matplotlib 기초
# 간단한 라인차트
# plt.figure(figsize=(가로, 세로)) # 사이즈 조절
plt.plot(df['col1'])
plt.show()축 관련
# x축 label 기울기 조정
plt.xticks(rotation=30)
# label, title
plt.xlabel('x축이름')
plt.ylabel('y축이름')
plt.title('그래프 이름')
선 스타일 변경
color: red, green, blue, r, g, b...linestyle: solid(-), dashed(--), dashdot(-.), dotted(:)marker: point(.), pixel(,), circle(o), triangle(v, ^, <, >)
# 선 스타일 변경
plt.plot(df['col1'],
color = 'red',
linestyle = 'solid',
marker = '.')범례 및 그리드
plt.plot(df['col1'], label='col1')
plt.legend()
plt.grid()수평/수직선, 텍스트
# color, linestype 옵션 사용 가능함
# 수평
plt.axhline(y좌표숫자)
# 수직
plt.axvline(x좌표숫자)
# 텍스트
plt.text(x좌표숫자, y좌표숫자, '텍스트내용')
여러 그래프로 나누어 그리기
plt.subplot(row, column, index)
# index는 1부터 시작한다앞으로 이어질 시각화 예시는, kaggle에서 얻을 수 있는 Titanic - Machine Learning from Disaster 데이터 셋을 이용하여 작성하였습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
# 나중을 위해 Survived 컬럼이 있는 train set으로 이용
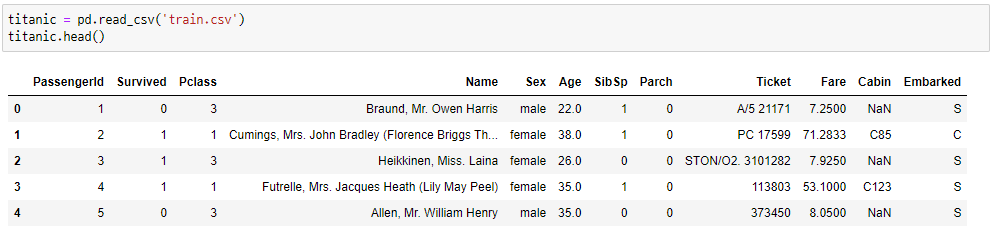
titanic = pd.read_csv('train.csv')
titanic.head()
숫자형 변수
시각화 : 구간별 빈도수 계산 : Box Plot, 도수분포표(히스토그램, Density plot)
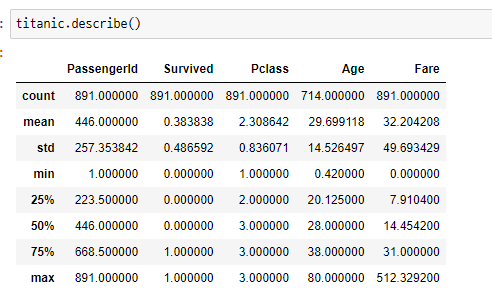
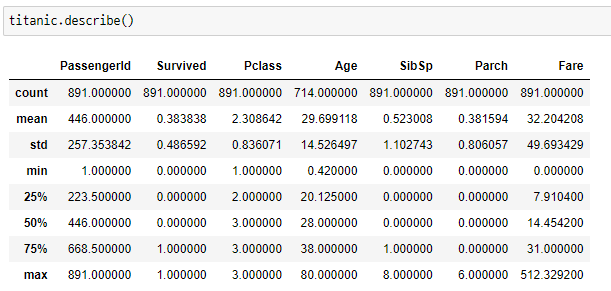
수치화 : 기초 통계량df.describe()
시각화
히스토그램
# plt.hist(컬럼, bins=구간수)
# 데이터 특성에 따라 적절한 bins를 선택한다
# 연령이 0~80세로 구성되어있어 연령대로 보기 위해 구간을 8으로 설정함
plt.hist(titanic['Age'], bins=8, edgecolor='gray')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()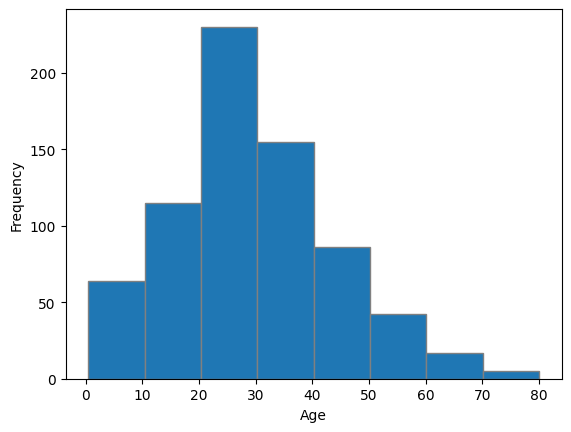
Density Plot
- 히스토그램의 경우, bin수를 어떻게 설정하느냐에 따라 그래프 모양이 달라진다.
