
사담
클라우드
퍼블릭클라우드 : AWS, GCP, AZURE, 네이버클라우드, KT, Kakao
프라이빗클라우드 : 내가 가진 컴퓨터들 가지고 나만의 클라우드 환경 구성
가상머신기반클라욷, 컨테이너 기반 클라우드
퍼블릭클라우드
- 운영망
가상머신 기반 클라우드, 컨테이너기반 클라우드
(오픈스택) (쿠버네티스 - 요즘추세)
- 개발망
가상머신 기반 클라우드 컨테이너 기반 클라우드
개인노트북
쿠버네티스
최소 3대의 컴퓨터
가상머신 3대
MySQL
서버는 가장 기본적인 형태
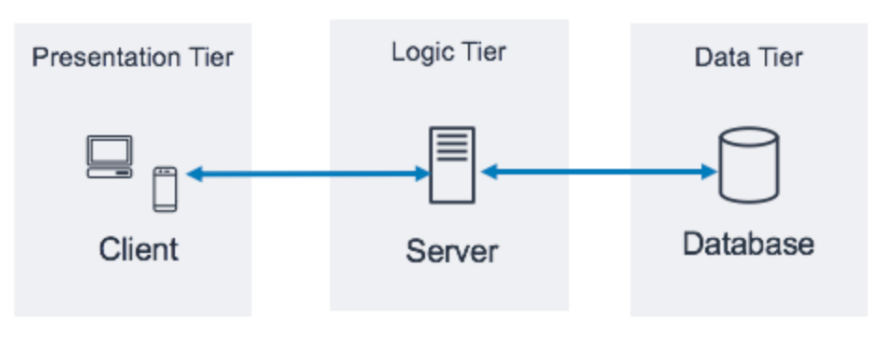
3계층 아키텍쳐같은 모양이다. 백엔드 프로그램이 데이버 서버와 통신하고 프론트엔드가 백엔드에 요청하면 백엔드가 DB서버에서 정보를 가져와서 프론트엔드에 보내준다.
DDL
표자체를 정의하는데 데이터의 구조를 정의하거나 제거하는 데이터 정의어이다. 데이터조작어 아주 중요!!!
CREATE, ALTER, DROP

CREATE TABLE [테이블이름]( //CREATE TABLE은 sql의 문법이므로 대문자사용
[속성이름][타입],
[속성이름][타입],
.
.
.
[속성이름][타입]
); -> 세미콜론까지를 한줄로 인식
VATCHAR -> variable charactor
INT -> 수
AUTO_INCREMENT -> 1씩 자동증가되도록 설정하기
CREATE TABLE video ( //video 테이블 생성
idx INT AUTO_INCREMENT PRIMARY KEY, //
name VARCHAR(20),
url VARCHAR(100)
);
DROP TABLE video restrict; //video 테이블삭제
//외래키는 1:1 1:N 상관없이 하나의 테이블이 다른 테이블의 속성을 참조할때 참조하는 테이블이 외래키를 가진다.
CREATE TABLE video (
idx INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20),
url VARCHAR(100),
**member_id** INT, //외래키를 사용하기 위해서 설정
FOREIGN KEY(**member_id**) REFERENCES ~~member~~ (_id_)
);
CREATE TABLE ~~member~~ (
_id_ INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(10),
email VARCHAR(30),
password VARCHAR(20)
);
ALTER TABLE video ADD playtime INT; //video테이블에 playtime속성추가하기
ALTER TABLE video MODIFY playtime VARCHAR(10); //video 테이블에 playtime 속성바꾸기
ALTER TABLE video CHANGE playtime play VARCHAR(10); //playtime 이름바꾸기
ALTER TABLE video DROP play; //속성삭제하기
ORM
서비스 기업에서 잘씀
Object Relation Mapping
객체지향 프로그래밍 언어 관계형 베이스
DML
DML을 잘짜야한다.
