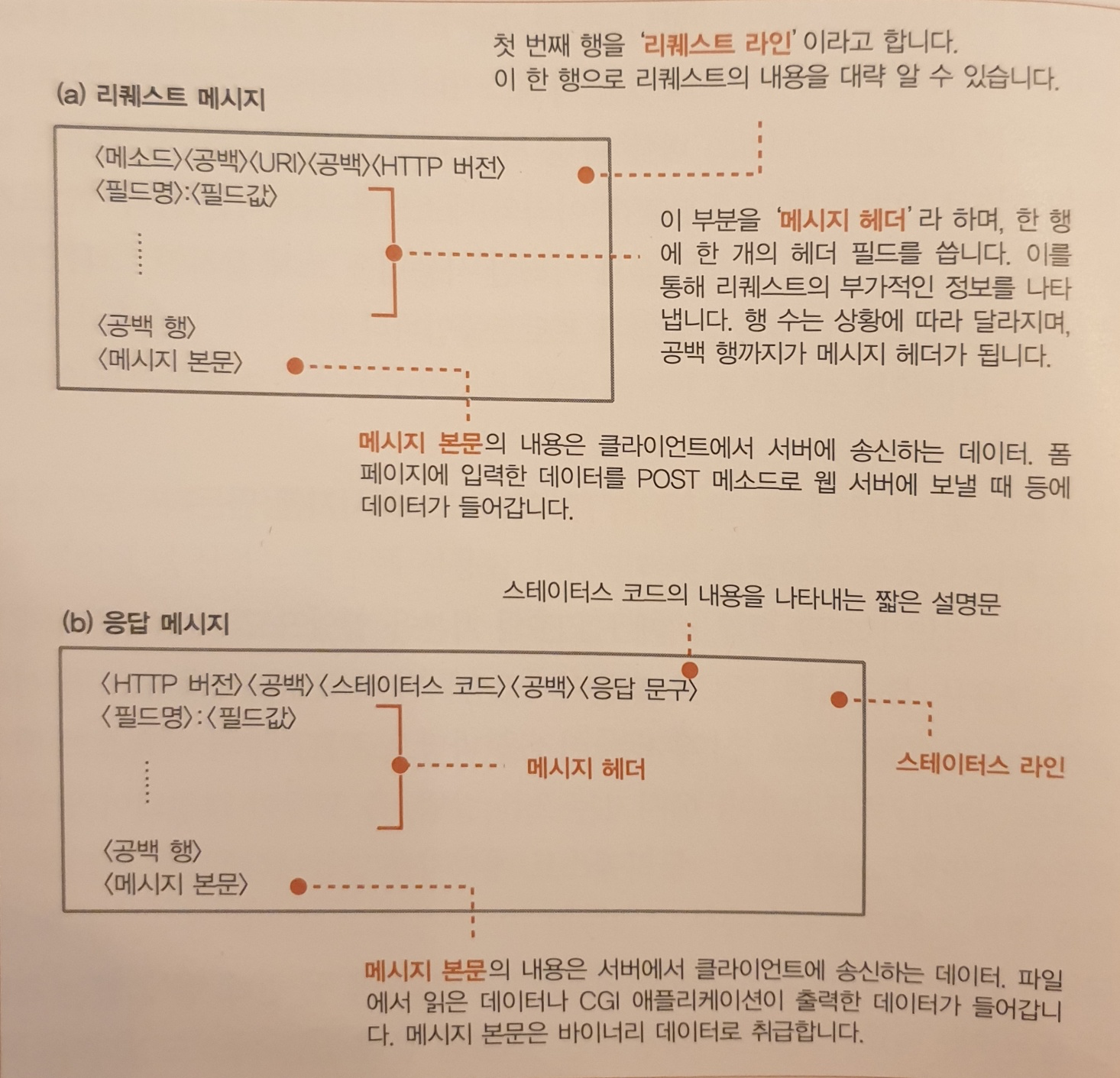
HTTP 리퀘스트 과정
1. URL을 작성한다.
URL에는 엑세스 대상의 프로토콜을 사용해 엑세스한다.
엑세스 대상에는 웹 서버(http:), 파일(ftp:), 메일(mailto:) 등이 있다.
2. URL을 해독한다.

URL을 해독해 어디에 엑세스 할지 결정한다.
URL의 형식은 프로토콜에 따라 다르다.
3. 리퀘스트 메시지를 만든다.
실제 HTTP 메시지는 포멧이 결정되어 있으므로 브라우저는 이 포맷에 맞게 리퀘스트 메시지를 만듭니다.
