
2020-12-07
생일날 공부하는 블로깅이라니 나에게 주는 공부선물,,, 새로워,,,짜릿해,,, 너무 짜릿해서 죽을맛,,,정말 1도 안절거워,,, 집인데 집가서 놀고싶다... 나 자신, 탄신일 축하행🎉🎁🎊🎂 Happy B-day to ME!!! 태어나줘서 고마운데, 고생길 좀 걷자,,헤헤,,
그럼, Linked List를 배웠으니, 다음 단계인 Hash Table에 대해 알아보자!
About Hash Table

오밤중에 사진을 보니, 군침이 도는 이 음식은 바로 해쉬브라운이다. 맥도날드 햄버거 패티로도 들어가기도하고, 에어프라이기나, 후라이팬이 살짝 구워, 케찹에 찍어먹으면, 세상 부러울게 없는 그런 다이어트실패의 지름길인 음식이다. 처음 접한 하와이에서, 먹어보고는 자주 사먹곤했던 음식이다. 맛있는건 알겠는데, 프링글스에 이어, 갑분 해쉬브라운...?🥔
About Hashing
자, 해쉬브라운은 감자를 다지고, 으깨고, 섞고, 튀긴 음식이다. 해쉬테이블은 해시맵 이라고 생각하면 되는데, 맵이라는 자료구조에 해싱을 추가한 Data structure 이다. 일단 여기서 해싱(hashing)이란 입력값을 처리해서 새로운 값을 만드는 작업이다.
즉, 해쉬브라운에 대입해 생각해보면, 해싱(hashing)은 입력값(감자)에 대해 특별한 연산(다지고, 으깨고, 섞고, 튀기기)를 적용해서 새로운 값(해쉬브라운)을 만드는 작업이다. 그리고 이런 처리를 해주는 것이 Hash Function(해쉬함수) 라고 한다.
About Hash Function
Hash Function은 input으로 key를 받아 해싱처리를 거쳐 만들어진 해시값을 출력으로 반환하는 함수이다. return되는 hash value는 Hash Table의 index로 사용된다. 따라서 Hash Table은 인터페이스는 [KEY, VALUE]로 관리되는 dictionary의 모습이지만, 내부적으로 구현되는 방식은 배열에 해시함수가 결합된 구조라고 볼 수 있다.
이런 Hash function은 아래의 특정 조건을 갖추어야 사용할 수 있다.
`Hash Function의 특정조건`
1. 일관성.
// 같은 값을 넣으면, 항상 같은 값이 나와야한다.
2. 다른값이 들어가면, 다른 숫자가 나와야한다.
// 다른 data에 대해 모두 다른 숫자가 나오면, 쵝오
3. 유효한 index만을 반환.
// Hash Talbe의 크기를 알고 있어야하고, 배열에서 사용가능한, index를 return
4. key를 Hash Table 전체에 골고루 할당.
// 중복을 최소화.How fast is it?
data를 조회할 때, Hash Function을 사용하면, 한번의 실행으로 data의 index를 알 수 있다. 즉, index를 알고 있는 배열데이터를 조회하는 것과 같은 실행시간(평균 O(1))으로 검색가능하다. 또한, 이미 크기가 정해진 Array를 사용하므로 요소를 변경할때, 다른요소들을 이동하는 일이 필요없어, 추가/삭제시의 속도도 빠르다.
평균적인 경우, Hash Table은 탐색, 삽입, 삭제 각각 O(1)시간으로 가능하다. 최악의 경우는 각각 O(n)시간이 걸릴 수도 있다.
what is Hash Collison?
해시테이블 배열의 크기가 한정적이고, index를 반환하는 해시함수에 한계가 있을수 있으므로 KEY는 다른데 해시값이 같은 경우가 생길 수 있다.
그럴 경우, 다른 Key가 같은 index를 할당 받게된다는 것이므로, 나중에 입력된 값이 이전의 값을 덮어쓰게되어 이전 값이 삭제되는 문제가 생기는데, 이것을 Collision(충돌)이라고 한다.
How to Solve
1. Chaining(체이닝)
가장 단순한 해결법. index별로 Linked List를 생성하는 방법. Array의 각요소로, 값 아닌 Linked List를 넣는 방식이다.
But, LinkedList가 길어질수록, 속도가 느려질 수 있고(LinkedList의 검색은 O(n)이어서, 최악의 경우 LinkedList의 data를 검색하는 속도O(n)이 나올 수 있다.), LinkedList를 위한 별도 메모리공간이 소모된다는 단점이있다.
