자세한 내용은 논문을 참고하세요.
Attention is all you need : https://arxiv.org/pdf/1706.03762.pdf
Transformer
- RNN, CNN을 사용하지 않는 대신 Positional Encoding을 사용한다.
- Encoder, Decoder로 구성된다.
- Attention 과정을 여러 layer에서 반복한다.
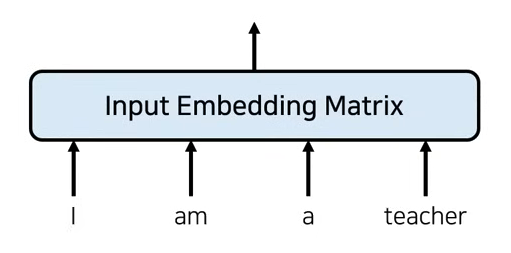
Input Embedding
전통적인 Embedding 방식
-
일반적으로 단어의 개수만큼 행의 크기를 가지고, column data는 embedding dimension과 같은 data가 담긴 matrix를 사용하게 된다.
-
dimension은 지정할 수 있지만 일반적으로 512를 사용한다.
-
순서 정보를 포함하지 않았다.
Embedding + Positional encoding
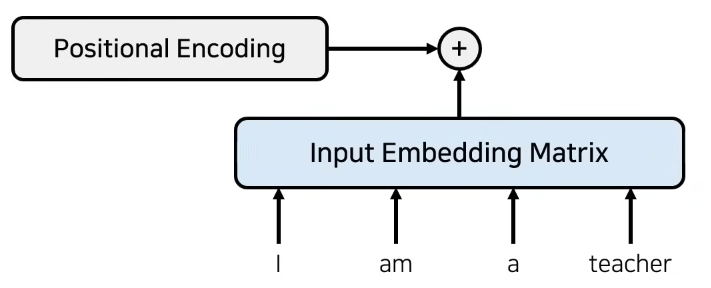
- RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 embedding을 사용해야한다.
- 이를 위해 transformer에서는 positional encoding을 사용한다.
- embedding dimension과 동일한 size의 positional encoding을 진행한다.
Encoder
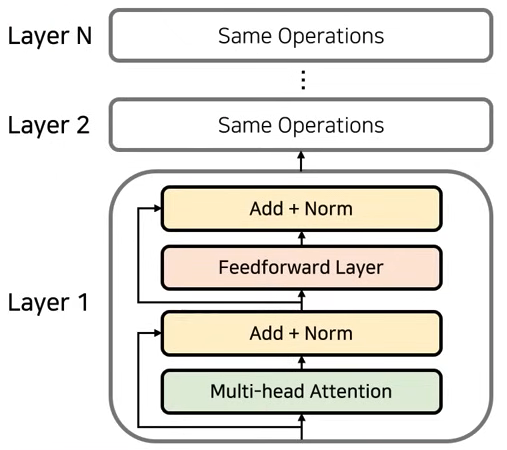
- Embedding이 끝난 이후 Attention을 진행한다.
- 문장이 들어오게 되면, 각 단어가 서로 attention score를 계산하여, 다른 단어와 어떤 연관성을 가지는지 계산
- 문맥에 대한 정보를 학습한다.
- 성능 향상을 위해 residual learning을 사용한다.
- 특정 layer를 건너뛰어 입력값을 그대로 넣어 network는 잔여된 부분만 학습하기 때문에 초기 모델 수렴 속도가 높고 global optima를 찾을 확률이 높아진다.
- 더한 뒤 normalization과정을 진행하면 하나의 encoder layer가 완성된다.
- 이러한 Attention과 normalization 과정을 반복한다.
- 각 layer는 서로 다른 파라미터를 가진다.
- layer1과 layer2의 attention, feedforward의 parameter는 다르다.
- input, output dimension은 동일하다.
