
물리적관계(Physical) : 물리적관계는 실체가 있는 것
논리적관계(Logical) : 논리적관계는 물리적관계를 만들기 전 설계단계
Database?
: 데이터베이스는 파일이다. 잘 저장하기 위해서 데이터베이스를 사용하고, 데이터를 효율적으로 관리하기 위해서 데이터들 사이에서 관계를 맺어둔 파일이다.
그럼 파일은 무엇인가?
: 확장자는 파일의 이름.
Database의 특징
-
자료추상 : 자료를 추상적으로 저장한다. 즉,공통적인것, 비슷한 것만 저장한다.
ex) 이름: 심준보, 나이: ? , 성별: 남, 키: 176, 몸무게: 65kg, 손톱길이: 0.3cm, 안경착용 : 유한 사람의 정보를 저장하고, 다른 사람들의 정보를 저장하려고 한다. 이럴때 이런 디테일한 정보들을 저장하기 어렵다. 공통적인 성질들만 뽑아서 대충 저장하자 라고 하는 것이 데이터베이스의 특징인 자료추상이다.
NoSql은 저런 디테일한 정보까지 저장하자!
-
자료독립 : 데이터와 프로그램의 독립성을 유지. 데이터와 데이터를 사용하는 프로그램이 독립적이다. 데이터의 형태가 아무리바껴도 프로그램이 바뀔필요가 없다. 프로그램이 바뀌어도 데이터의 형태가 바뀔필요가 없다.
ex) 데이터와 프로그램의 독립성이 유지되지 않는다면?
자료를 pdf로 다 뿌렸는데 자료를 pptx로 바꾼다면? 자료를 보기위해 프로그램을 새로 깔던가 방법을 바꾸어야한다. -
자기정의 : 자료의 구성과 내용을 DB자신이 저장 및 관리. 데이터는 엑셀처럼 표로 저장하는데, 자기자신을 구성하는 정보나 형식같은 것들도 자기자신이 정의를 하고있다.
Database의 장점
- 데이터의 논리적 독립성
- 데이터의 물리적 독립성
- 데이터의 무결성 유지
- 데이터 중복성 최소화 : 관계를 맺어서 데이터를 가져가는 것이기 때문에 복사나 중복같은 것이 없다.
- 데이터 불일치 제거 : 데이터가 중복되는 것을 최소화
Database란?
파일시스템 : 파일은 HDD에 저장된다. 파일을 효율적으로 쓸수있게 해주는것이 파일시스템
계층형 : 폴더형태가 계층형이다. 리눅스의
관계형 : 가장 많이 사용하고 있다.
파일시스템 안에다가 데이터베이스 파일을 만들어서 관리하는데 관계형으로 관리를 한다.
DBMS(Database Management System)
데이터베이스 파일을 열어서 볼 수 있는, 또는 관리하는 프로그램을 DBMS라고 한다. 데이터베이스 서버이다. 데이터베이스 서비스를 제공하는 프로그램인 것.
DBMS의 종류
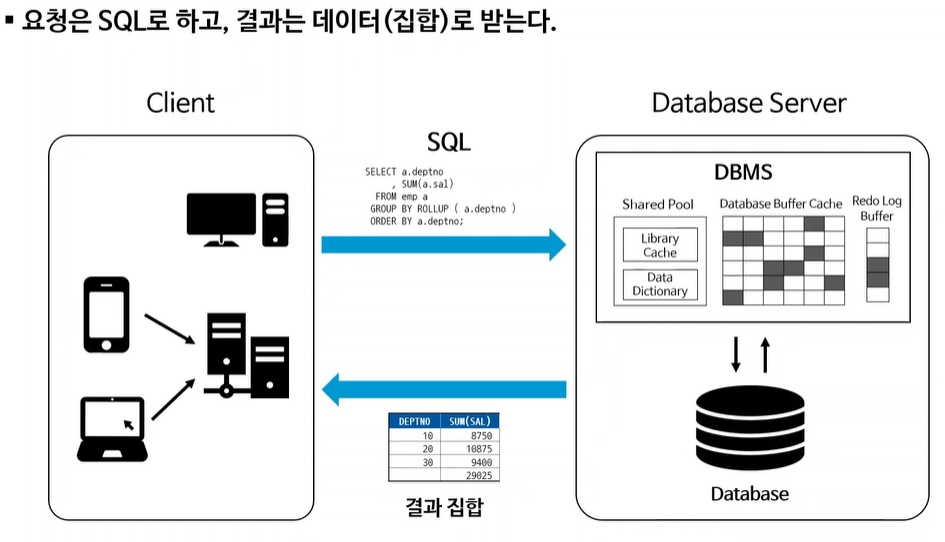
클라이언트에서 SQL문으로 DBMS라고 불리는 소프트웨어에 요청을 보내고 DBMS에서 데이터를 찾아 결과를 다시 클라이언트에 보내준다.
우리는 MariaDB를 사용!
DBMS의 공통기능
- 정의 기능(Definition) : 데이터를 표로 저장하는데 그 표 형태를 만드는 것이 정의기능.
- 조작 기능(Manifulation) : 표를 만들었으면 데이터를 넣거나, 조회하거나, 삭제하거나 등의 데이터 자체를 조작하는 기능
- 제어 기능(Control) : 데이터를 관리하기 위해서 권한설정을 하거나 데이터를 백업하거나 복구하는 기능.
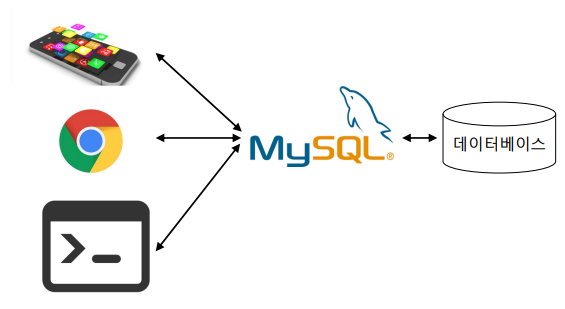
DBMS가 데이터베이스를 전부 관리하고, 접근하고 싶으면 데이터베이스 서버에 접근해야하고 클라이언트가 데이터베이스 저장을 위해 서버를 사용하는 형태가 될것이다.

백엔드서버와 DB서버를 연결할때는 서버를 통해서 이용하도록 만들어놨기 때문에 어떤프로그램이든 경로를 적어줘야한다.

ip주소, 비밀번호, 이름이 꼭 필요하다.
DB의 스키마
스키마 - 구조. 데이터베이스는 표자체가 스키마 라고 생각하면 된다. DB가 스키마 라고 생각하면 된다.
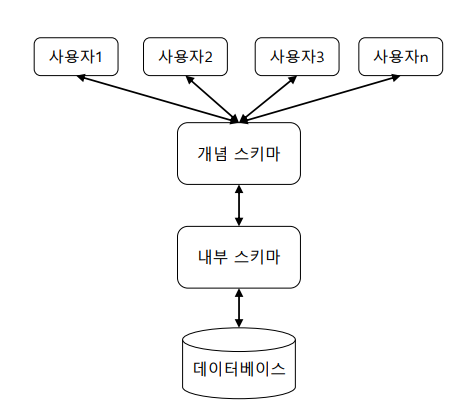
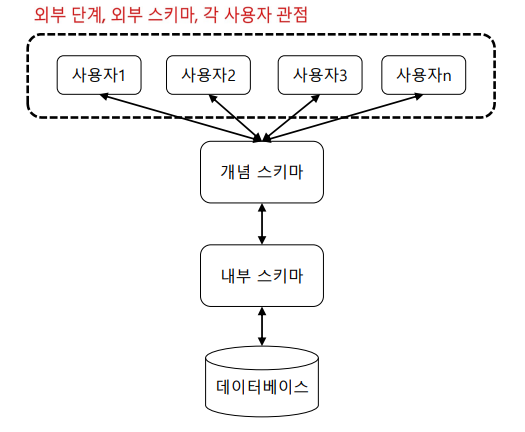
개념스키마 : 데이터베이스
내부스키마 : 데이터베이스는 결국 파일이다 보니, 하드디스크에 어떻게 저장되는지
Data Modeling
사람정보를 어떻게 데이터베이스에 저장하지? 공통적특징을 어떻게 뽑아서 저장하지 했을때, 현실세계의 데이터 구조를 데이터 구조로 저장시키는 중간과정.