리퀘스트 메시지에 쓰는 URI는 한 개만 결정되어 있으므로 파일을 한번에 한 개씩만 읽을 수 있습니다.
4. 응답이 돌아온다.
리퀘스트 메시지를 보내면 웹 서버에스 응답 메시지가 돌아옵니다.
응답의 경우 목적이 다른 스테이터스 코드와 응답 문구를 첫 번째 행에 써야 합니다.
스테이터스 코드 : 숫자로 쓴 것이며 주로 프로그램 등에 실행 결과를 알려주는 것이 목적
응답 문구 : 문장으로 쓰여있으며 사람에게 실행 결과를 알리는 것이 목적
HTTP 기본 개념
HTTP 프로토콜 : 클라이언트와 서버가 주고받는 메시지의 내용이나 순서를 정한 것
클라이언트는 서버에게 리퀘스트 메시지를 보냅니다.
서버는 클라이언트에게 응답 메시지를 보냅니다.
리퀘스트 메시지에는 "무엇을", "어떻게" 하겠다는 내용이 포함된다.
"무엇을" : URI로 엑세스 대상을 통칭하는 말
"어떻게" : 메서드(GET, POST)에 의해 웹 서버에 어떤 동작을 하고 싶은지를 전달
응답 메시지에는 실행 결과가 정상 종료되었는지 또는 이상이 발생했는지를 나타내는 스테이터스 코드가 있습니다.
IP 주소
TCP/IP는 서브넷이라는 작은 네트워크를 라우터로 접속하여 전체 네트워크가 만들어진다고 생각할 수 있다.
서브넷 : 허브에 몇 대의 PC가 접속된 것이라고 생각해도 좋다. 이것을 한 개의 단위로 생각하여 서브넷이라고 부르는데 라우터에서 연결하면 네트워크 전체가 완성됩니다.
oo동 oo번지라는 형태로 네트워크 주소를 할당하는데 동에 해당하는 번호를 네트워크 번호라고 하고 번지에 해당하는 번호를 호스트 번호라고 한다. 이 두 주소를 합쳐서 IP 주소라고 합니다.
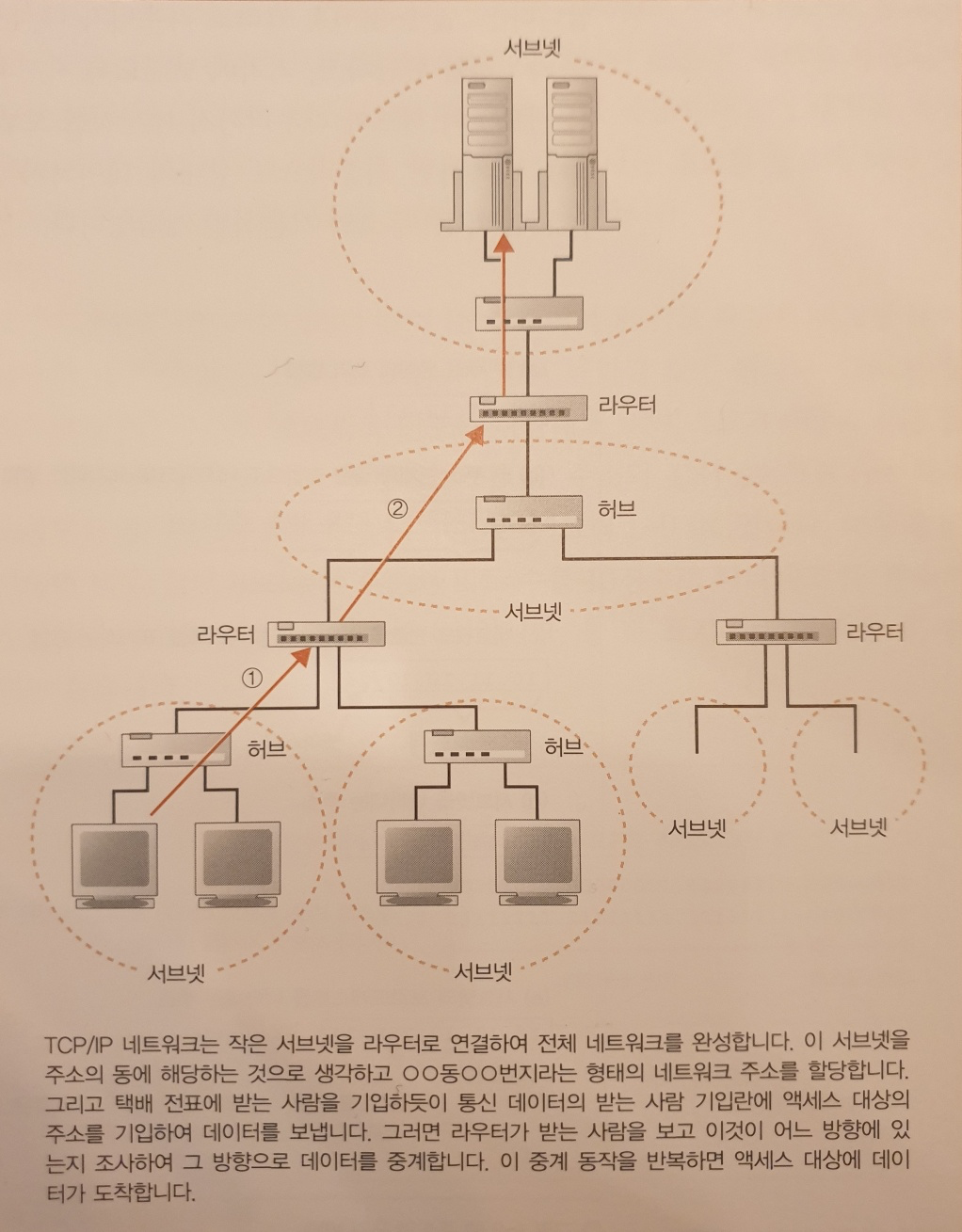
엑세스 대상의 서버까지 메시지 운반 과정
1. IP 주소에 따라 액세스 대상이 어디에 있는지 판단하고 운반한다.
2. 서브넷 안에 있는 허브가 운반하고 송신측에서 가장 가까운 라우터까지 도착한다.
3. 라우터가 메시지를 보낸 상대를 확인하여 다음 라우터를 판단하고 보내도록 지시한다.