- 밀도함수그래프 이용하여 단점 해결 가능
밀도함수그래프: 커널밀도추정(KDE)을 이용한다.- 그래프 아래의 전체 면적 = 1
- 특정 구간의 면적 = 해당 구간에 속할 확률
sns.kdeplot(titanic['Age'])
plt.show()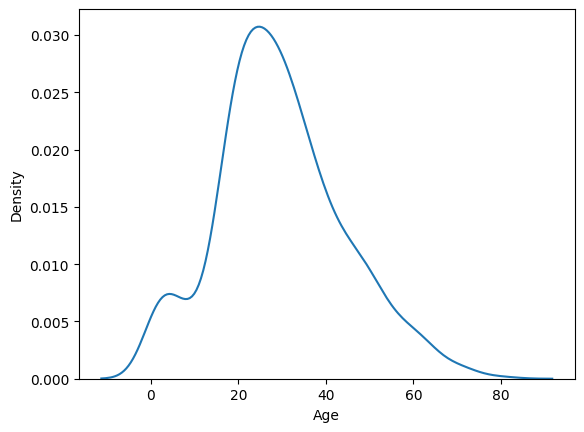
sns.histplot을 이용하여 두 가지를 동시에 그릴 수도 있다.
sns.histplot(titanic['Age'], bins=8, kde=True)
plt.show()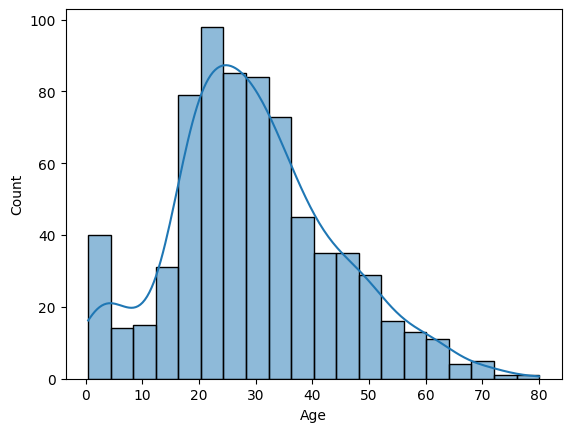
Box Plot
- plt로 그릴 경우 반드시 결측치를 처리해줘야한다.
- 실제로 titanic 데이터셋의 Age에는 결측치가 있어서 처리 전에는 box plot이 그려지지 않는다.
- sns의 경우 알아서 결측치가 처리된다.
알잘딱깔센
세로형
plt.boxplot(titanic['Fare']) # vert는 세로가 default
plt.grid()
plt.show()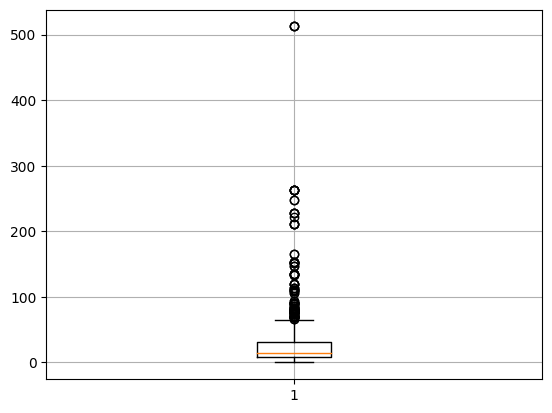
가로형
plt.boxplot(titanic['Fare'], vert=False)
plt.grid()
plt.show()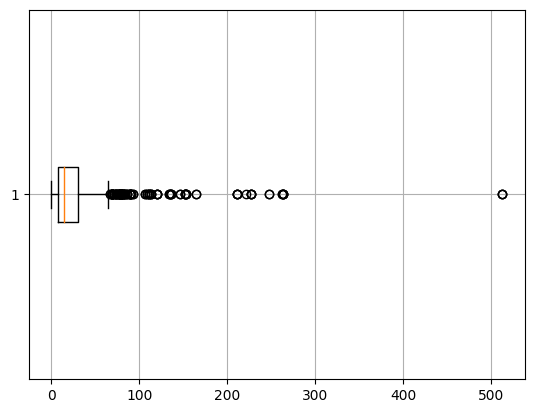
- box plot의 수치들을 직접 가져올 수도 있다.