2. Linear Probing(선형 탐색법)
Hash Table에 새 요소를 추가할때, index가 사용중이라면, 'index + 1'을 찾고, 사용중이라면, 'index +2'를 찾는 식으로 충돌을 피하는 방법.
But, Linear Probing이 누적되면, 할당된 뭉치가 커지는 clustering(집적화)문제가 발생, 평균탐색시간을 길게만든다. JavaScript처럼 연관배열을 사용하는 것이 아닌, Array의 크기를 미리 정해야하는 언어를 쓴다면, Array index가 범위를 넘어서는 경우에 대한 처리를 해주어야한다.
3. Double Hashing(이중해싱)
2개의 Hash Function을 사용해, 충돌이 발생했을 경우, 다른 Hash Function으로 다른 Hash value를 만들어내는 방식.
Best Solution: Good Hash Function & Resizing
가장 좋은 방법은 애초에 충돌을 만들지 않는 것!
Good Hash Function
좋은 Hash Function은 삽입/조회 속도가 빠르고, 충돌확률이 낮아야한다. 잘 알려진 해시함수를 이용하는 것도 좋은 방법중 하나다. Hash Function은 계속 연구,발전되는 중이고, 암호화에도 사용되고있다.
Resizing
Resizing은 Hashtable의 Array의 크기를 조정하는 것. Array의 크기를 확장하면, index사용범위가 늘어나, 충돌이 줄어든다. 보통 사용률이 0.7보다 커지면 Resizing한다.
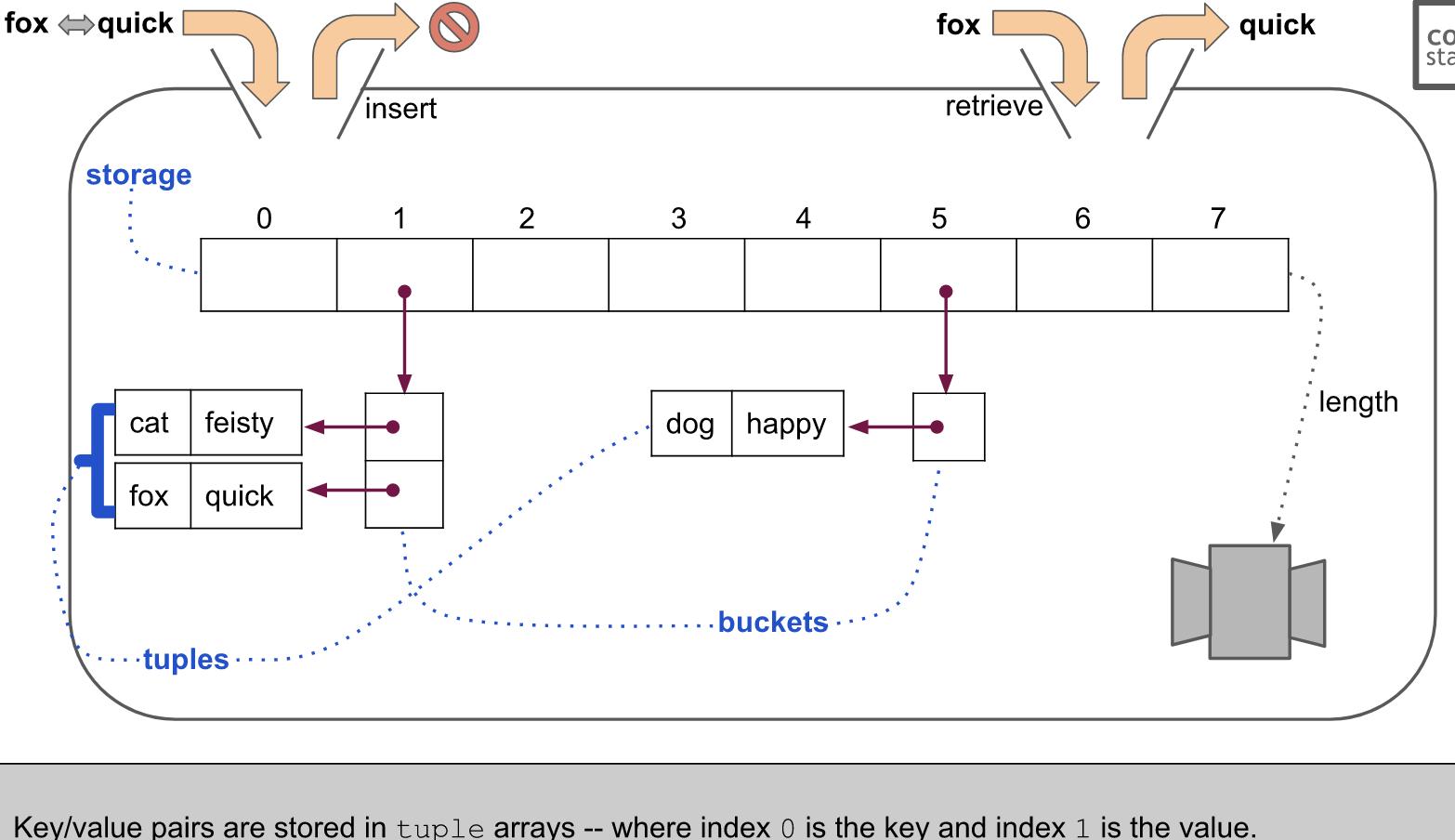
Hash Table의 Property & Method
Property
_size- input의 개수
_bucketNum- hash table의 첫크기
_storage- LimitedArray(this._bucketNum)를 사용 / storage arr의 사이즈
Method
insert(key, value)- 주어진 키와 값을 저장. 이미 해당 키가 저장되어 있다면 값을 덮어씌운다. 해시 테이블에 저장된 key-value 쌍이 bucketNum의 75%를 넘는 경우 bucketNum을 2배로 늘린다.
