자세한 내용은 논문을 참고하세요.
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE : https://arxiv.org/abs/2010.11929
연구실 내에서 세미나를 진행하며 준비한 자료를 바탕으로 정리하는 글입니다. 궁금한 점이나 문제가 있는 부분은 댓글로 작성해주세요!
1. Introduction
- NLP 영역에서 Transformer 모델이 고안된 이후 많은 발전이 있었지만, computer vision 분야에서는 아직 CNN이 우수한 성능을 보이고 있었고, 발전된 모델의 경우 RNN정도가 있음.
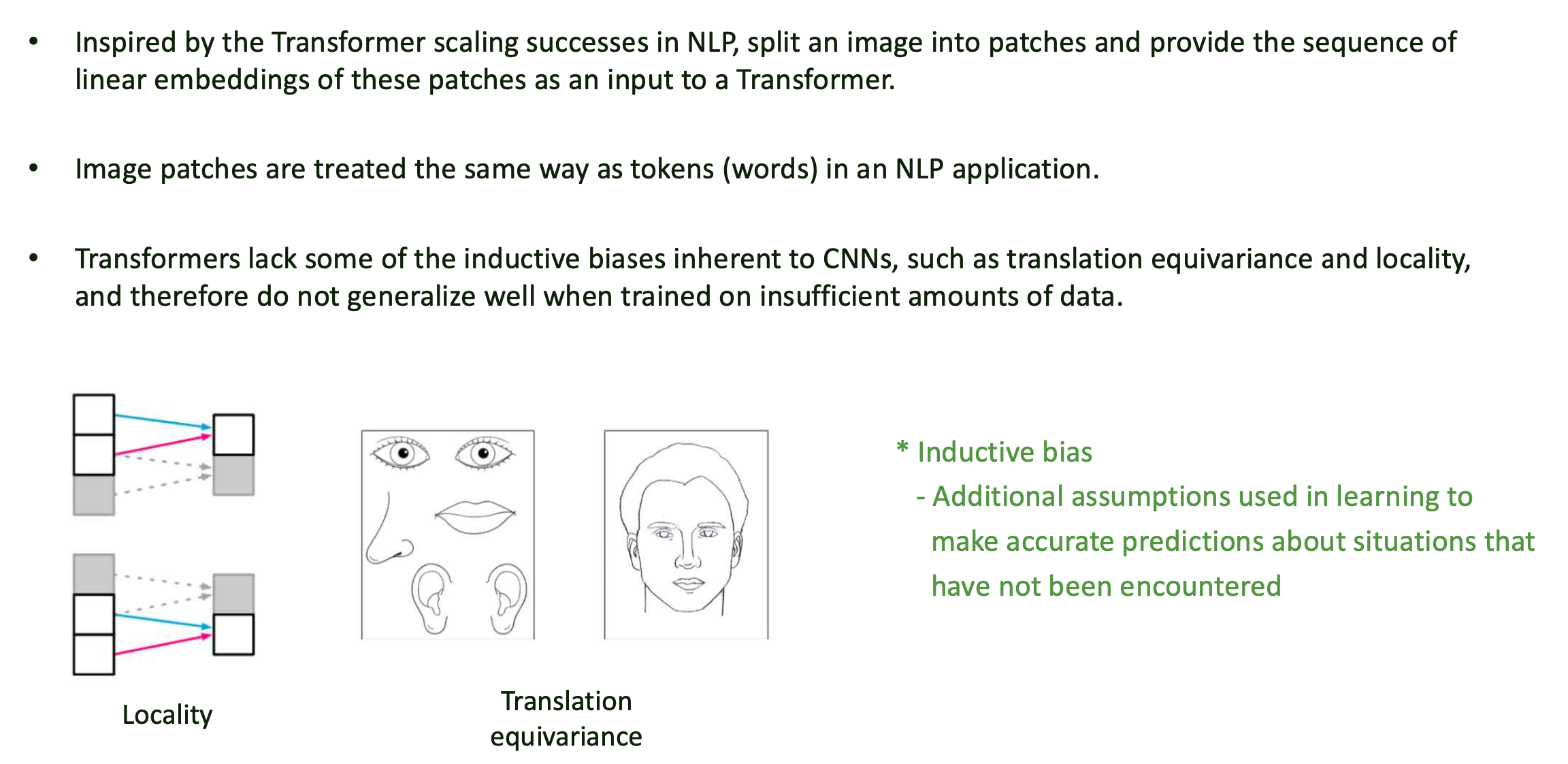
- NLP의 Transformer에 영감을 받아, image를 patch 단위로 나눈 뒤 patch들에 대해 linear embedding sequence 형태로 Transformer에 input으로 넣는 방식을 고안.
