왜 MySQL인가?
MySQL의 경쟁력은 가격이나 비용이다.
방대한 양의 데이터를 저장하기에 오라클 RDBMS는 너무 비싸다.
자기가 가장 잘 활용 할 수 있는 DBMS가 가장 좋은 DBMS이지만 고민된다면 다음과 같은 기준으로 결정할 수 있다.
- 안정성
- 성능과 기능
- 커뮤니티나 인지도
때로는 성능이나 기능을 안정성보다 중요시하는 사람들이 있는데 성능이나 기능은 돈이나 노력으로 해결되지만 안정성은 그렇지 않다.
안정성 다음으로 성능과 기능을 고려해보고 그다음으로 커뮤니티나 인지도도 함께 고려해보라.
인지도가 적은 DBMS는 필요한 경험이나 지식을 구하기 어렵다.
CAP Theorem
CAP 이론은 기본적으로 분산된 시스템을 가정한다. 모든 분산 데이터 저장소가 3가지 보장 중 2가지만 보장한다.
- consistency(일관성)
데이터를 저장하는 장비가 1대 든 100대든 모든 장비에서 동일한 데이터가 저장되어 있어야 한다는 것이다. 이러한 상황이 발생하려면, 데이터가 하나의 노드에 기록될 때마다 이 데이터는 쓰기가 '성공'으로 간주되기 전에 시스템의 다른 모든 노드로 즉시 전달되거나 복제되어야 합니다. 따라서 응답이 지연될 수 있다.
- availability(가용성)
하나 이상의 노드가 작동 중지된 경우에도 데이터를 요청하는 클라이언트가 응답을 받음을 의미한다. 현재 시스템에 문제가 있어서 읽을 수 없다고 보내면 가용성이 보장되지 않는 것을 뜻한다. 하지만 접근하는 노드에 따라 값이 다르거나 해당 response가 가장 최근 데이터라는 것을 보장받을 수 없다.
- partition-tolerance(파티션 허용)