Decoder
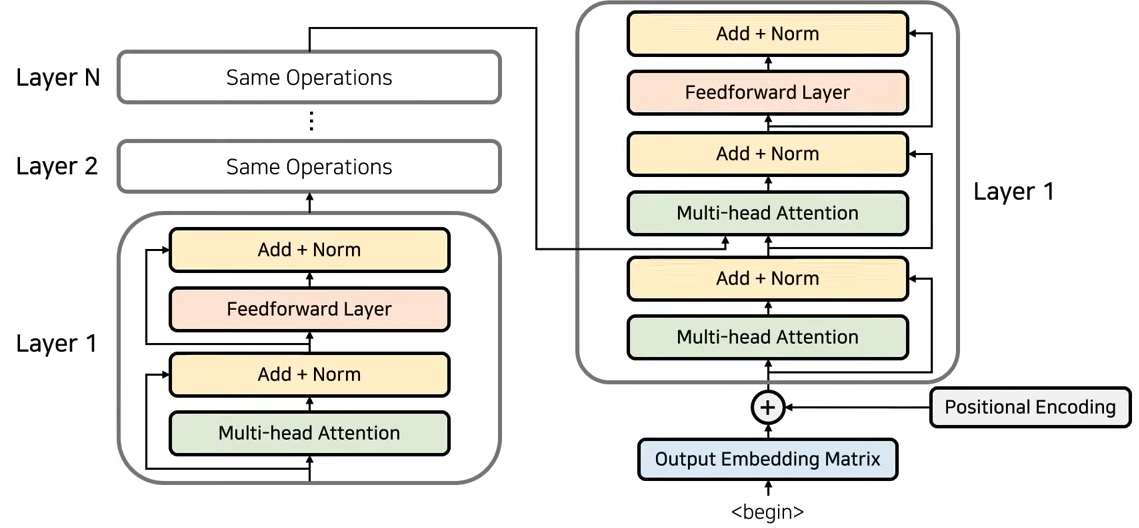
- 전체적으로 seq2seq 모델의 구조를 따라간다.
- decoder도 여러 layer로 구성되고, 각 layer는 encoder의 마지막 layer의 출력값을 입력으로 받게 된다.
- 각 layer의 출력값을 받는 방식도 존재하기는 한다.
- decoder에서 positional encoding을 진행하고 input으로 넣는다.
- 2가지의 attention 방식으로 사용한다.
- Self Attention : encoder와 마찬가지로, 각 단어들이 서로가 서로에게 어떤 영향을 미치는지 attention score를 계산하여 표현하는 작업.
- Encoder-Decoder Attention : Encoder의 출력 정보(source 문장)가 출력 단어와 어떤 연관성이 있는지를 표현
- layer에서의 input, output dimension이 동일하다.
- end of state가 나올 때까지 decoder를 진행한다.
Energy, Weight
- i : 현재의 decoder가 처리 중인 index
- j : 각각의 encoder 출력 index
- Energy : decoder가 출력할 단어를 만들 때마다 encoder의 모든 출력을 고려하는 것.
- : encoder의 각 hidden state 값
- : decoder가 이전 출력 단어를 만들기 위해 사용한 hidden state
- Weight : Energy에 대해 softmax를 취한 것
- Weighted sum을 통해 hidden state값에 대해 가중치를 곱하여 context vector처럼 사용한다.
Positional Encoding
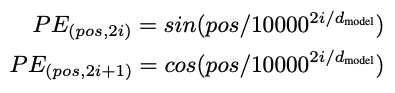
- 각 단어의 상대적인 위치 정보를 네트워크에게 입력한다.
- 주기 함수를 활용한 공식을 사용한다.
- network가 각 입력 문장에 포함된 단어의 상대적인 위치들의 주기성을 학습할 수 있도록 한다.
- : 각 단어의 번호
- : 각 단어의 embedding 값의 위치

한양대학교 인공지능학과 대학원생 조권휘입니다.