4. 다시 서브넷의 허브가 라우터까지 메시지를 보낸다.
5. 1 ~ 4 반복
실제 IP주소는 32비트의 디지털 데이터로 이것을 8비트씩 점으로 구분하여 10진수로 표기한다.
이것만으로는 어느 부분이 네트워크 번호인지 또는 호스트 번호인지 알 수 없다.
이를 나타내는 정보를 필요에 따라 IP 주소에 덧붙이는데 이 정보를 넷마스크라고 한다.
넷마스크가 1인 부분은 네트워크 번호를 나타내고 넷마스크가 0인 부분은 호스트 번호를 나타낸다.

도메인명과 IP주소를 구분하여 사용하는 이유
1. 숫자로 나열한 IP주소는 기억하기 어렵다.
2. IP주소는 4바이트만 차지하지만 도메인명은 수십바이트를 차지해 라우터가 부하되어 데이터를 운반하는 동작에 더 많은 시간이 걸리면서 네트워크 속도가 느려진다.
DNS 기본 개념
이름을 알면 IP주소를 알 수 있다거나 IP주소를 알면 이름을 알 수 있다는 원리를 사용해 양쪽의 차이를 해소하는 원리가 DNS이다.
IP주소를 찾는 방법은 가장 가까운 DNS 서버에 서버의 IP주소를 가르쳐 주세요라고 질문하는 것이다.
DNS 서버에 조회한다는 것은 DNS 서버에 조회 메시지를 보내고 거기에서 반송되는 응답 메시지를 받는 것이다.
이것은 DNS 서버에 대해 클라이언트로 동작한다고 말할 수 있는데 DNS 리졸버 또는 리졸버라고 부른다.
네임 리졸루션 : DNS원리를 사용하여 IP주소를 조사하는 것
리졸버 : 리졸루션을 실행하는 것으로 리졸버의 실체는 Socket 라이브러리에 들어있는 부품화한 프로그램이다.
Socket 라이브러리는 OS에 포함되어 있는 네트워크의 기능을 애플리케이션에서 호출하기 위한 부품을 모아놓은 것이다.
리졸버는 그 속에 들어있는 프로그램 부품의 하나이다.
리졸버의 프로그램 명과 웹 서버의 이름을 쓰기만 하면 리졸버를 호출 할 수 있다.
이렇게 해서 리졸버를 호출하면 DNS 서버에 조회 메시지를 보내고 DNS서버에서 응답 메시지가 돌아온다.
이 응답 메시지 속에 IP주소가 포함되어 있으므로 리졸버는 이것을 추출하여 브라우저에서 지정한 메모리 영역에 써넣습니다.