현실세계의 데이터 구조를 데이터구조로 기술한다 -> 객체지향과 비슷한 개념.
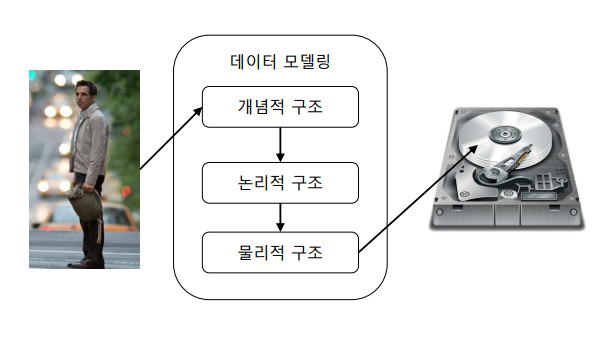
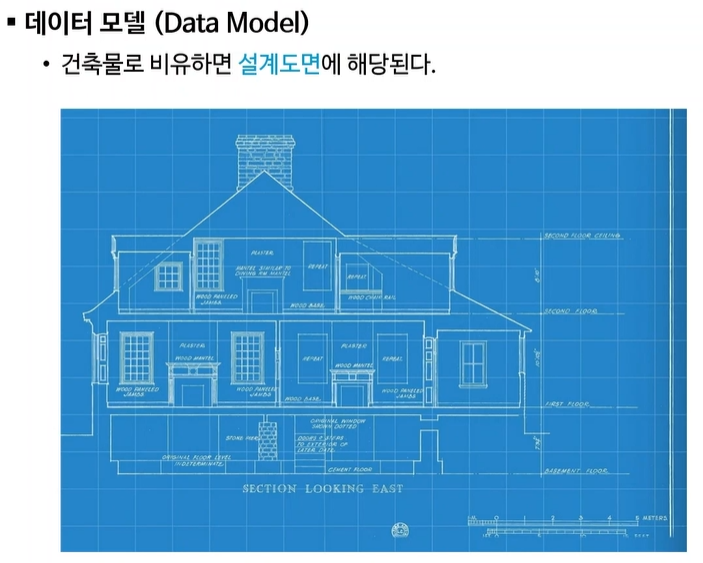
DataBase : "건축물"
Data Model :
"건출물"을 짓기 위한 "설계도면".
현실세계를 database로 구축할 수 있도록 "추상화"한것
추상화: 어떤 것을 뽑아서 단순화 시킨 것
- 복잡한 현실세계(기업의 비지니스)를 약속된 표기법에 의해 단순화시켜 표현함
- database에 저장하기 위해 애매모호함을 제거하고 명확화하여 기술
Data Modeling :
현실세계를 약속된 표기법에 의해 표현하는 과정
database를 구축하기 위한 분석/설계의 과정분석 :
비지니스를 분석하는 것
1. 데이터베이스가 없는 새로운 시스템을 만드는 경우
2. 데이터베이스가 있고, 기존 데이터베이스를 분석해서 새로 넘어가는 경우(어느정도 규모가 있는 회사의 경우, database는 존재하고 있다 기존의 database를 분석해서 새로운 database로 바꾸는 경우(AS-IS : 기존database/To-BE : 새로만들 database / As-Is DB를 먼저 분석해서 기존의 database의 구조를 파악하고 추가적 비지니스구조를 파악해서 To-Be DB 설계 단계로 넘어간다.)
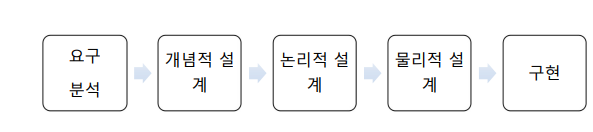
설계과정
-
요구분석 : 이커머스를 예로 들면 상품저장, 회원기능, 회원구매내역, 등 어떤것이 필요한지를 분석. 정답이 없고, 고객이 요구하면 미팅을 통해서 요구를 분석한다.
요구분석의 결과물 : 요구사항명세서(글) -
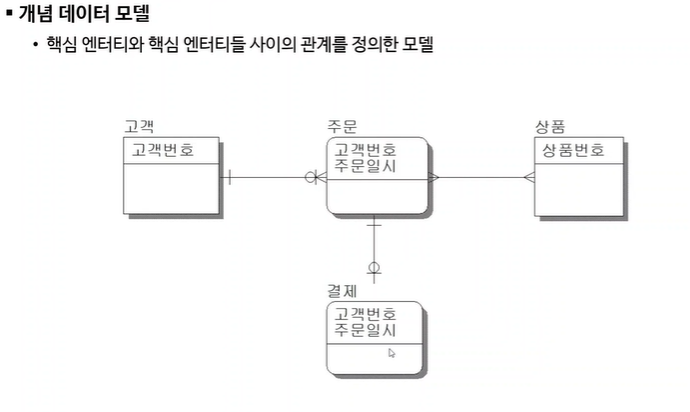
개념적 설계 : 데이터를 구조화, 정형화 시키기 위해 추상적인 개념으로 표현하는 과정. 비지니스에서 가장 중요한 핵심 비지니스만 뽑아서 간단하게 표현하는 것. 추상화 수준이 높은 단계인데 추상화 수준이 높다는 말은 간략화를 많이 시킨다는 의미. 주문을 저장할때 어떤걸 넣어야 좋은지 설계하고 주문은 관계, 사용자, 고객은 NTT 등 그림으로 만들어서 다이어그램으로 표현함.
개념적설계의 결과물 : ER다이어그램(글을 그림으로 표현)
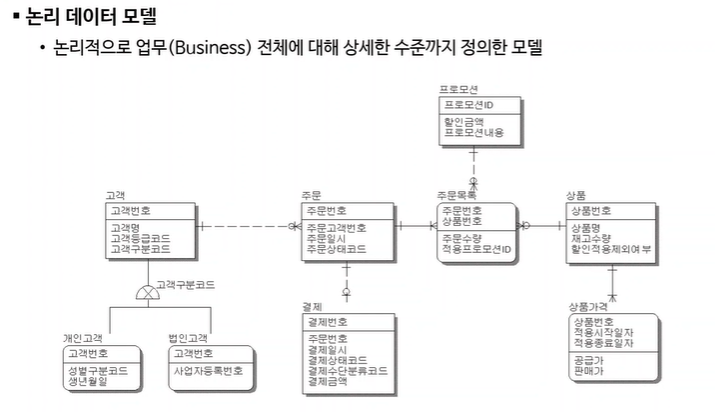
- 논리적 설계: 본격적인 설계단계. Entity, 속성, 관계, 식별자(데이터모델요소들) 등을 정의함으로써 데이터 구조를 논리적으로 구체화하는 과정.전체 비지니스가 다 드러나야함. 개념적 스키마를 테이블과 같은 논리적 데이터모델을 이용해서 논리적구조로 표현, 정규화시키는 것. 표형태가 나옴. 표에 데이터를 저장할때, 조건을 걸어놓는것. 이름은 몇글자까지만 저장하게 하는게 좋은지. 형태는 어떻게 할것인지 등등. 여기서 정규화normal form을 왜해주냐면 안해주면 표에 데이터를 저장할때 문제가 생김. 데이터를 저장하거나 수정하거나 삭제하거나 문제가 생김. 문제가 없는 일반적형태로 만들기 위해서 정규화를 해주어야한다. 문제가 생기지 않을때까지 정규화를 해주어야한다. 하나의 표에 너무 많은 데이터를 저장하면 문제가 생기므로 그 표를 두개로 나누는 것이 정규화이다.
논리적설계 결과물 : 릴레이션스키마, 데이터타입, 길이, null값 허용여부, 기본값, 제약조건 등을 세부적으로 결정.