INSERT INTO memeber(id, email,password, name) VALUE
(1,'test@gmail.com', 'qwer1234', 'test1');
INSERT INTO memeber VALUE //속성이름을 삭제해도 가능
(1,'test@gmail.com', 'qwer1234', 'test1');
INSERT INTO memeber(email, password, name) VALUE //id가 없으면 어떤 3개인지 헷갈려하기 때문에 속성3개는 적어준다.
('test@gmail.com', 'qwer1234', 'test1');
INSERT INTO memeber(id, email,password, name) VALUES //여러개입력할때, 여러가지 입력하지 않아도 VALUES 사용가능
(1,'test@gmail.com', 'qwer1234', 'test1'),
(1,'test@gmail.com', 'qwer1234', 'test1'),
(1,'test@gmail.com', 'qwer1234', 'test1'),
(1,'test@gmail.com', 'qwer1234', 'test1');
SELECT * FROM member; //member 테이블 조회
UPDATE member SET password='abcd1234' WHERE id=1; //내가 원하는 행을 찾아서 바꾸겠다 WHERE
DELETE FROM member WHERE id=2; //member테이블에서 id가 2인 데이터만 삭제하겠다.해당 nation.sql 데이터를 가져다가 워크벤치에서 사용하기
DROP DATABASE practice; 로 practice 데이터베이스를 지운 후에
nation.sql 에서 내가 쓰고싶은 practice데이터베이스로 권한을 주도록 바꿔준다.
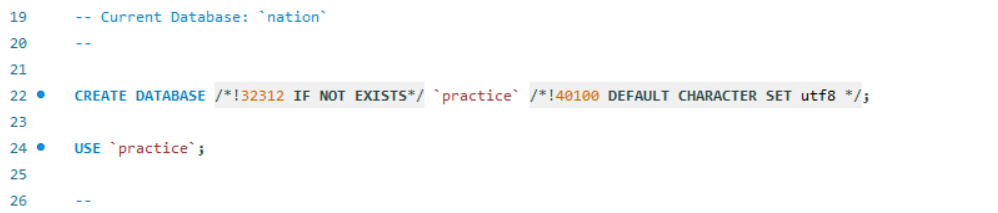
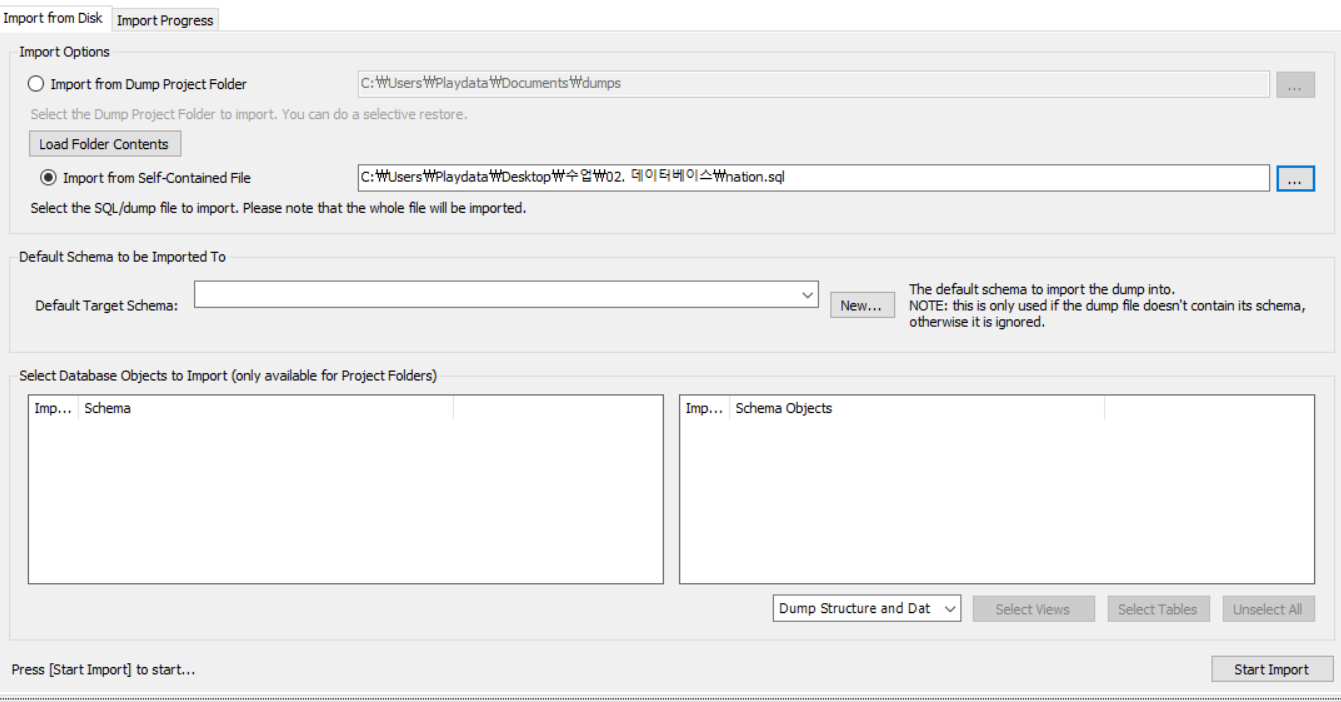
워크벤치에서 Data Import 로 들어간다.