리졸버 내부 동작 과정
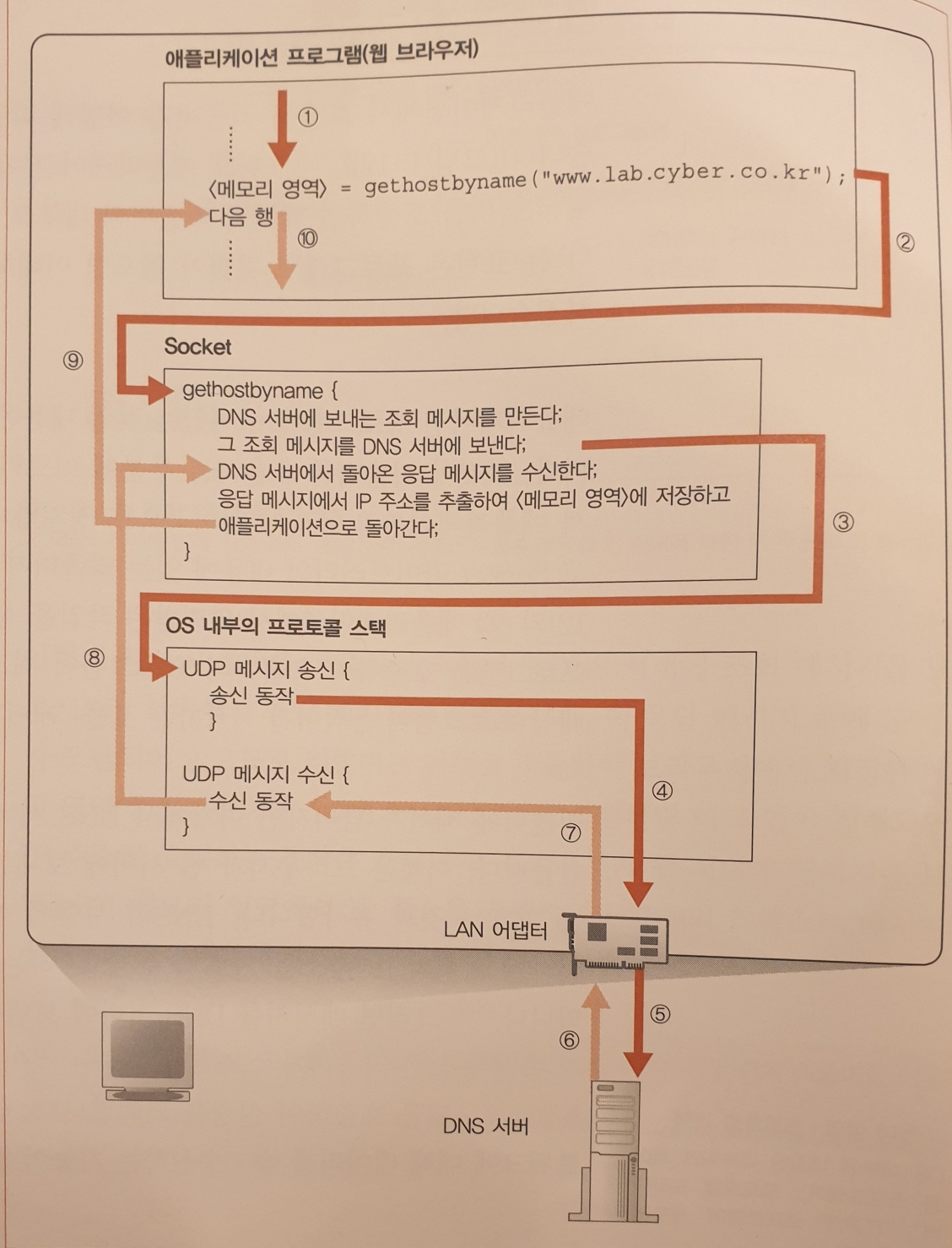
DNS서버에 메시지를 송신할 때도 DNS 서버의 IP주소가 필요한데 이것은 TCP/IP 설정 항목 하나하나로 컴퓨터에 미리 설정되어 있다.
DNS 서버의 기본 동작
DNS 서버의 기본 동작은 클라이언트에서 조회 메시지를 받고 조회의 내용에 응답하는 형태로 정보를 회답하는 일입니다.
조회 메시지에는 이름, 클래스, 타입이 포함된다.
- 이름 : 목적지
- 클래스 : 인터넷 이외에도 네트워크에서 이용까지 검토하여 이것을 식별하기 위해 클래스라는 정보를 준비했지만 지금은 인터넷 이외의 네트워크가 소멸되었으므로 항상 인터넷을 나타내는 'IN' 값이 됩니다.
- 타입 : 어떤 정보가 지원되는지를 나타낸다. 예를 들어 A이면 이름에 IP주소가 지원되는 것을 나타내며 MX이면 이름에 메일 배송 목적지가 지원된다는 것을 나타낸다. 이 타입에 따라 회답하는 정보의 내용이 달라진다.