- 물리적 설계: HDD나 OS의 특성을 고려해 인덱스 구조나 내부저장구조등에 대한 물리적 구조를 설계. 서버를 몇개를 쓸건지 등 DBMS가 결정되는 단계가 물리적 데이터를 설계하는 과정에서 결정된다.
물리적 설계 결과물 : 물리적스키마
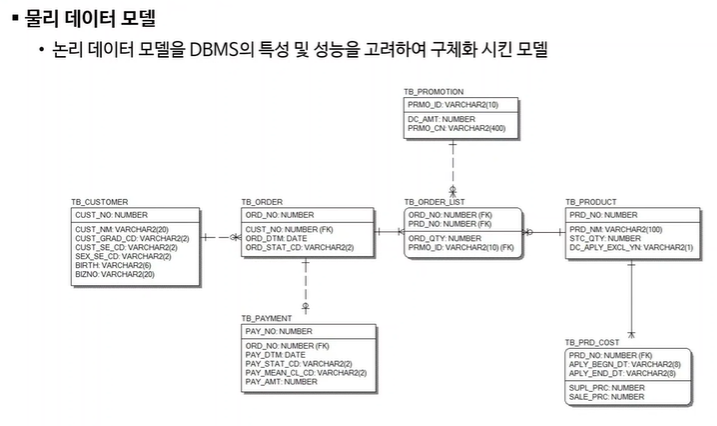
- 구현 : SQL을 사용하여 DBMS를 통해 실제DB를 만드는 과정
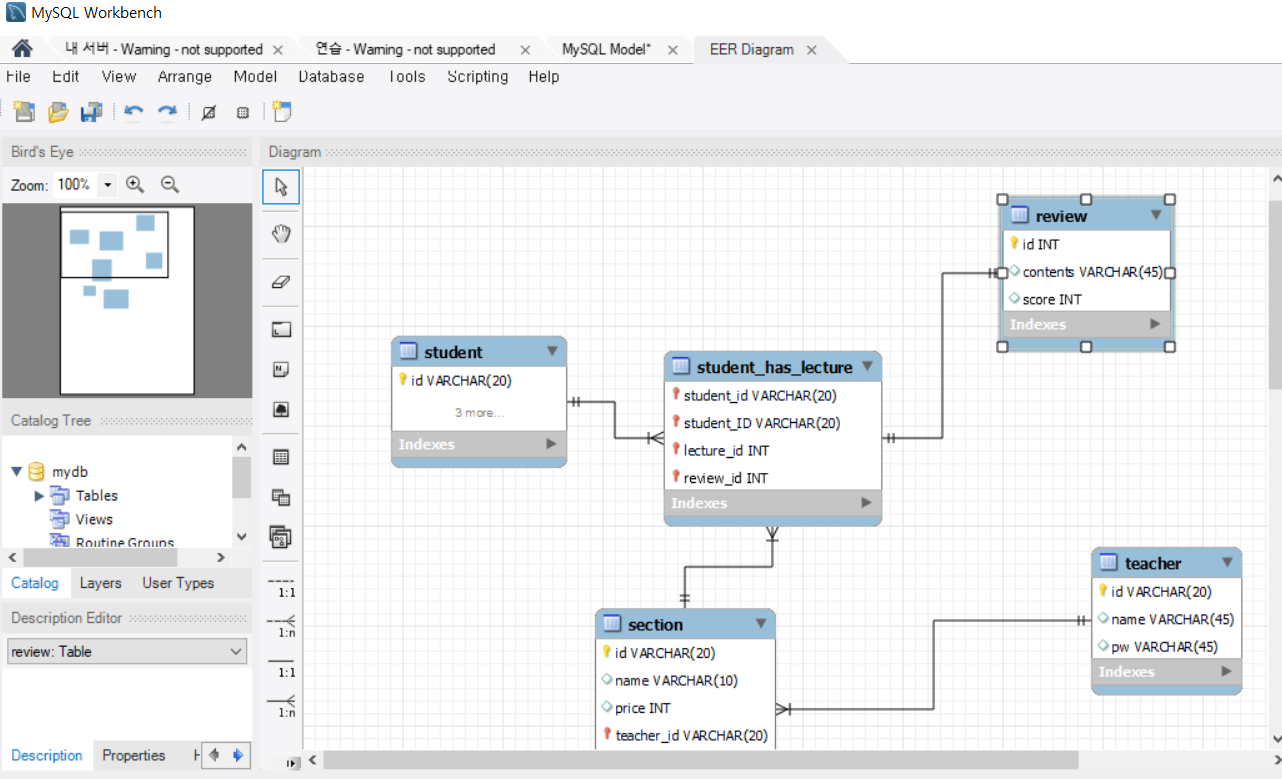
ER다이어그램
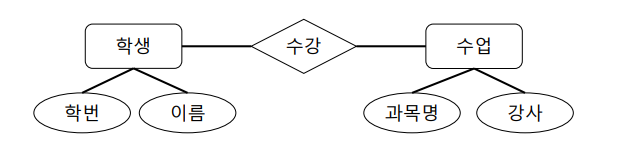

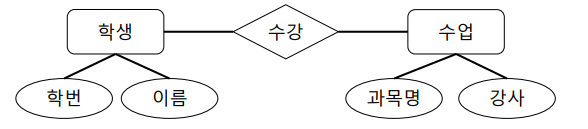
네모가 객체, 마름모가 관계
개체 : 학생이라는 개체를 만들고 수업이라는 개체를 만듦
관계 : 학생이 수업을 수강한다 라는 관계를 맺으므로 수강이 관계가 된다.
개체를 저장할때 학생은 표에 저장해야하니까, 이름, 학번 등을 저장하는 것처럼 정보를 추가한다.
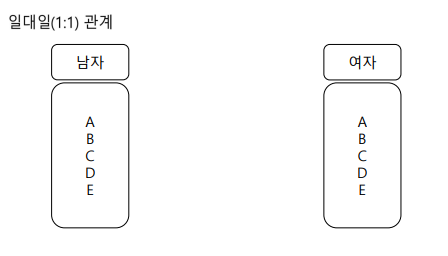
관계는 하나로 설명하기 너무 어렵고, 총 3가지로 나눌 수 있다.
1:1 관계
1:n관계
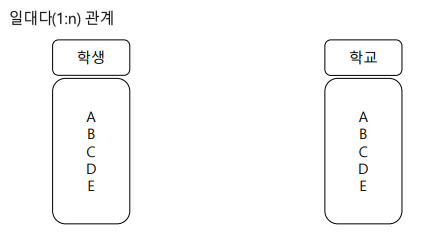
학생은 1개의 학교, 학교는 여러명의 학생이 다닐 수 있다.
n:m관계 (다대다관계)
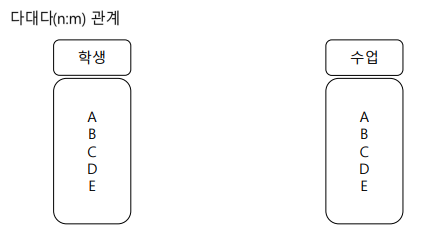
학생은 여러수업을, 수업은 여러학생이 들을 수 있다.
양쪽이 다 되면 다대다, 한쪽만 되면 1:n, 둘다 안되면 1:1 로 생각하면 된다.
실습
데이터베이스는 파일에 저장을 하는것. 저장을 하는 것만 적어야한다.
쇼핑사이트를 만든다.
ex) 온라인 강의 사이트
검색이나 로그인은 데이터를 저장하는 것이 아니다
쇼핑사이트
기능
회원기능
회원은 아이디, 패스워드 이름으로 회원가입할 수 있다.
상품기능
관리자는 상품을 등록할 수 있다.
구매기능
회원은 상품을 구매할 수 있다.
환불기능
회원은 상품을 환불할 수 있다.