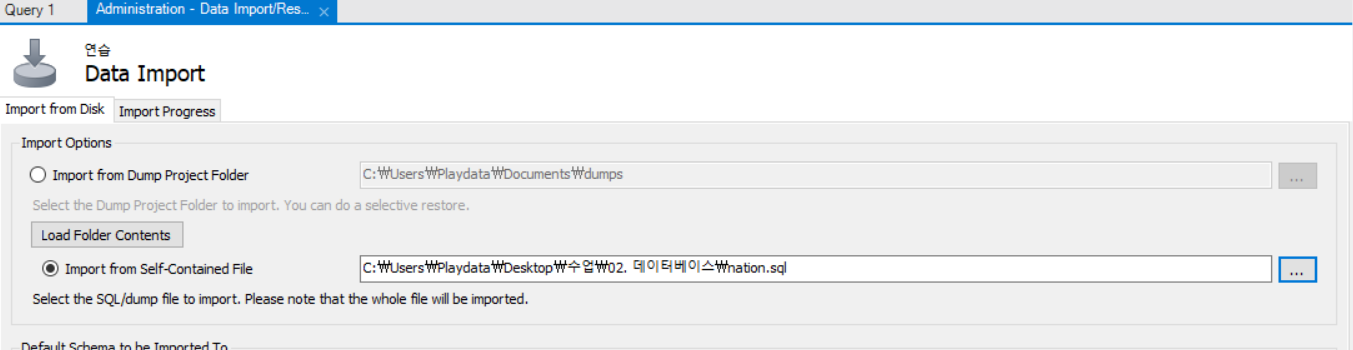
파일에 nation.sql의 경로를 찾아 넣어준 후 하단 start import를 눌러준다.
USE test;
SELECT guest_id, name FROM guests;
SELECT * FROM guests;
SELECT name FROM guests;
SELECT * from guests WHERE guests_id = 1; # WHERE는 표로 치면 특정 행 * 부분은 특정 열을 선택한다고 보면 된다.관계형 데이터베이스는 참조가 하나가 아니다. 여러테이블에서 조회하는 케이스가 훨씬많다.
//여러테이블에서 데이터 조회
JOIN을 많이 쓰는데 ㅣLeftJOIN을 가장 많이 쓴다.