그러면 DNS는 서버에 등록된 정보를 찾아서 세가지가 일치하는 것을 찾아 주소를 회답합니다.
실제로는 등록 정보가 설정 파일등에 입력되어 있는데 이를 리소스 레코드라고 부른다.
도메인 계층
인터넷에는 막대한 수의 서버가 있는데 이것을 1대의 DNS 서버에 등록하는 것은 불가능하다.
그렇기 때문에 조회 메시지를 받은 DNS 서버에 정보가 등록되어 있지 않은 경우도 생긴다.
이럴 경우 정보를 분산시켜서 다수의 DNS 서버에 등록하고 다수의 DNS 서버가 연대하여 어디에 정보가 등록되어 있는지를 찾아내는 구조입니다.
DNS 서버에 등록한 정보에는 모든 도메인명 이라는 계층적 구조를 가진 이름이 붙여져 있다.
DNS에서 취급하는 이름은 www.naver.com 처럼 점으로 구분되어 있는데 이 점이 계층을 구분한다.
오른쪽에 위치한 것이 상위 계층을 나타낸다.
com -> naver -> www
naver 에 해당하는 것을 도메인 이라고 한다.
도메인마다 서브 도메인을 만들어 여러 도메인을 할당 할 수 있다.
DNS 서버에 등록한 정보를 찾아내는 방법
엑세스 대상의 웹 서버가 어느 DNS 서버에 등록되어 있는지를 찾아내는 방법이다.
1. 하위의 도메인을 담당하는 DNS 서버의 IP주소를 그 상위의 DNS 서버에 등록한다.
2. 상위의 DNS 서버를 또 그 상위의 DNS 서버에 등록하는 식으로 차례대로 등록한다.
