자세한 내용은 논문을 참고하세요.
Attention is all you need : https://arxiv.org/pdf/1706.03762.pdf
Attention
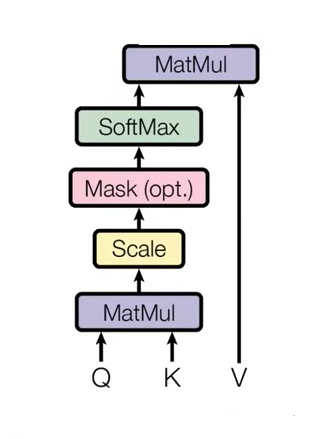
- 어떠한 단어가 다른 단어들과 어떤 연관성을 가지는지 구하는 것
- Attention을 위한 세 가지 입력 요소
- 쿼리(Query) : 물어보는 주체
- 키(Key) : 물어보는 대상
- 값(Value) : 실제 value값
- ex) I am a student (단어는 vector로 표현, value는 임의 값)
- Query : I
- Key : I, am, a, student
- Value : 1 2 3 4
- Query, Key가 들어가서 행렬곱을 수행한 뒤, scaling을 진행하고, 필요하다면 Mask를 진행한 뒤 softmax를 거친다. 각 key 중 어떤 연관성을 가지는지의 비율을 구해지면, 가중치 value를 곱하면 attention value를 구할 수 있게 된다.
Multi-Head Attention
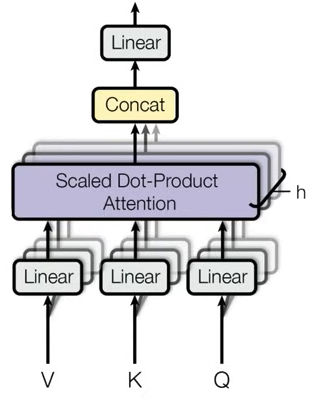
- encoder, decoder는 Multi-Head Attention layer를 사용한다.
- 실제 입력 값들은 h개로 구분된다. 입력 문장은 서로 다른 h개의 K, Q, V로 구분되게 만든다.
- h개의 서로 다른 attention concept을 만들어 더욱 구분된 다양한 특징을 학습할 수 있도록 해준다.
- 입력으로 들어온 값은 V, K, Q로 구분되고, 행렬곱을 진행한 뒤 h개로 구분된 각각의 Query 쌍을 만들게 된다.
- h는 서로 다른 head의 개수이고, 서로 다른 head끼리 V, K, Q 쌍을 받아 attention을 수행한다.
- 입력과 출력의 dimension은 동일해야하기 때문에, concat을 진행하고 linear layer를 거치게 된다.
수식 설명
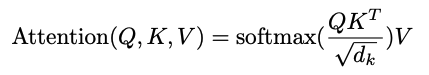
- Query와 Key를 곱하여 energy 값을 곱한다.
- 어떤 key에 대해 높은 가중치를 가지는지 softmax를 통해 계산한다.
- scale factor로써 를 가지며, 이는 각 Key dimension이 된다.
- scale 조정의 이유는 softmax의 특성상 gradient vanishing 문제를 해결하기 위해 진행한다.
- softmax와 value를 곱하여 attention value를 만든다.
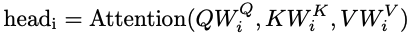
- 입력으로 들어오는 각 값에 대해 서로 다른 linear layer를 거치도록 하여 h개의 서로 다른 Q, K, V를 만들 수 있도록 한다.
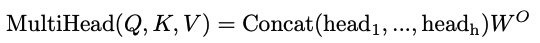
- 구해진 head의 출력 값을 concat한 뒤 output matrix를 곱하여 MultiHead attention value를 구할 수 있게 된다.
- output은 input과 dimension이 동일하다.