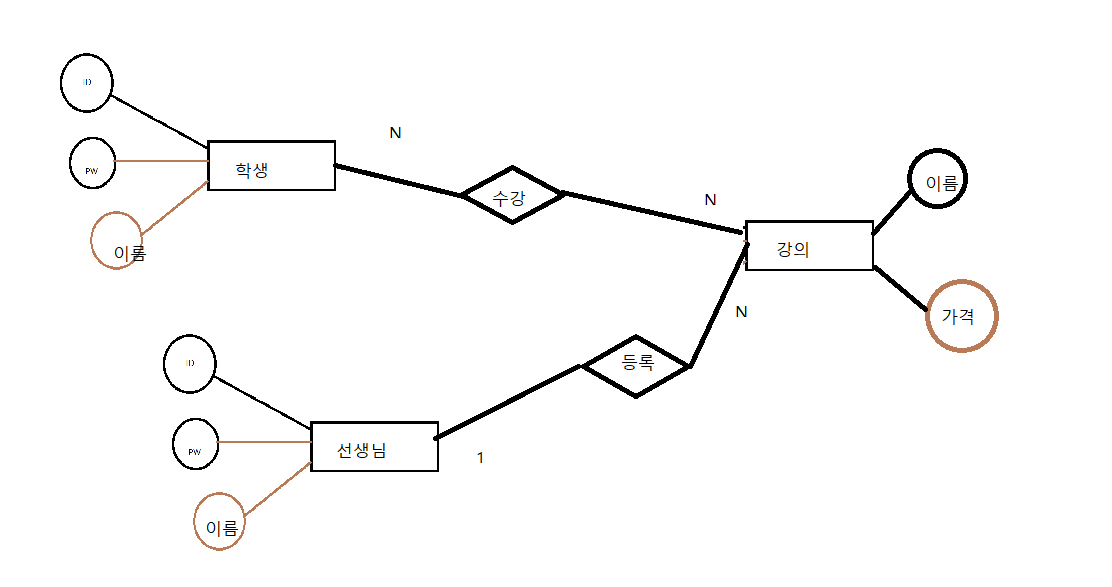
온라인강의사이트
학생기능
학생은 아이디 패스워드 이름으로 회원가입할 수 있다.
선생기능
선생님은 아이디 패스워드
관계데이터모델
릴레이션 : 표 == 릴레이션
속성 : 테이블의 각 열을 의미 ex) 이름, 나이, 성별
튜플 : 테이블의 각 행을 의미 ex) 정완, 30, 여
도메인 : 속성이 가질 수 있는 값들의 집합 ex) 여, 남, 남, 여
기수 : 튜플의 수 Cardinality
차수 : 속성의 수 Degree
릴레이션의 특징
제약조건을 걸 수 있음. 데이터베이스 안에서 데이터의 순서는 의미가 없음. 속성들의 순서도 중요하지 않음.
각속성의 이름은 한 릴레이션내에서만 고유함
ex) teacher의 name과 student의 name은 다르다.
릴레이션에서 동일한 튜플이 두개이상 존재하지 않는다.
ex) kim, 25 / kim, 25 가 같이 존재할 수 없으므로 둘을 구분할 수 있는 속성을 추가해야한다. kim, 25, 0101111 / kim, 25, 0102222 그래서 ID속성을 추가해서 구분한다. 요런 속성을 key 라고 한다.
한 튜플의 각 속성은 원자의 값을 가짐 : 한 행의 취미 속성은 원자의 값을 가진다. 하나의 속성에 여러 원자를 저장하면 안된다. 가장작은 단위로 저장해야한다.
hobby : movie, ani, game (X) / hobby : movie
Key의 종류
| 나이 | 이름 | |
|---|---|---|
| 20 | 정완1 | |
| 10 | 정완 | |
| 20 | 정원 | |
| 10 | 별 |
- 슈퍼키 : 유일성(0), 최소성(x)
유일성(0): 데이터를 구분할 수 있는 속성
최소성(x) : 유일성이 가지는 속성이 가장 적은것 - 후보키 : 유일성(0), 최소성(0) - 기본키가 될 수 있는 키
- 기본키(Primary key) : 모든데이터를 구분할 수 있는 key
- 대체키 : 기본키가 될 수 있는 나머지 키
- 외래키 : 표1이 표2 에서 참조할때 표1의 값만 가져다 쓰는것. 다른테이블에 적혀있는 값만 가져와서 써야한다. 다른테이블에 없는 값만 가져와서 쓰게 되면 에러가 생긴다.
관계데이터제약조건
- 개체무결성 : 전부다 구분할 수 있는 것을 적어줘야하므로 비어있거나 중복이면 안된다.대체키