retrieve(key)- 주어진 키에 해당하는 값을 반환. 없다면 undefined.
remove(key)- 주어진 키에 해당하는 값을 삭제하고 값을 반환. 없다면 undefined. 25%보다 작아지는 경우 bucketNum을 절반으로. 리사이징 후 저장되어 있던 값을 전부 다시 해싱.
_resize(newBucketNum)- 해시 테이블의 스토리지 배열을 newBucketNum으로 리사이징하는 함수.
구현 후 HashTable 내부에서 사용.
constructor() {
this._size = 0; //input의 개수
this._bucketNum = 8; //hash table의 첫크기
this._storage = LimitedArray(this._bucketNum); // storage array의 크기/LimitedArray사용
}
// get은 저장테이블에서 가져오기 set은 저장테이블에 저장하기
insert(key, value) {
// 주어진 키와 값을 저장합니다. 이미 해당 키가 저장되어 있다면 값을 덮어씌운다.
const index = hashFunction(key, this._bucketNum);
// 빈객체 생성
// storage[index]의 value가 없을때
// bucket에 key, value 넣어주기
// set으로 storage에 저장하기
// storage[index]의 value가 있을때
// 빈 객체인 bucket에 get으로 값가져와서 넣기
// bucket의 key값을 새로운 value로 덮어씌우기
// storage에 set으로 저장하기
// value가 추가되었으니, size가 1씩 증가
// key-value 쌍이 bucknum의 75%를 넘는 경우,
// bucketNum을 2배로 늘려서 resize하기
}
retrieve(key) {
const index = hashFunction(key, this._bucketNum);
//먼저 해당 인덱스가 있는지 확인하고 그 인덱스에 키가 있는지도 확인해야한다.
// storage[index]가 비어있거나, storage[index]의 key값이 없으면
// undefined
// 그렇지 않으면, storage[key]의 값을 return
}
remove(key) { // linked list와 비슷하다!
const index = hashFunction(key, this._bucketNum);
// storage[key]를 delete
// 요소를 삭제했으므로, size도 1씩 준다.
//_storage에 요소가 전체 범위에 25프로 이하로 내려가면
// 반으로 크기를 줄여준다.
}
_resize(newBucketNum) {
// 사이즈를 다시 조정 후, 저장되어있던 값을 다시 전부 해싱해준다.
// 해시 테이블의 스토리지 배열을 newBucketNum으로 리사이징하는 함수입니다.
// hashtable의 첫크기를 새로운 크기로 할당
//확장,축소전 현재 storage를 변수선언할당
//늘어나거나 줄어든 new사이즈로 새로 storage생성;
// 새로 크기를 변경 했으니 일단 안에 있던 요소들의 수는 0으로 초기화 한다. 새로 담아 줄꺼기 때문에
// resize 전에, storage를 하나씩 순회
// key를 하나씩 돌면서,
//bucket에 있는 key 값을 다시 storage에 넣어준다.
// 이때 주의할점은 arrow function을 사용해야지 this를 binding 하지 않는다.
//그냥 function을 사용한다면, this는 확장이나 축소전의 storage를 가리켜,
//insert를 사용할 수 가 없다. arrow function을 사용하면
//기존의 this가 가리키고 있던 limitedArray로 적용되, insert를 사용할 수 있다.
}

맛있네요