파티션이란 분산 시스템 내의 통신 단절, 즉 두 노드 간의 연결이 유실되거나 일시적으로 지연된 상태입니다. 시스템의 노드 간에 다수의 통신 단절에도 불구하고 클러스터가 계속해서 작동해야 함을 의미합니다.
availability vs partition-tolerance
가용성은 노드에서 장애가 발생하여 Down 되었을 때, 분할 내구성은 노드간의 통신이 정상적으로 이루어지지 않을 때
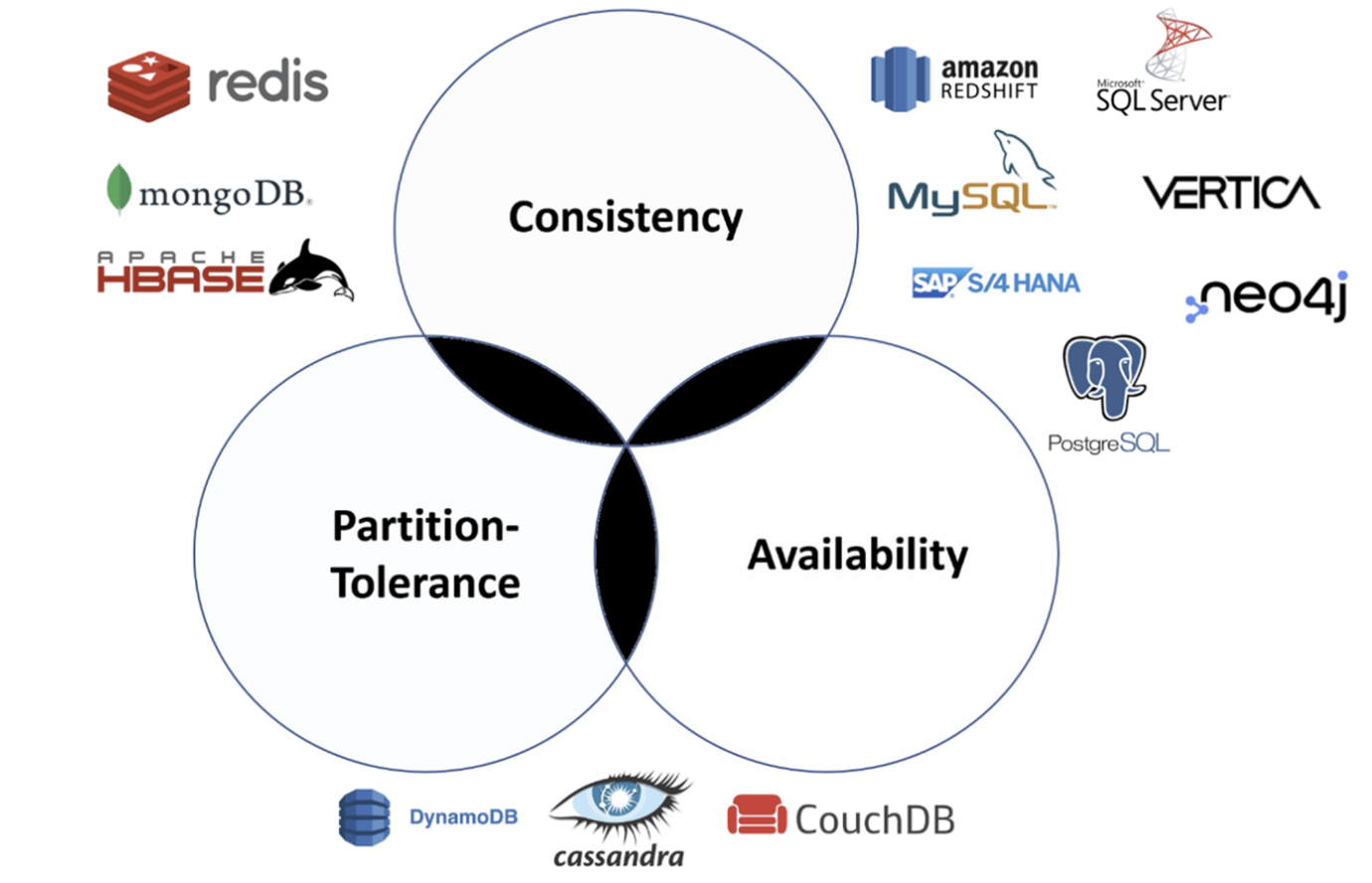
- CP 데이터베이스
CP 데이터베이스는 가용성을 희생하면서 일관성과 파티션 허용을 제공합니다. 두 노드 간에 파티션이 발생하면, 시스템은 파티션이 해결될 때까지 일관되지 않은 노드를 종료(즉, 사용 불가능하게)해야 합니다.
- AP 데이터베이스
AP 데이터베이스는 일관성을 희생하면서 가용성과 파티션 허용을 제공합니다. 파티션이 발생하면 모든 노드를 사용할 수 있지만, 파티션의 잘못된 끝에 있는 노드는 다른 데이터보다 이전 버전의 데이터를 리턴할 수 있습니다. (파티션이 해결되면, AP 데이터베이스는 일반적으로 시스템의 모든 불일치를 복구하기 위해 노드를 재동기화합니다.)
- CA 데이터베이스
CA 데이터베이스는 모든 노드에서 일관성과 가용성을 제공합니다. 그러나 CAP 이론은 네트워크 파티션 상황을 가정하므로 CA 시스템은 있을 수 없다. CA 시스템이 가능하려면 네트워크 파티션이 없어야 하는데 네트워크 파티션이 없으면 CAP 이론 자체가 쓸모 없을 뿐더러, 네트워크 파티션은 어떤 이유에서든 발생할 수 있다. 그러나 이는 하나를 보유한 경우 분산 애플리케이션에 대해 CA 데이터베이스를 보유할 수 없음을 의미하지는 않습니다. 많은 관계형 데이터베이스(예: PostgreSQL)는 일관성과 가용성을 제공하며, 복제를 사용하여 여러 노드에 배치될 수 있습니다.