- image patch는 NLP의 token(word)을 처리하는 방식과 동일하게 처리됨.
- Transformer는 CNN에 비해 locality, equivariance와 같은 inductive bias가 적기 때문에
충분한 양의 data가 존재하지 않다면 generalize 되기 어려움.
Inductive bias
- training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합
2. Method
-
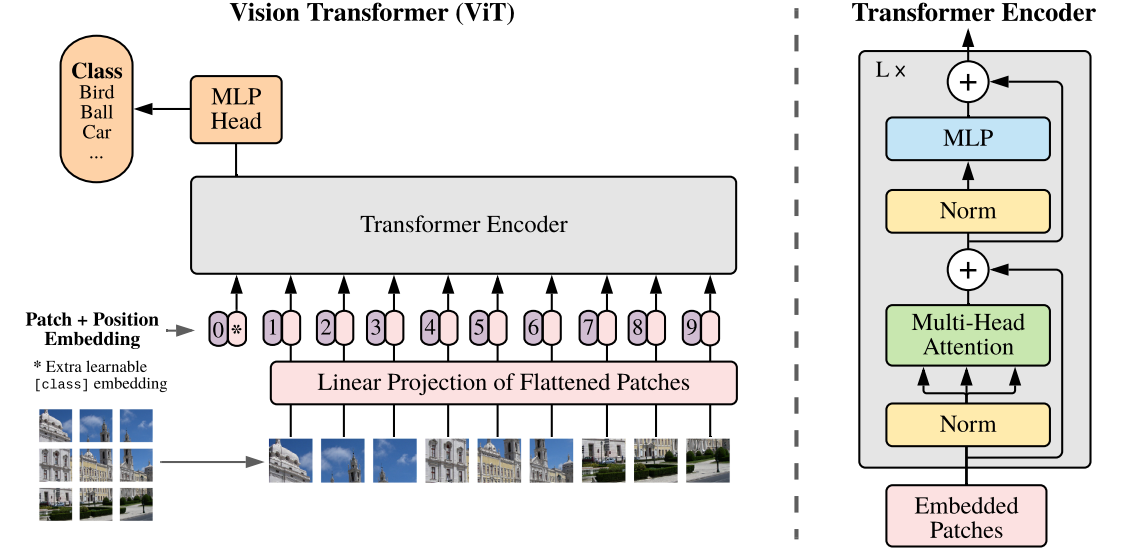
기본적으로 Transformer의 Encoder 구조와 거의 유사함.
-
크게 보면 아래의 4개의 step을 따르게 됨.