com이나 kr의 상위에 또 하나의 루트 도메인이라는 도메인이 있다.
www.naver.com. 처러 끝에 마침표를 찍어서 루트 도메인을 나타내지만 생략하므로 알아차리지 못한다.
루트 도메인의 DNS 서버를 인터넷에 존재하는 DNS 서버에 전부 등록하는 것이다.
이렇게 해서 DNS 서버도 루트 도메인에 엑세스하면 여기에서부터 루트 도메인을 경유하여 도메인의 계층 아래로 찾아가서 최종적으로 원하는 DNS 서버에 도착한다.
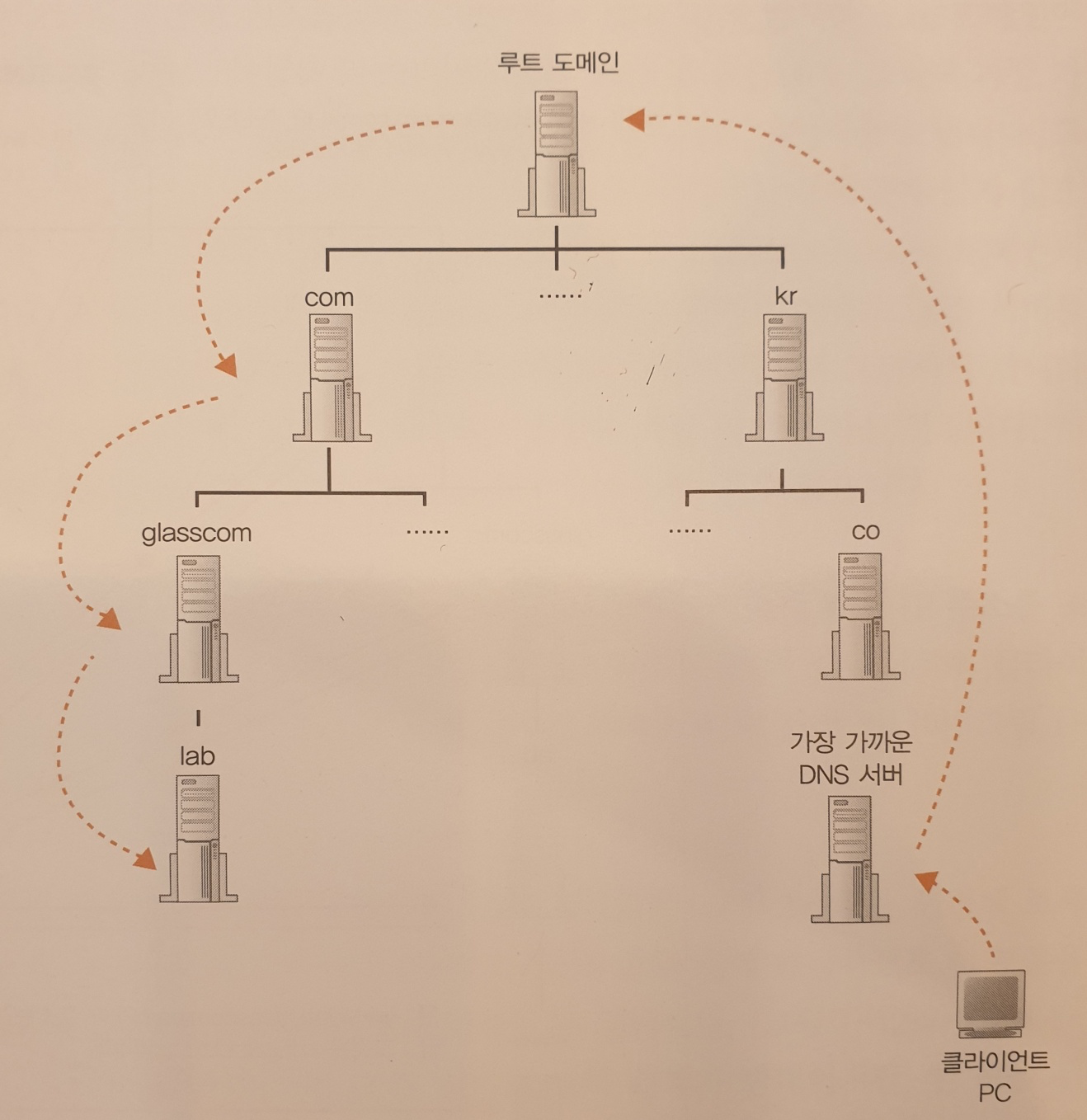
DNS 서버는 캐싱 기능으로 빠르게 회답할 수 있다.
현실의 인터넷에서는 한대의 DNS 서버에 복수 도메인 정보를 등록할 수 있으므로 각 도메인이 한대씩 DNS 서버에 존재한다고 단정할 수 없다.
DNS 서버는 한 번 조사한 이름을 캐시에 기록할 수 있는데 조회한 이름에 해당하는 정보가 캐시에 있으면 그 정보를 회답한다.
캐시에 정보를 저장한 후 등록 정보가 변경되는 경우도 있으므로 유효 기간을 설정하고 기간이 지나면 삭제한다.
또한 회답할 때 정보가 캐시에 저장된 것인지 아니면 등록처 DNS 서버에스 회답한 것인지를 알려준다.
데이터 송수신 동작 개요
IP주소를 조사했으면 IP주소의 상대, 액세스 대상 웹 서버에 메시지를 송신하도록 OS의 내부에 있는 프로토콜 스택에 의뢰한다.
디지털 데이터를 송수신하는 동작은 브라우저뿐만 아니라 네트워크를 이용하는 애플리케이션 전체에 공통입니다.