SQL Injection 공격
# ID : sdfsdf' = '1' OR '1' = '1'##
# PW : asdfsdf
SELECT id, email,password FROM member
WHERE email = 'asdasd@gmail.com' AND password = 'qwer1234';
SELECT id, email,password FROM member
WHERE email = ' sdfsdf' = '1' OR '1' = '1' AND password = 'qwer1234'; # SQL 인잭션의 예JOIN
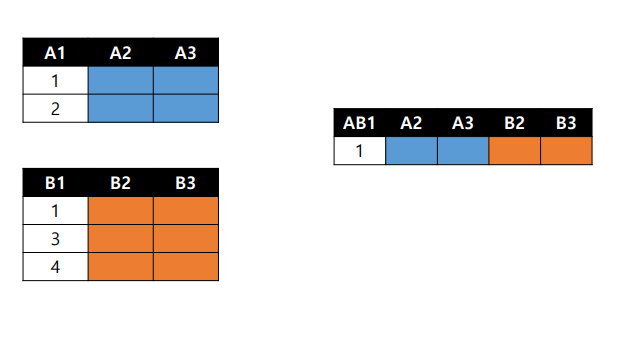
- Inner JOIN : 교집합
A1과 B1에서 데이터를 뽑겠다.
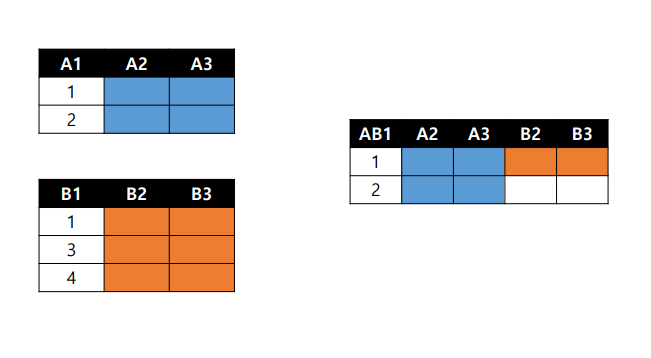
- Left JOIN : left를 기준으로 뽑고 같은걸 옆에 붙인다.
A1을 일단 가져가고 B1에서 A1과 공통된 아이를 옆에 붙여준다.
#여러테이블에서 데이터조회
SELECT * FROM countries LEFT JOIN regions ON countries.region_id = regions.region_id#같은걸 뽑겠다! 보통 외래키를 입력
#여러테이블에서 특정 데이터 조회
SELECT * FROM countries
LEFT JOIN regions
ON countries.region_id = regions.region_id
WHERE countries.region_id = 1;
SELECT regions.name, continents.name FROM regions
LEFT JOIN continents
ON regions.continent_id = continents.continent_id
WHERE regions.continent_id = 1 OR regions.continent_id = 2;
#countries의 언어 출력 # 3개쪼인하기
SELECT * FROM countries
LEFT JOIN country_languages
ON countries.country_id = country_languages.country_id
LEFT JOIN languages
ON country_languages.language_id = languages.language_id
ORDER BY countries.area ASC, languages.language_id ASC; #ASC 오름차순정렬 DESC 내림차순정렬 정렬을 연달아하고 싶으면 , 뒤에 붙이면된다. 앞에껄 먼저하고 난 후 다음껄정렬
SELECT * FROM countries WHERE national_day IS NULL; #비어있는것을 찾을때
SELECT * FROM countires WHERE nane NOT LIKE '%me%';
SELECT * FROM countires WHERE name LIKE '%me%';
// %는 어쩌고 라고 생각하면댐. me로 시작하는것 포함해서 / 포함하지 않고
//LIKE 어떤단어를 포함하고있는지 NOT LIKE 어떤단어를 포함하지 않고 있는지