- step 1) patch embedding을 구축
- step 2) learnable class embedding, patch embedding에 learnable embedding을 더하기
- step 3) Transformer encoder에 input으로 넣어서 마지막 layer에서 class embedding에 대한 output인 image representation을 도출
- step 4) MLP를 통해 image class를 분류
Step 1
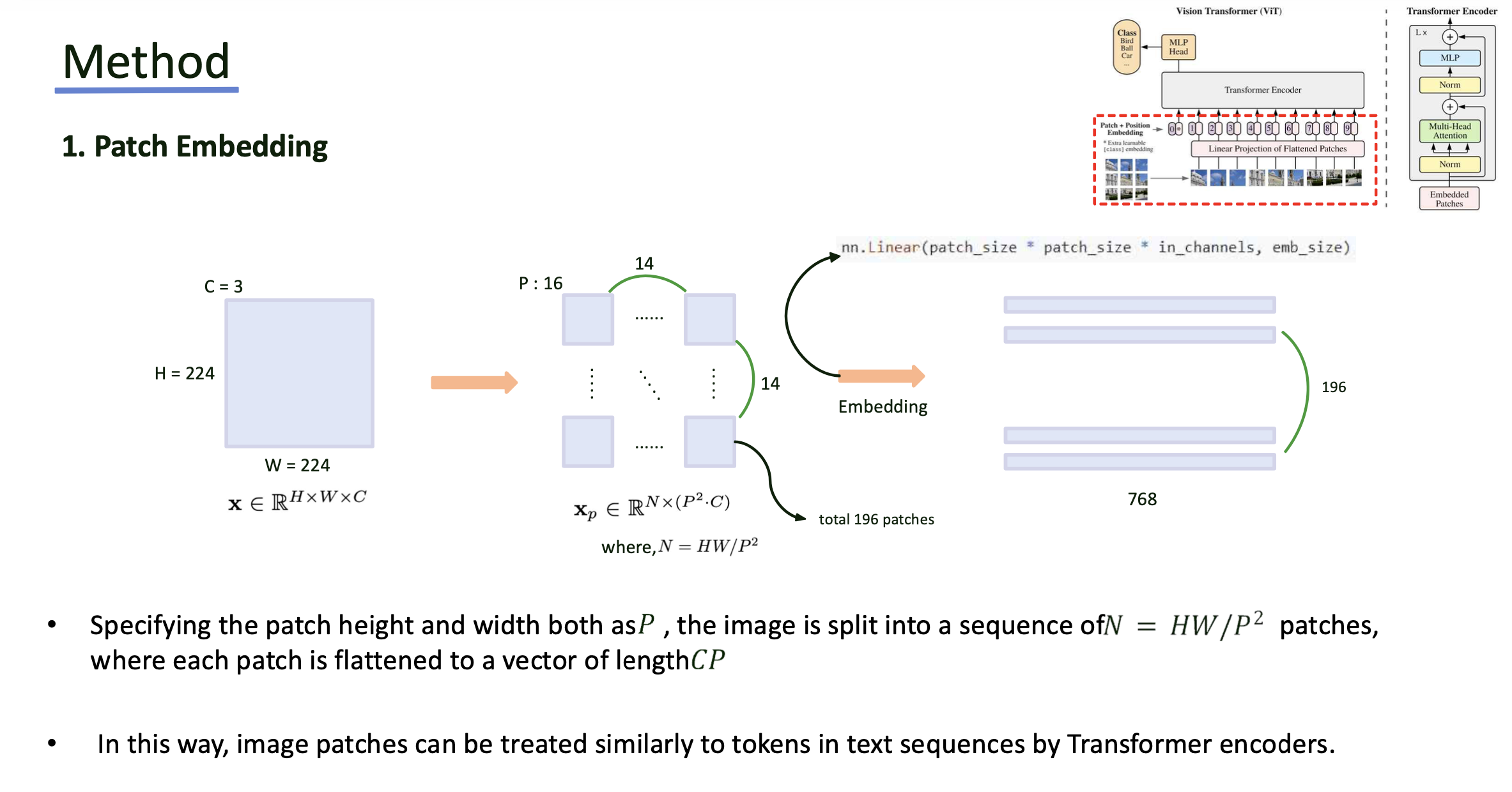
- Input image는 크기의 패치로 나누어 총 개의 patch를 생성
- 각 patch는 flatten하여 의 벡터로 변한한 뒤, linear projection을 통해 embedding을 진행. 이 때 dimension은 768차원으로 변환.
- 이렇게 얻은 embedding patch는 transformer encoder의 input sequence로 처리됨.