- 참조 무결성 : 표에있는 기본값이거나 비어있어도 된다. 참조를 아예 안할 수 있음. 외래키
- 도메인 속성 : 나이는 숫자만, 이름은 글자만 같은 속성
Mapping
Mapping의 규칙
아래와 같은 규칙을 순서대로 해야함. 해당사항에 없으면 제외
- 개체는 하나의 표로 변환
- n:m 관계는 하나의 표로 변환
- 1:n 관계는 외래키 속성으로 표현
- 1:1 관계는 외래키 속성으로 표현 / 관계로 표현하지 않아도 되는 아이들. 하나의 속성으로 표현가능
- 다중 값 속성은 다른 표로 변환 / 아예 따로 표로 만들어버려라 여러개 취미가 있을때 여러개를 따로 저장해야하므로 kim 25살의 취미의 표를 따로 만들어서 저장하면 데이터가 줄어든다. 그래서 총 두개의 표로 만드는 것이 좋다.
ERDCloud에서 ERD연습해볼 수 있음!
실습하기
- 서버에 DB서버 프로그램 설치하기 CentOS에서
인터넷이 되는게 전제이다
리눅스 컴퓨터
DB 서버 프로그램 설치
yum install mariadb-server
DB 서버 프로그램 실행
systemctl start mariadb
방화벽끄기
setenforce 0
systemctl stop firewalld
클라이언트 프로그램
mysql(mysql을 실행한 후 아래 명령어)
CREATE USER'[아니셜]'@'%' IDENTIFIED BY 'qwer1234';
DB 생성
CREATE DATABASE [DB이름];
사용자한테 DB 권리 권한 부여
GRANT ALL PRIVILEGES ON [DB이름].* TO '[이니셜]'@'%';
------------------------------------
윈도우 컴퓨터
DB 클라이언트 프로그램 설치
자료실에 workbench 설치
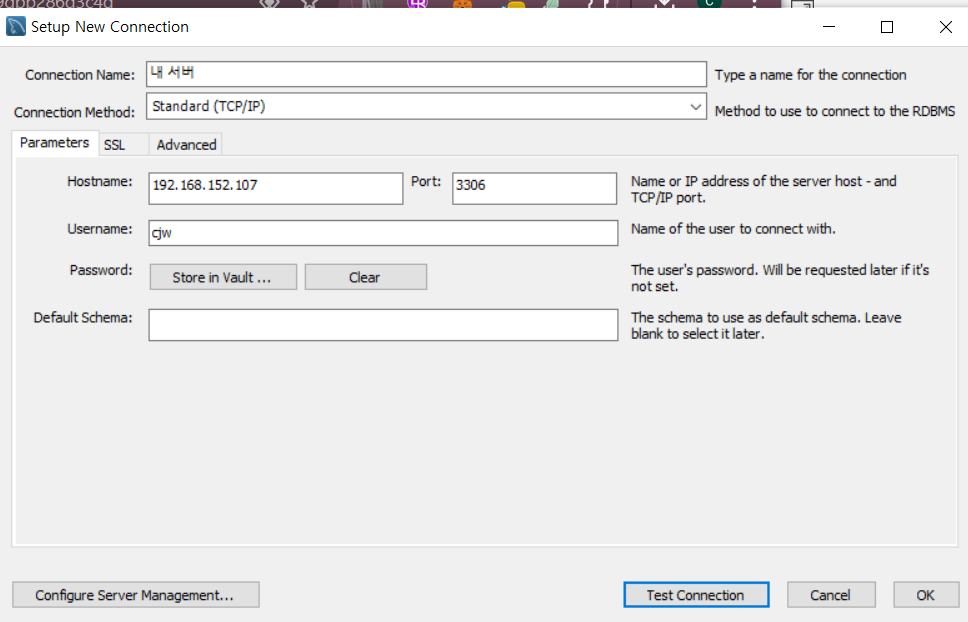
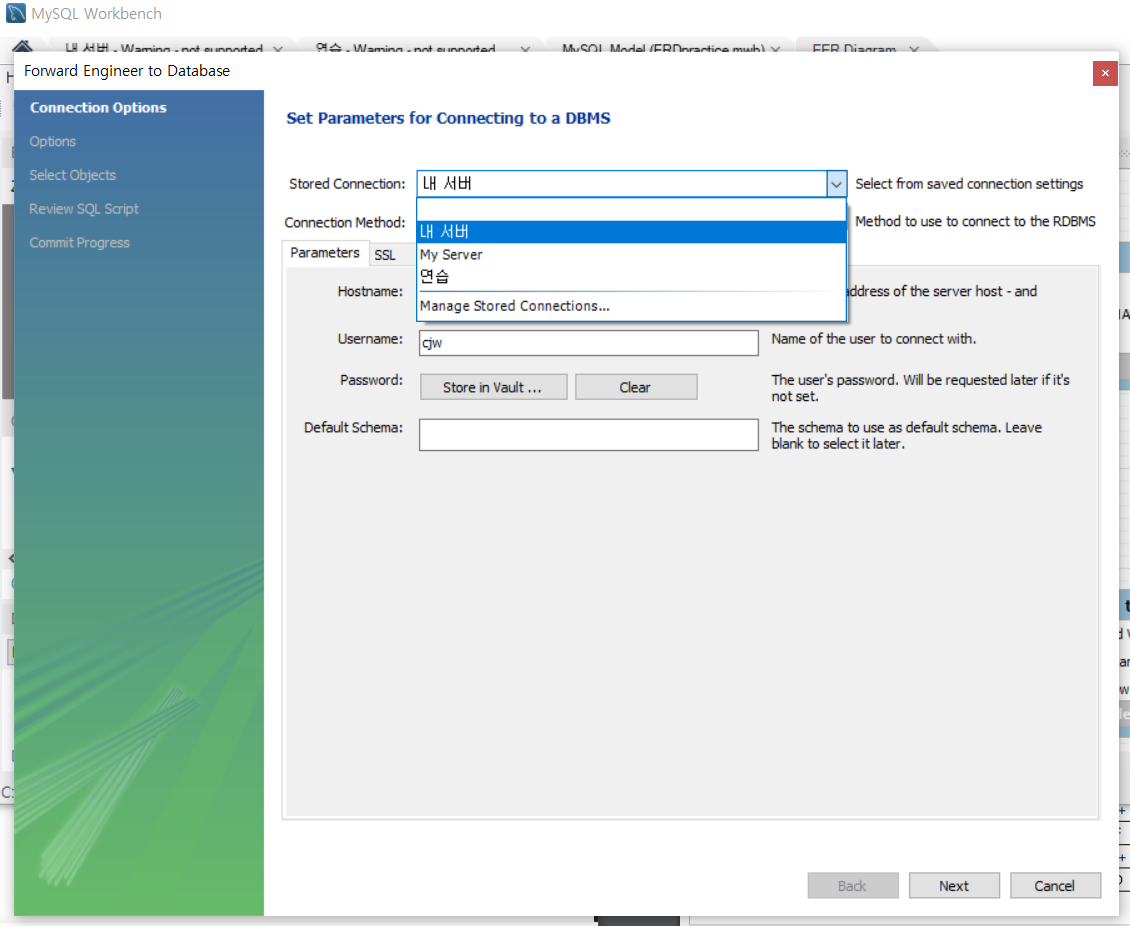
워크벤치에서 서버로 접속
connection name : [아무거나]
Hostname : 리눅스 컴퓨터 IP -> 리눅스에서 ifconfig 에서 IP확인하기.
Port : mariadb-server의 포트번호 = 3306
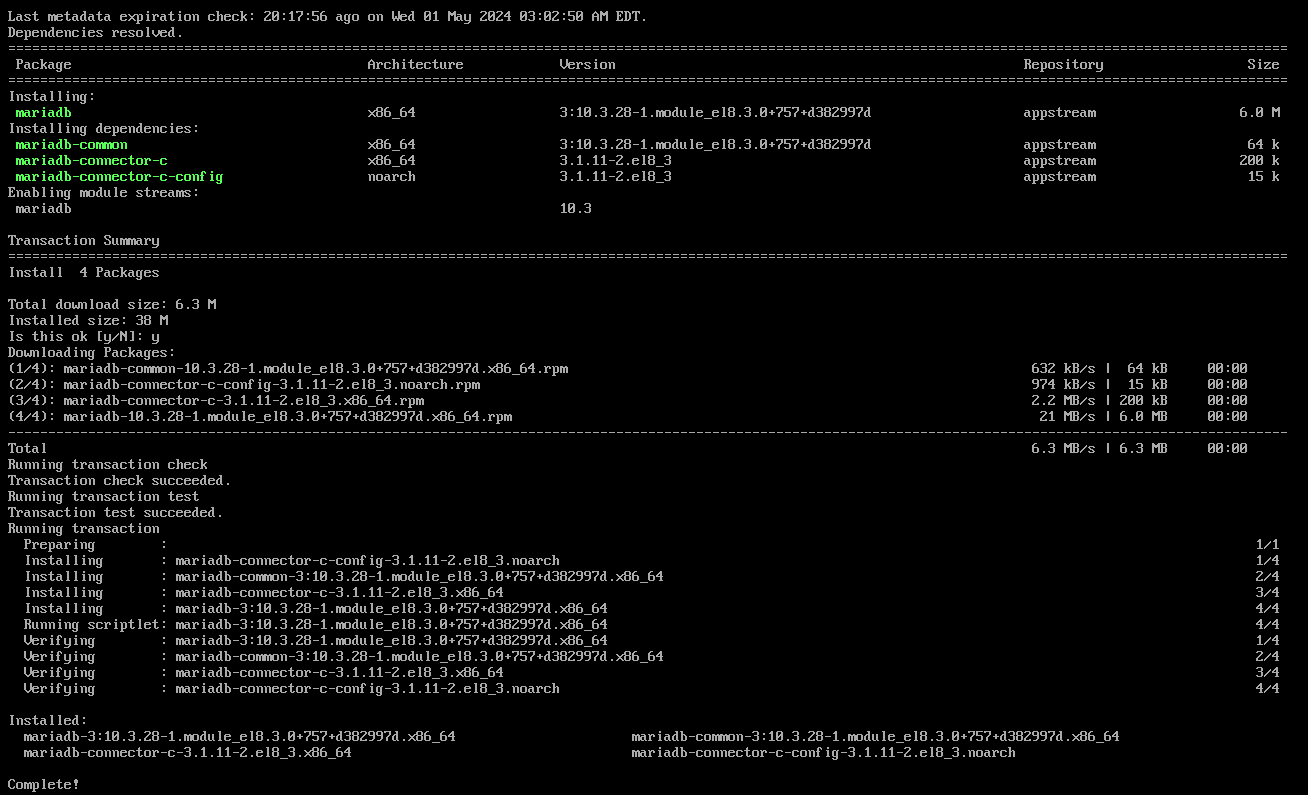
Username : [이니셜]yum install mariadb 은 클라이언트프로그램이 설치된다.