이 동작은 모든 애플리케이션에 해당한다.
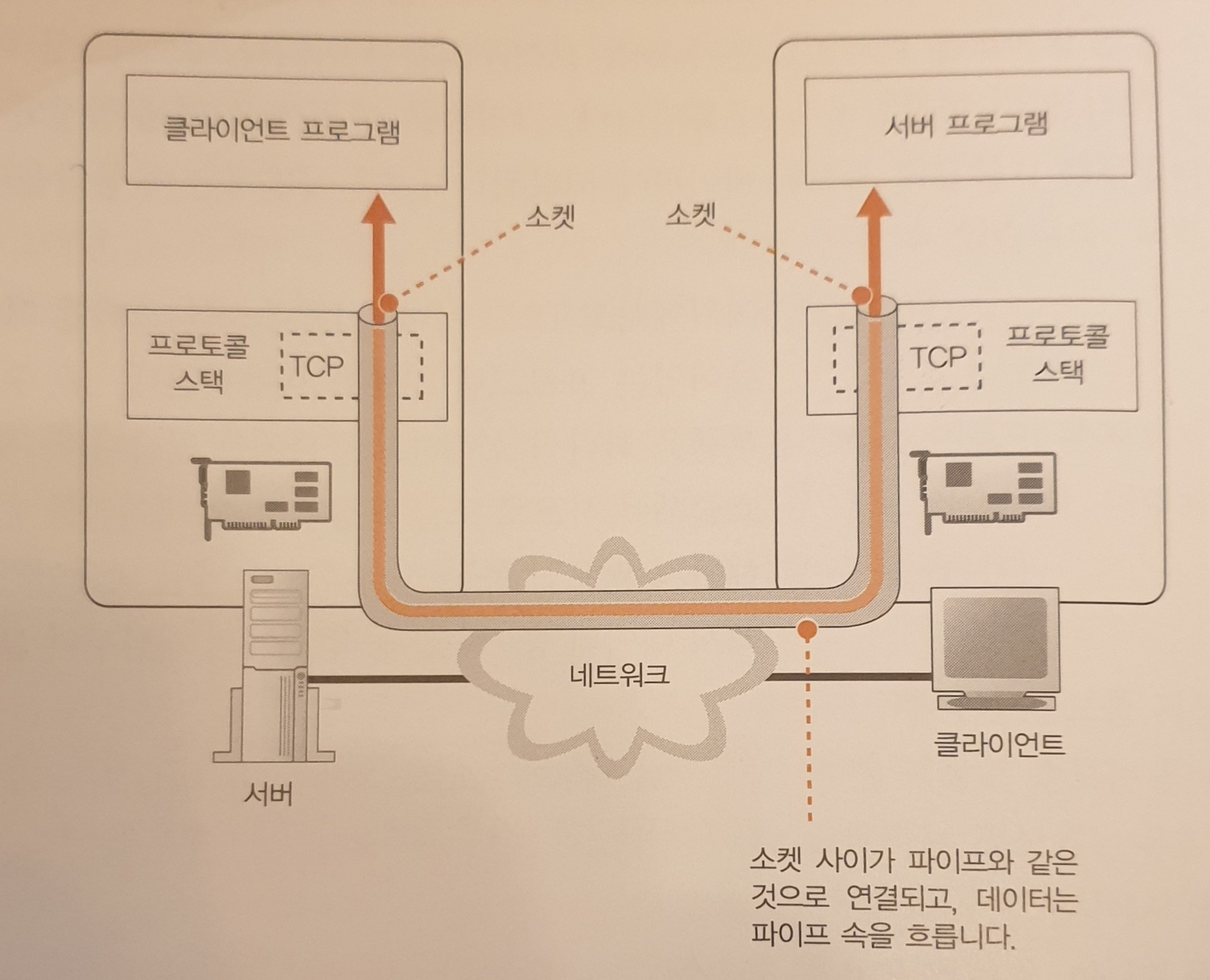
송수신 동작을 하기 전에 송신자와 수신자를 파이프로 연결하는 동작이 필요하다.
파이프 양끝에 있는 데이터의 출입구인데 이 출입구를 소켓이라고 한다.
- 소켓을 만든다.
- 서버측의 소켓에 파이프를 연결한다.
- 데이터를 송수신한다.
- 파이프를 분리하고 소켓을 말소한다.
네 가지 동작을 실행하는 것은 OS 내부의 프로토콜 스택이다.
애플리케이션은 자체에서 파이프를 연결하거나 데이터를 쏟아붓지 않고 프로토콜 스택에 의뢰해서 파이프를 연결하거나 데이터를 쏟아붓는다.
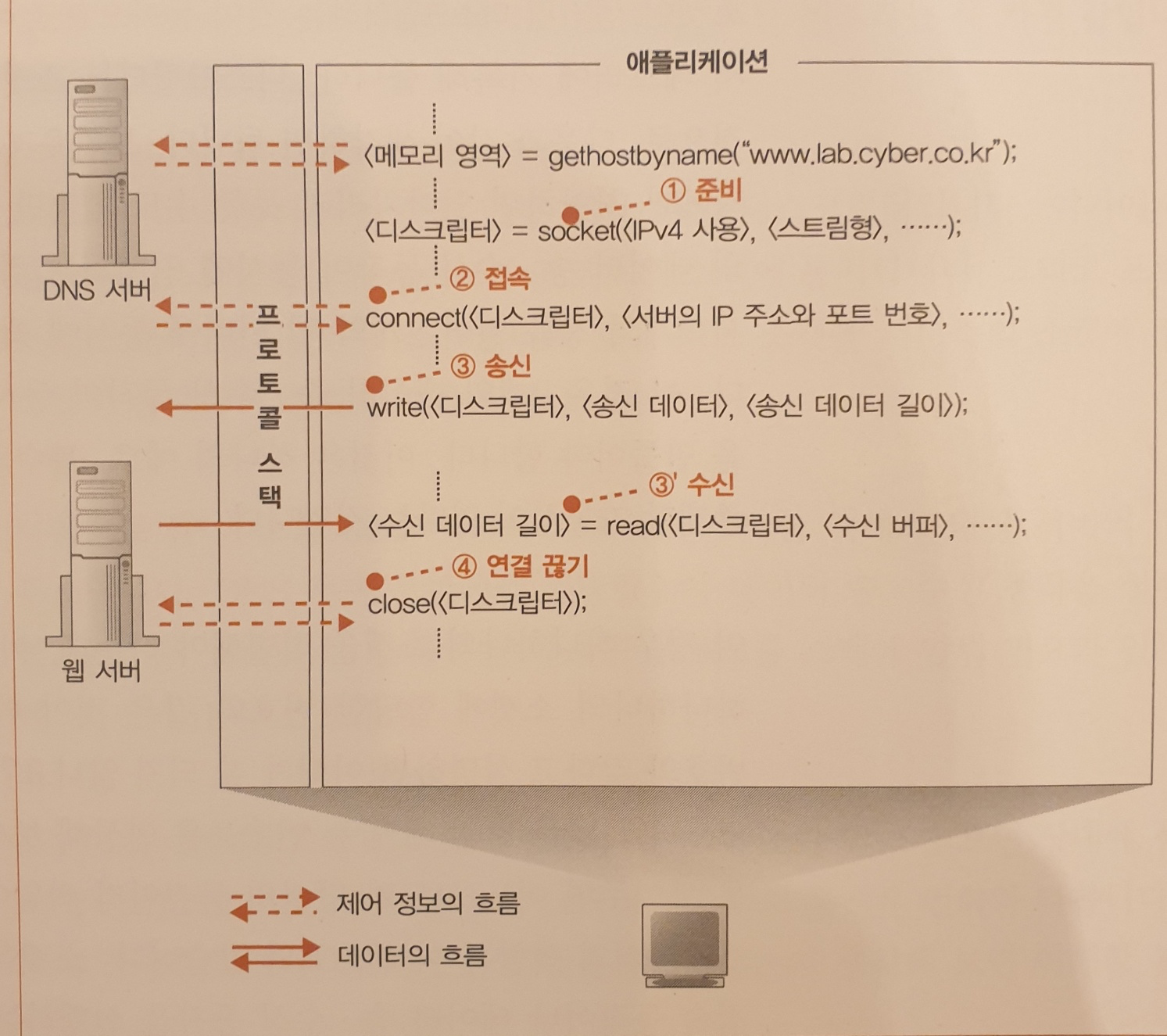
소켓 작동 방식
소켓이 생기면 디스크립터라는 것이 돌아오므로 애플리케이션은 이것을 메모리에 기록해 둡니다.
디스크립터는 소켓을 식별하기 위해 사용하는 것으로 컴퓨터 내부에서는 복수의 데이터 송수신 동작이 동시에 진행되는 경우가 있기 때문에 복수의 소켓이 한 대의 컴퓨터에 존재할 가능성이 있다.
이 경우 소켓을 식별하는 방법이 디스크립터이다.
파이프를 연결하는 접속 단계
소켓을 서버측의 소켓에 접속하도록 프로토콜 스택에 의뢰한다.
애플리케이션은 Socket라이브러리의 connect라는 프로그램 부품을 호출하여 이 의뢰 동작을 실행한다.