Attention 종류
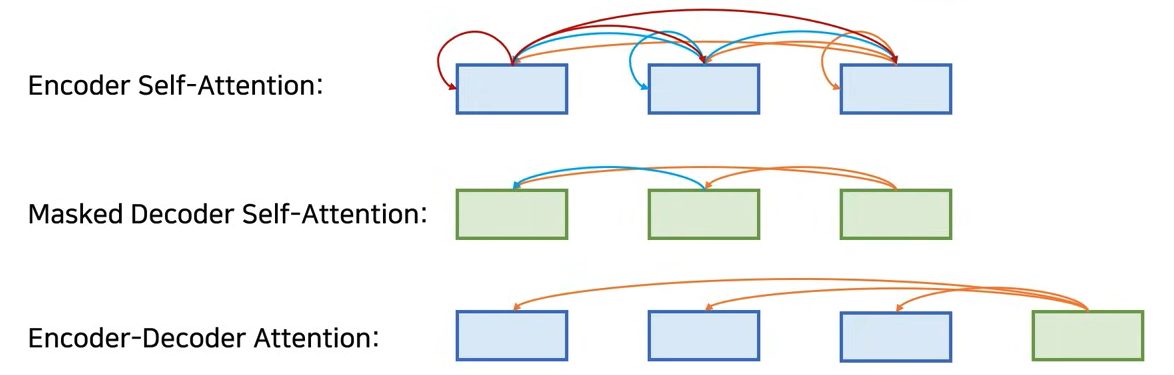
- Transformer에는 세 가지 종류의 Attention이 사용된다.
- 항상 Multi-Head Attention으로 사용되는데, 사용되는 위치에 따라서 세 가지 종류의 attention으로 나눌 수 있다.
- Encoder Self-Attention : Dncoder의 self attention은 각 단어가 서로에게 어떤 연관성이 있는지 만들고, 전체 문장에 대한 representation을 만드는 것.
- Masked Decoder Self-Attention : Decoder에서는 각 출력 단어가 모든 출력 단어를 참고하지 않고, 앞쪽의 출력 단어만 참고하도록 만든다.
- Encoder-Decoder Attention : Query가 Decoder에 있고, Key와 Value는 Encoder에 있는 상황을 의미한다.
Self-Attention
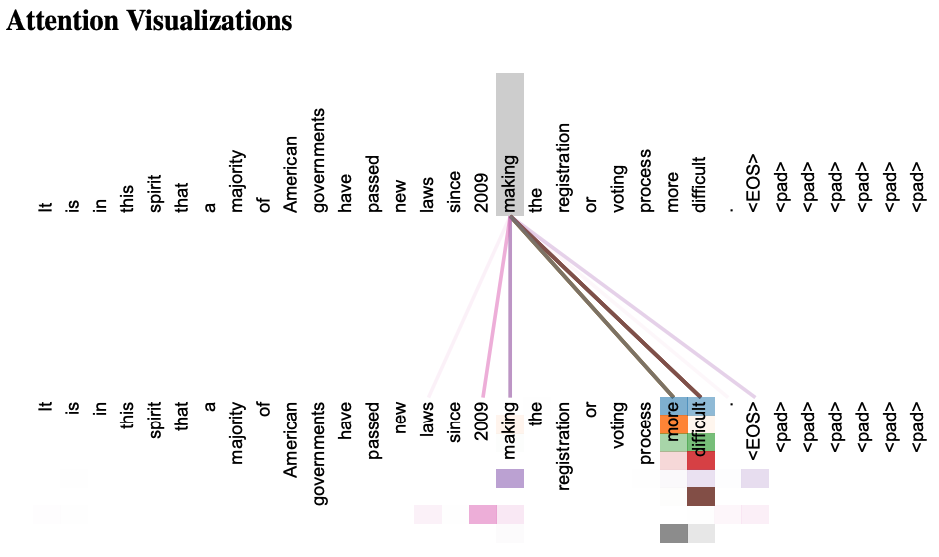
- Encoder, Decoder에서 모두 사용됨.
- 매번 입력 문장에서 각 단어가 다른 어떤 단어와 연관성이 높은 지 계산할 수 있다.
- Attention score를 시각화하여 나타낼 수 있다.

한양대학교 인공지능학과 대학원생 조권휘입니다.