yum install MariaDB-server
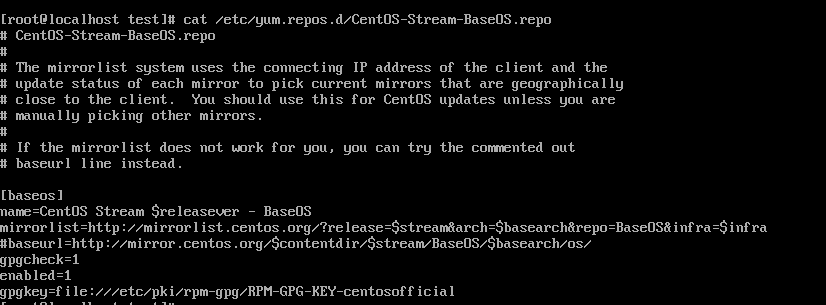
이런 저장소를 추가해야한다는 의미
yum install mariadb-server로 설치해주자
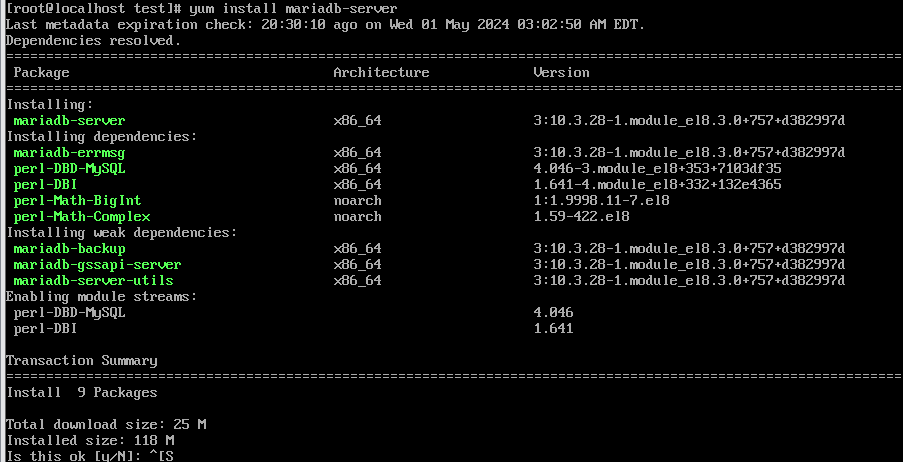
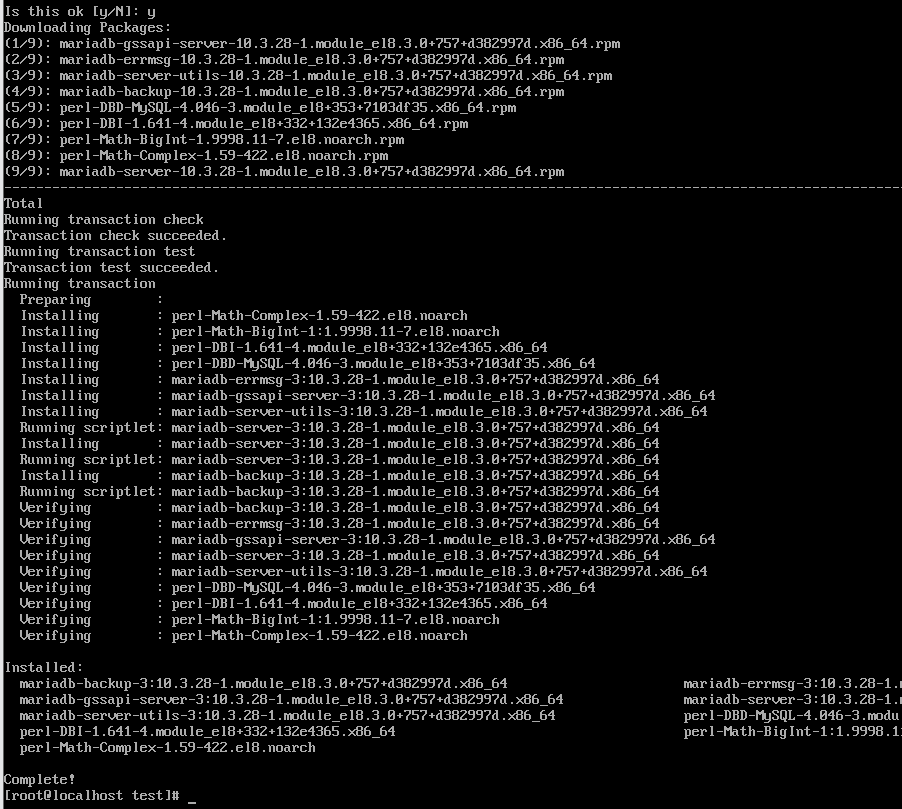
설치한 프로그램을 실행
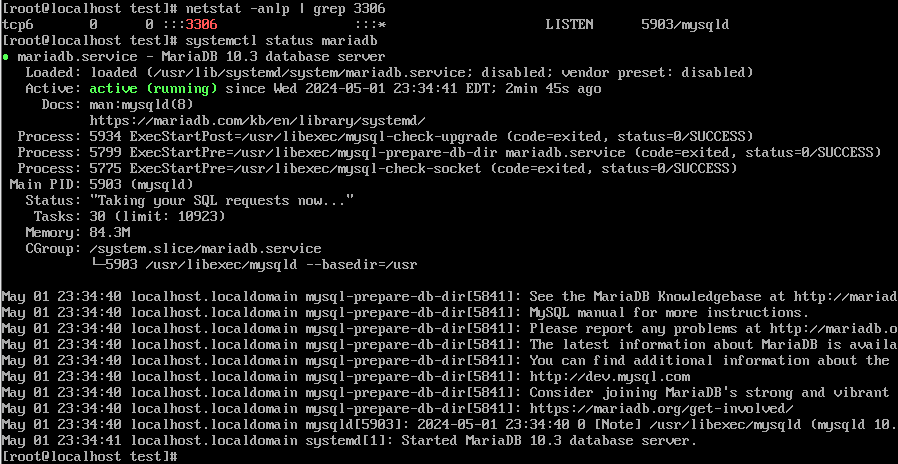
systemctl restart mariadb

netstat -anlp | grep 3306
서버가 사용중인 포트가 잘작동되는지 확인해주어야한다.
- MySQL workbench라는 클라이언트 프로그램 설치

install나올 때까지 yes누르고 install 해주기
finish누르면 workbench가 실행됨

+를 눌러줌
- DB서버가 실행중인 IP주소를 넣기
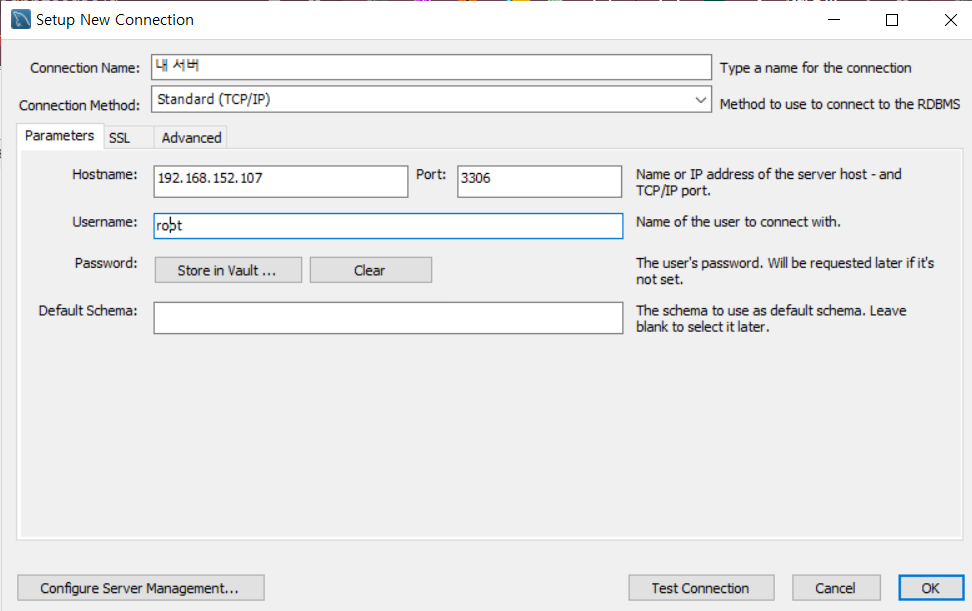
Connection Name은 아무거나 적어줘도 괜찮음
Hostname부분에 DB서버가 실행중인 IP주소를 넣어주고
127.0.0.1 은 자기가 사용하고 있는 컴퓨터의 ip주소를 의미함
처음 설정은 VMware에서만 DB서버가 연결이 가능한 상황인데, 윈도우에서 가상머신에 있는 DB서버에 접속하고 싶기 때문에 권한을 추가하는 과정
CREATE USER 'cjw' IDENTIFIED BY 'qwer1234'; 는 사용자를 추가해서 연결시켜주는 과정
SELECT user, host FROM mysql.user; 는
user 테이블을 조회해서 host가 누구인지 확인하도록 리스트를 보여주는 명령어
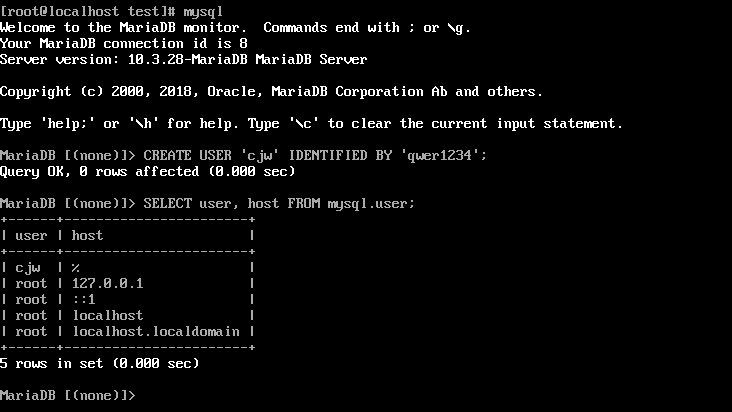
표에 cjw | % 생성된것을 볼 수 있다.