여기서 요점은 connect 할 때 지정하는 디스크립터, 서버의 IP주소, 포트 번호 세 가지 값이다.
IP주소와 포트 번호를 지정해야 어느 컴퓨터의 소켓에 접속할지 지정할 수 있다.
디스크립터를 직접 지정하면 좋겠다고 생각할 수 있지만 디스크립터는 소켓을 만들도록 의뢰한 애플리케이션에 건네주는 것이지 접속 상대에 건네주는 것이 아니므로 접속 상대측에서는 그 값을 모릅니다. 서버츨 소켓의 디스크립터는 클라이언트에서 알 수 없으므로 클라이언트측에서 서버측의 디스크립터를 사용하여 서버측의 소켓을 지정할 수 없다.
그래서 클라이언트측에 알리는 중간 과정이 포트 번호이다.
디스크립터는 컴퓨터 내부에서 소켓을 식별하기 위해 사용하고 포트 번호는 상대측에서 소켓을 식별하기 위해 사용한다.
서버측의 포트 번호는 애플리케이션의 종류에 따라 미리 결정된 값을 사용한다는 규칙이 있다.
서버에서도 클라이언트측의 소켓의 번호가 필요할 텐데 먼저 클라이언트측의 소켓의 포트 번호는 소켓을 만들 때 프로토콜 스택이 적당한 값을 골라서 할당합니다. 그리고 이 값을 프로토콜 스택이 접속 동작을 실행할때 서버측에 통지한다.
connect를 호출하면 프로토콜 스택이 접속 동작을 실행합니다. 그리고 상대와 연결되면 프로토콜 스택은 연결된 상대의 IP주소나 포트 번호등의 정보를 소켓에 기록한다.
이로써 데이터 송수신이 가능한 상태가 된다.