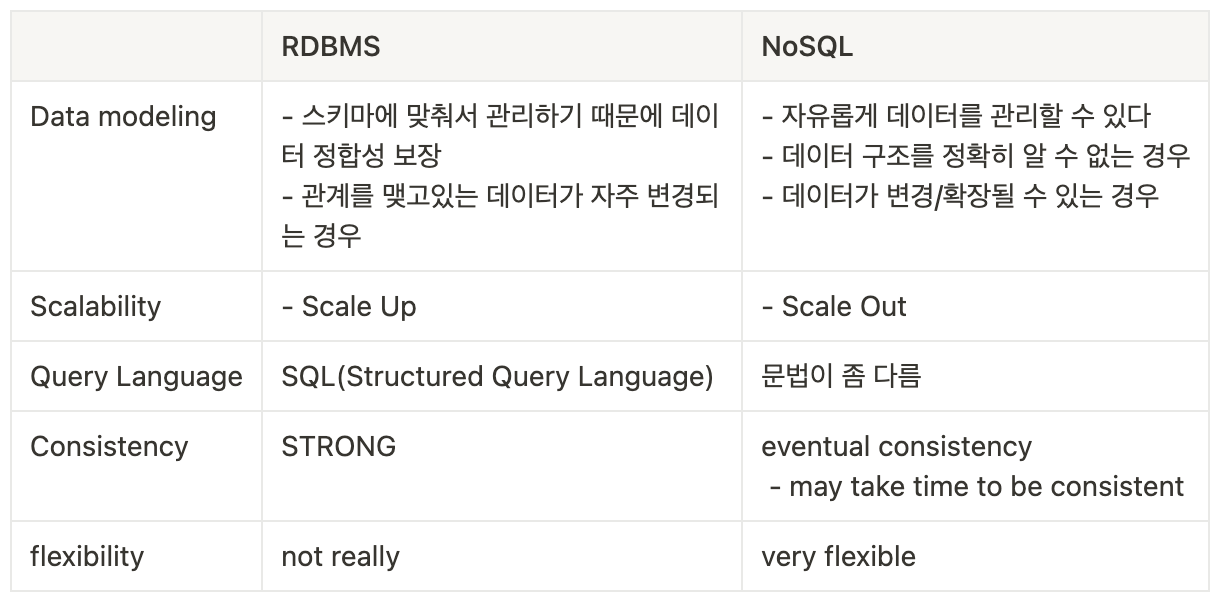
RDBMS vs NoSQL
MySQL vs PostgreSQL
- 데이터 타입
PostgreSQL은 다양한 데이터 타입을 지원하며, 사용자 정의 데이터 타입을 만들 수 있습니다. 예를 들어, PostgreSQL은 배열, hstore(키-값 저장소), JSON, JSONB, 범위 타입 및 기하학적 타입을 지원합니다. 반면에 MySQL도 여러 데이터 타입을 지원하지만, PostgreSQL만큼 다양하지 않습니다.
- 확장성
PostgreSQL은 다양한 확장 기능을 지원하며, 사용자가 쉽게 기능을 추가할 수 있습니다. 예를 들어, 풀 텍스트 검색, 데이터 압축, 인덱싱 기능 등을 제공하는 확장 모듈을 사용할 수 있습니다. MySQL도 플러그인을 통해 기능을 확장할 수 있지만, PostgreSQL보다 제한적입니다.
- 인덱싱
PostgreSQL은 다양한 인덱싱 기능을 제공합니다. B-tree, Hash, GiST, SP-GiST, GIN 및 BRIN 등의 인덱스 타입을 지원합니다. 이러한 인덱스는 데이터베이스 성능을 최적화하는 데 도움이 됩니다. MySQL도 여러 인덱스 타입을 제공하지만, PostgreSQL만큼 다양하지 않습니다.
- 저장 프로시저
PostgreSQL은 PL/pgSQL, PL/Tcl, PL/Perl 등 다양한 프로그래밍 언어로 저장 프로시저를 작성할 수 있습니다. 반면에 MySQL은 저장 프로시저 작성에 주로 SQL/PSM을 사용합니다.
- 아키텍처
MySQL은 멀티 스레드 아키텍처를 사용합니다. 이는 한 개의 프로세스 안에서 여러 스레드를 생성하여 동시에 다수의 클라이언트 연결을 처리할 수 있습니다. 이로 인해 자원 공유가 더욱 효율적이고, 스레드 간 컨텍스트 스위칭 오버헤드가 적습니다. 그러나 멀티 스레드 아키텍처는 스레드 간의 동기화 문제와 공유 자원 경쟁 문제에 민감할 수 있습니다.
PostgreSQL은 멀티 프로세스 아키텍처를 사용합니다. 이는 각 클라이언트 연결에 대해 별도의 프로세스를 생성하여 처리합니다. 멀티 프로세스 아키텍처는 각 프로세스가 독립적으로 실행되기 때문에 프로세스 간의 동기화 문제가 덜 발생하며, 프로세스 간의 격리가 더 용이합니다. 그러나 프로세스 간 컨텍스트 스위칭 오버헤드와 자원 사용량이 더 크다는 단점이 있습니다.
- MVCC
MySQL의 InnoDB 스토리지 엔진은 MVCC를 사용하여 트랜잭션 동시성을 처리합니다. InnoDB에서 MVCC는 각 트랜잭션에 대해 행을 읽을 때 해당 행의 스냅샷을 제공합니다. 이 스냅샷은 트랜잭션의 시작 시점의 데이터 상태를 보여줍니다.
InnoDB는 각 행에 대해 생성 시각과 삭제 시각을 나타내는 시스템 필드를 포함합니다. 이러한 시스템 필드는 트랜잭션 ID를 사용하여 트랜잭션의 시작과 종료 시점을 결정합니다. 트랜잭션이 행을 읽을 때 이 시스템 필드를 확인하여 해당 행이 트랜잭션에 적용되어야 하는지 여부를 결정합니다. 이 방식으로 동시에 수행되는 트랜잭션 간의 충돌을 방지하며, 동시성을 높이게 됩니다.