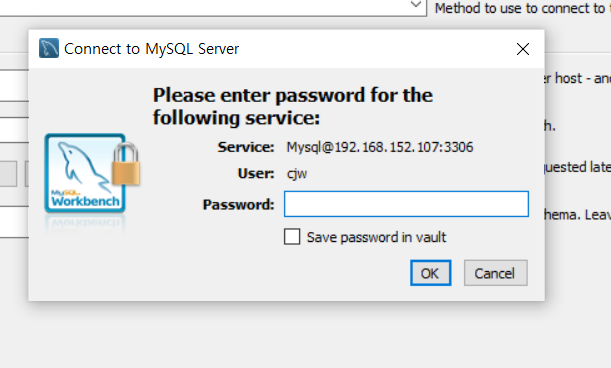
비번입력하고 들어가기
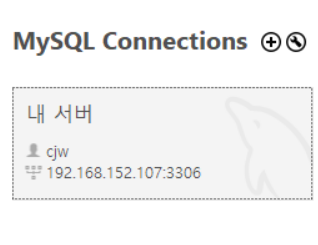
화면 하단에 내서버가 생긴다.
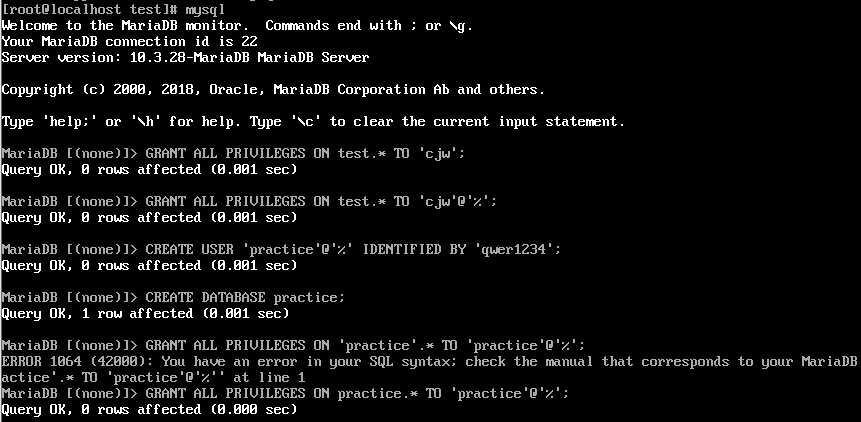
mysql로 들어가서 사용자와 DB를 만들어서 권한주기
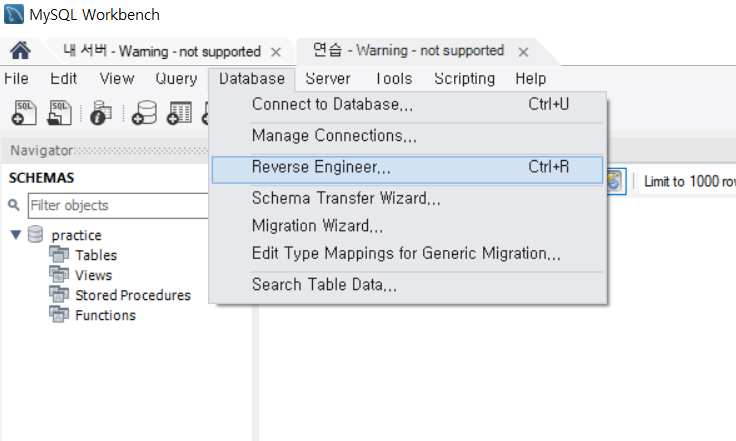
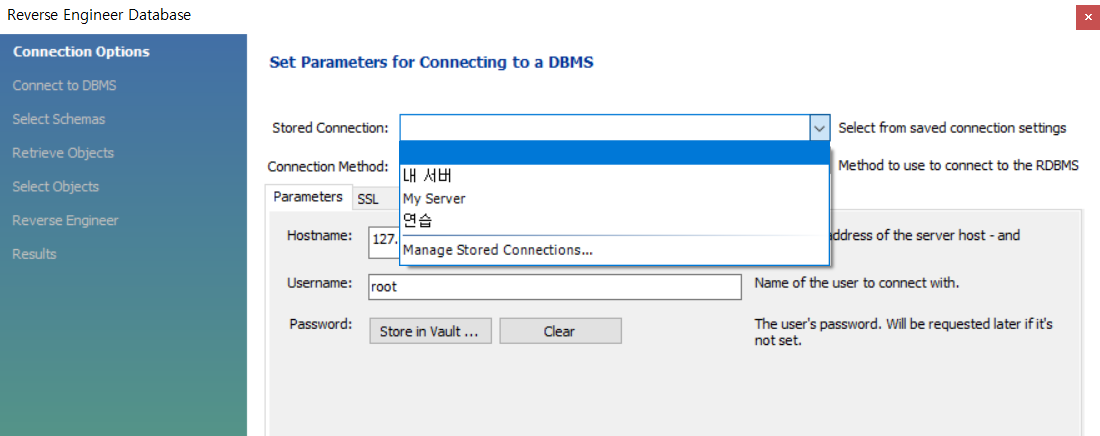
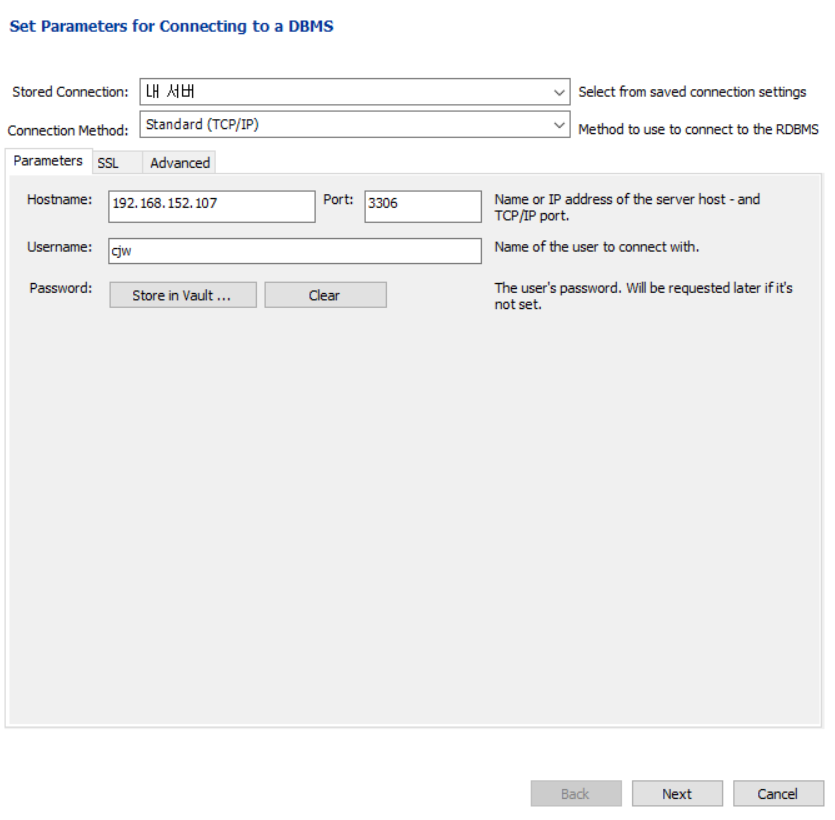
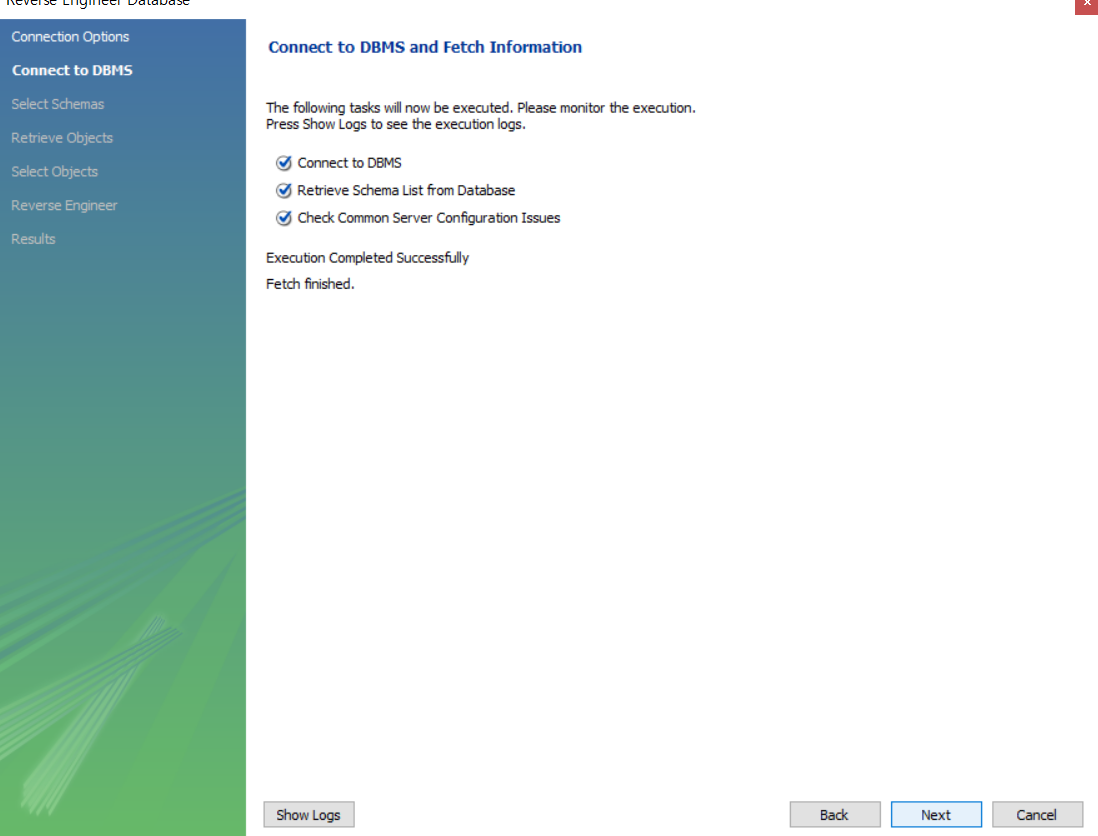
체크하고 다 next누르기
AI autoincrement 자동으로 1씩 올라가게 하는 속성
비번에 null체크는 소셜로그인일때 나의 db에는 아이디만 저장되고있고, 비번은 소셜db에 저장되어있기 떄문임
정규화
표를 두개, 세개로 쪼개는 작업을 정규화라고함. 이상한 문제가 생겨서 문제를 해결하기 위해서 속성간 종속관계를 분석해서 표를 분해하는 것. 테이블에 너무 많은 정보를 집어넣으면 문제가 생기는 경우가 많다. 정보를 쪼개서 넣기!
어떤 문제가 생기는 걸까?
총 3가지가 있다.
- 삽입이상 : 데이터를 집어넣을때, 불필요한 데이터를 같이 넣어야할때
- 삭제이상 : 데이터가 잘못삭제
- 수정이상 : 잘못된 속성을 하나 고쳤는데 데이터간의 불일치가 발생하는 경우
정규화과정
정규화가 안된거