fare = plt.boxplot(titanic['Fare'])
print(type(fare)) # 딕셔너리
print(fare.keys()) # dict_keys(['whiskers', 'caps', 'boxes', 'medians', 'fliers', 'means'])
print(fare['whiskers'])
# [<matplotlib.lines.Line2D object at 0x0000019E55920390>, <matplotlib.lines.Line2D object at 0x0000019E58C70BD0>]
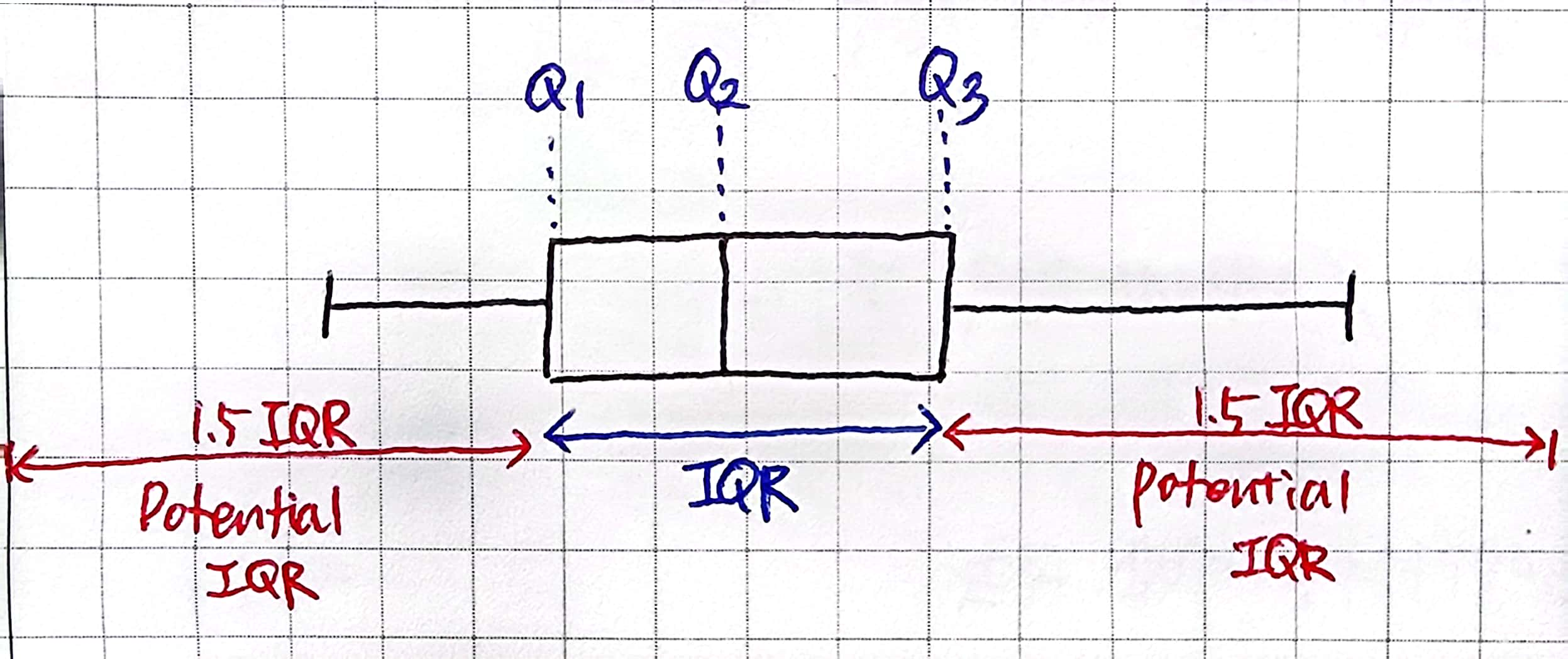
# lower_fance = 수염의 이상적 최소값 (Q1-1.5*IQR)
# upper_fance = 수염의 이상적 최대값 (Q3+1.5*IQR)
print(fare['whiskers'][0].get_ydata())
# 아래쪽 수염의 max, min(Q3) [7.9104 0. ]
print(fare['whiskers'][1].get_ydata())
# 위쪽 수염의 min(Q1), max [31. 65.]Box Plot과 사분위수
수치화
df.describe()- count, mean, std, min, 사분위수, max
범주형 변수
범주별 빈도수/비율
시각화 : Bar plot - countplot
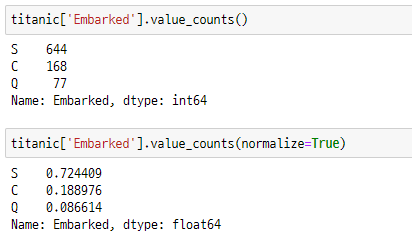
수치화 :df.value_counts()
시각화
Bar Plot
plt.bar의 경우 먼저 집계한 데이터프레임을 따로 선언 후 그려줘야 한다.