PostgreSQL 역시 MVCC를 사용하여 동시성을 처리합니다. PostgreSQL의 MVCC 구현 방식은 MySQL의 InnoDB와 유사하지만, 일부 차이점이 있습니다.
PostgreSQL에서는 각 행에 xmin과 xmax라는 시스템 칼럼을 포함시킵니다. xmin 칼럼은 해당 행을 생성한 트랜잭션의 ID를 나타내며, xmax 칼럼은 해당 행을 삭제한 트랜잭션의 ID를 나타냅니다. PostgreSQL은 트랜잭션이 행을 읽을 때 이 시스템 칼럼을 사용하여 트랜잭션의 시점에 따라 행의 가시성을 결정합니다.
PostgreSQL의 MVCC 구현은 트랜잭션 ID를 통해 행의 가시성을 관리하며, 트랜잭션 간의 충돌을 방지합니다. 하지만 이 과정에서 불필요한 행 버전이 쌓이게 되면, VACUUM 프로세스를 통해 이러한 행 버전을 정리해야 합니다.
- Replication
PostgreSQL
마스터-스탠바이 구성에서 사용되며, 데이터의 일관성과 가용성을 높이기 위한 목적으로 활용됩니다.
비동기 복제 (Asynchronous Replication):
비동기 복제는 마스터가 트랜잭션을 커밋한 후 스탠바이에게 데이터를 전송하지만, 스탠바이가 데이터를 수신하고 적용하는 것을 기다리지 않습니다. 이로 인해 마스터는 빠르게 다음 작업을 처리할 수 있으며, 성능이 향상됩니다. 그러나 비동기 복제에서는 네트워크 지연이나 스탠바이의 처리 속도에 따라 데이터 불일치가 발생할 수 있습니다.
동기 복제 (Synchronous Replication):
동기 복제는 마스터가 트랜잭션을 커밋한 후 스탠바이에게 데이터를 전송하고, 스탠바이가 데이터를 수신하고 적용할 때까지 기다립니다. 이 방식은 데이터의 일관성을 높여주지만, 마스터가 스탠바이의 처리를 기다려야 하므로 성능에 영향을 줄 수 있습니다.
PostgreSQL에서는 사용자가 요구 사항과 시스템 구조에 따라 동기 및 비동기 복제 방식을 선택할 수 있습니다. 동기 복제를 사용하면 데이터 일관성이 높아지지만 성능에 영향을 받을 수 있으며, 비동기 복제를 사용하면 성능이 향상되지만 데이터 불일치의 위험이 있습니다.
MySQL
마스터-슬레이브 구성에서 사용되며, 데이터의 가용성을 높이고 부하 분산을 위한 목적으로 활용됩니다.
비동기 복제 (Asynchronous Replication):
MySQL의 비동기 복제에서는 마스터 서버가 트랜잭션을 커밋한 후 슬레이브 서버에 데이터를 전송합니다. 그러나 마스터는 슬레이브가 데이터를 수신하고 적용할 때까지 기다리지 않고 빠르게 다음 작업을 처리합니다. 이로 인해 마스터의 성능이 향상되지만, 네트워크 지연이나 슬레이브의 처리 속도에 따라 데이터 불일치가 발생할 수 있습니다.
MySQL에서는 복제의 성능과 안정성을 높이기 위한 다양한 기능과 옵션을 제공합니다. 예를 들어, 세미 동기 복제(Semi-Synchronous Replication)를 사용하여 동기와 비동기 복제 사이의 절충안을 선택할 수 있습니다.
세미 동기 복제 (Semi-Synchronous Replication):
MySQL의 세미 동기 복제는 마스터 서버가 트랜잭션을 커밋한 후 슬레이브 서버에 데이터를 전송하고, 슬레이브가 데이터를 수신했다는 확인 응답을 받을 때까지 기다립니다. 그러나 슬레이브가 데이터를 적용하는 것까지 기다리지는 않습니다. 이 방식은 데이터 일관성과 성능 간의 절충안을 제공하며, 데이터 불일치의 위험을 줄일 수 있습니다.
MySQL에서는 사용자의 요구 사항과 시스템 구조에 따라 비동기 복제 또는 세미 동기 복제를 선택할 수 있습니다.
그러면 PostgreSQL을 사용해야 하는가?
비용적인 측면과 사용 편의성에 의해 MySQL도 선택지 중 하나가 될 것 같다.
출처
https://www.ibm.com/kr-ko/cloud/learn/cap-theorem
https://techblog.woowahan.com/6550/