제 1 정규화 - 도메인을 원자화 -> 제 1 정규형
제 2 정규화 - 부분함수종속제거 -> 제 2 정규형
제 3 정규화 - 이행함수종속제거 -> 제 3 정규형
BCNF - 결정자이면서 후보키가 아닌것 제거
제 4 정규화 - 다치종속제거 -> 제 4 정규형
제 5 정규화 - 조인종속제거 -> 제 5 정규형
정규화 그전에
- 함수적 종속
각각의 속성을 먼저 보아야한다. 속성들 사이에 종속관계를 파악하는 것. 예를 들어 학번이 1번이면 과목이름은 자바이다. 라는 관계로 모든 데이터를 확인하고 학번이 1번인데 과목이름이 파이썬이라면 그 데이터는 종속관계가 아닌것. 하나라도 데이터가 깨지는게 있으면 안된다.
그 후에 데이터가 정확하게 맞으면 정규화가 진행되어야한다.
2안에서 대부분 해결이 됨.
제1정규형
정규화가 안되어있는 것에서 1정규형을 하려면 도메인이 원자값이 아닌아이들이 있는지 확인해야한다.
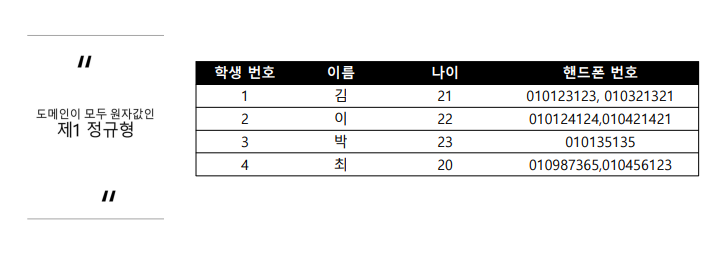
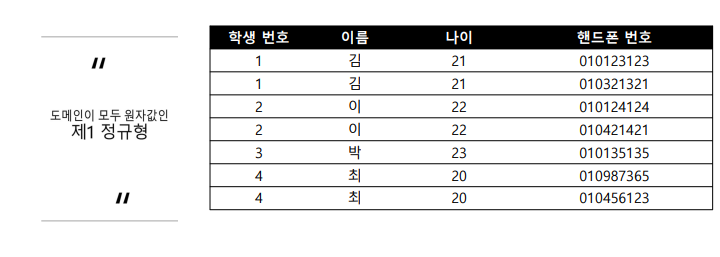
핸드폰번호 데이터가 여러개가 들어가있으므로 따로 쪼개서 데이터를 저장시켜야한다.
제2정규형
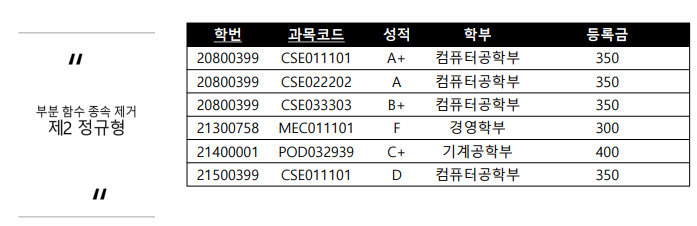
학번과 과목 두개가 성적을 정한다고 볼 수 있다. 두개나 세개안에 있는 작은 갯수의 속성이 종속을 결정하기 때문에 이를 쪼개서 부분함수종속을 없애야한다.
주제정하기 -> 요구분석 -> ERD(테이블스키마(릴레이션스키마)) -> SQL -> 테이블생성