sns.countplot
sns.countplot(x=titanic['Pclass'])
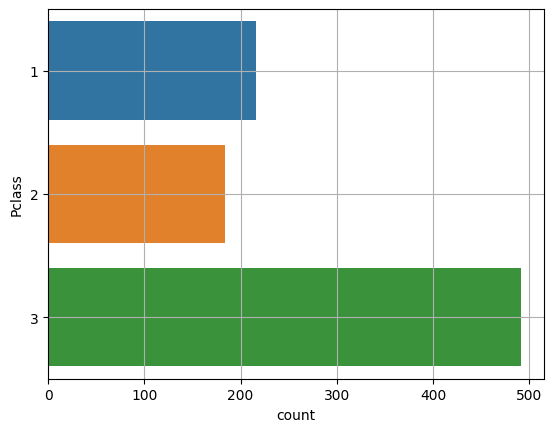
# y로 선택시 두번째 이미지처럼 가로형이 된다.
plt.grid()
plt.show()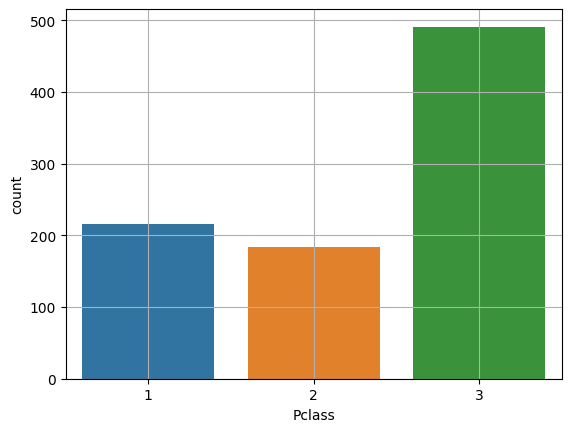
Pie Chart
- 범주형 자료의 범주별 비율을 비교할 수 있다.
- plt를 사용하기에 집계를 해준 뒤 그려줘야 한다.
temp = titanic['Pclass'].value_counts()
plt.pie(temp.values, labels=temp.index, autopct='%.1f%%', startangle=90, counterclock=False, explode=[0.05, 0.05, 0.05], shadow=True)
# autopct = 퍼센트비율로 환산. 소숫점 자릿수 지정가능
# startangle = 시작 각도
# counterclock = 배열 방향
# explode = 파이별 간격 띄우기
# shadow = 그림자 유무
plt.show()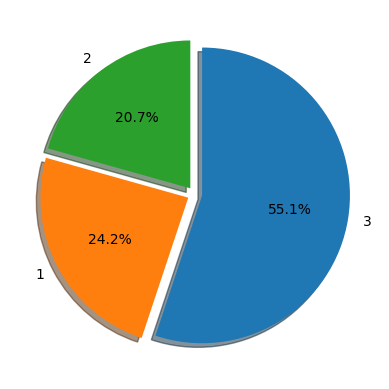
수치화
df.value_counts()normalize=True옵션 사용시 비율로 출력된다.