SELECT * FROM countriees LIMIT 10; //맨처음부터 10개조회
SELECT * FROM countries LIMIT 5,3 ; //5부터 3개내장함수
만들어놓은 함수 그대로 돌아가는것. 집계함수를 많이씀

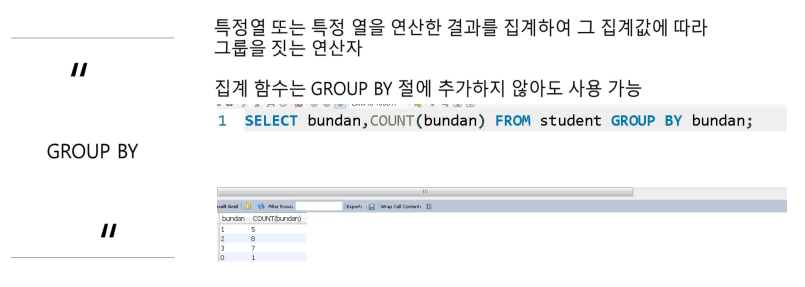
GROUP BY
HAVING
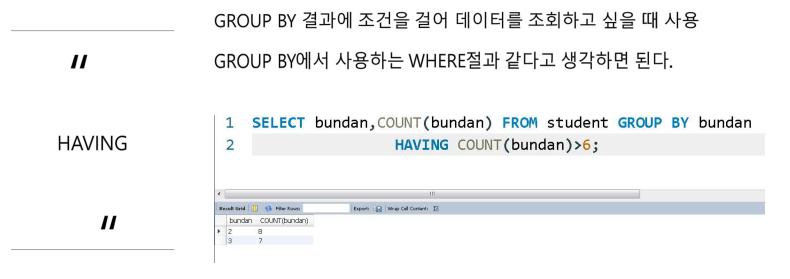
SELECT *, SUM(area) FROM countries; //area속성을 다 합친것
SELECT region_id, SUM(area) FROM countries GROUP BY region_id; //GROUND BY : ~의해서 묶어서 모든걸 다 출력
//집계한걸 가지고 평균을 구하고 싶다 HAVING
HAVING AVG(area) > 10000;
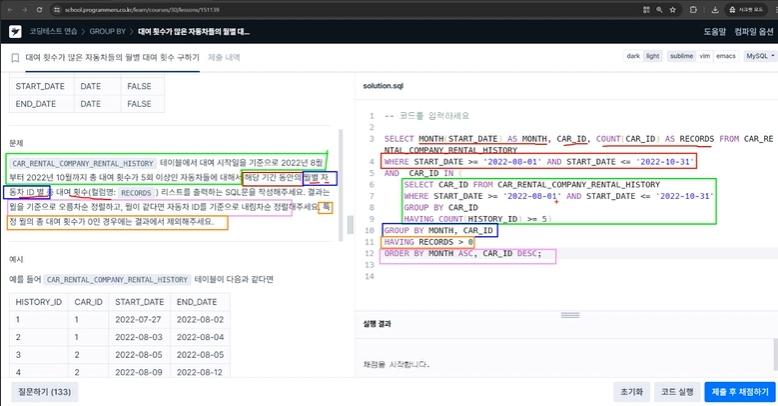
//국가별 평균 GDP가 20 0000 0000 이상인 국가의 이름을 출력, 출력할 때 평균 GDP가 높은 순으로 출력
SELECT * FROM practice.country_stats
GROUP BY GDP
HAVING AVG(gdp) >= 200000000;
#국가별 평균 GDP가 20 0000 0000 이상인 국가의 이름을 출력, 출력할 때 평균 GDP가 높은 순으로 출력
//AS는 결과값에서 속성이 AVG(GDP)그대로 나오지 않도록 이름을 설정해준것
SELECT country_id,AVG(GDP) AS practice FROM country_stats as practice
GROUP BY GDP
HAVING AVG(gdp) >= 200000000;
SELECT * FROM countries WHERE region_id IN(SELECT region_id FROM regions);
#SELECT * FROM countries WHERE region_id IN(1,15,2,3,5);
#서브쿼리를 보면 region_id만 뽑고 있는데 이것의 결과값이 들어가서 실행되는 것과 같다. 보통 IN과 같이 잘쓰인다.
// SELECT region_id FROM regions 실행 결과에 있는 region_id만 countries 테이블에서 조회
SELECT * FROM countries
WHERE region_id = (SELECT region_id FROM regions WHERE region_id=1);
// countries 테이블에서 region_id가
// SELECT region_id FROM regions WHERE region_id < 3의 실행 결과중 하나인 것
SELECT * FROM countries
WHERE region_id = ANY(SELECT region_id FROM regions WHERE region_id < 3);
// * 부분에 테이블의 속성이 나오는데 데이터베이스에서 자료독립 자기정의 자료추상
가상머신 2대(CentOS)
1대 NGINX + PHP + wordpress설치
1대 mariadb 서버
프로그래머스