Step 2
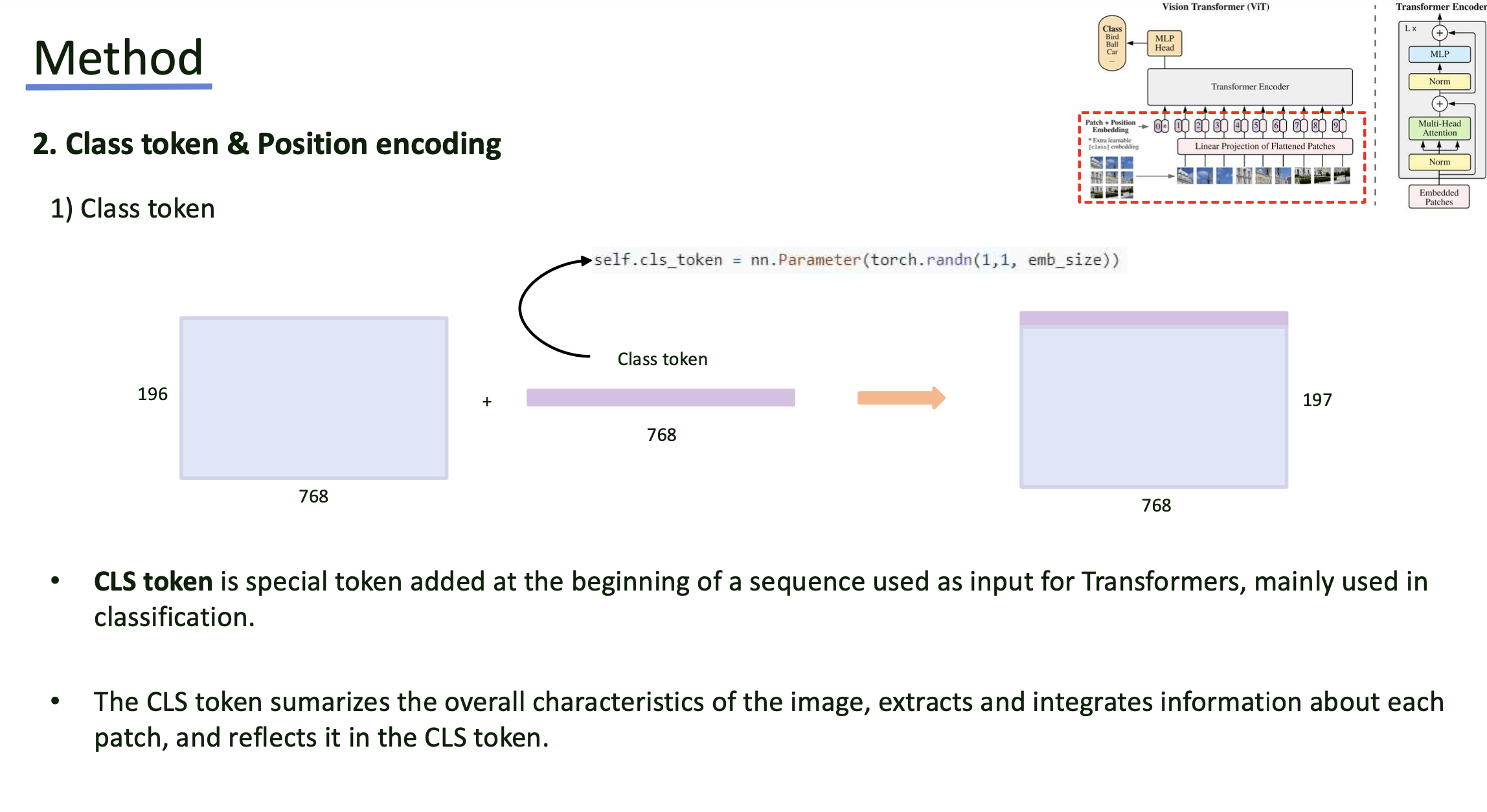
- step 1에서 만든 sequence의 제일 앞에 [CLS] 토큰을 추가.
- [CLS] 토큰은 model을 거치며 전체 이미지를 요약하도록 학습됨.
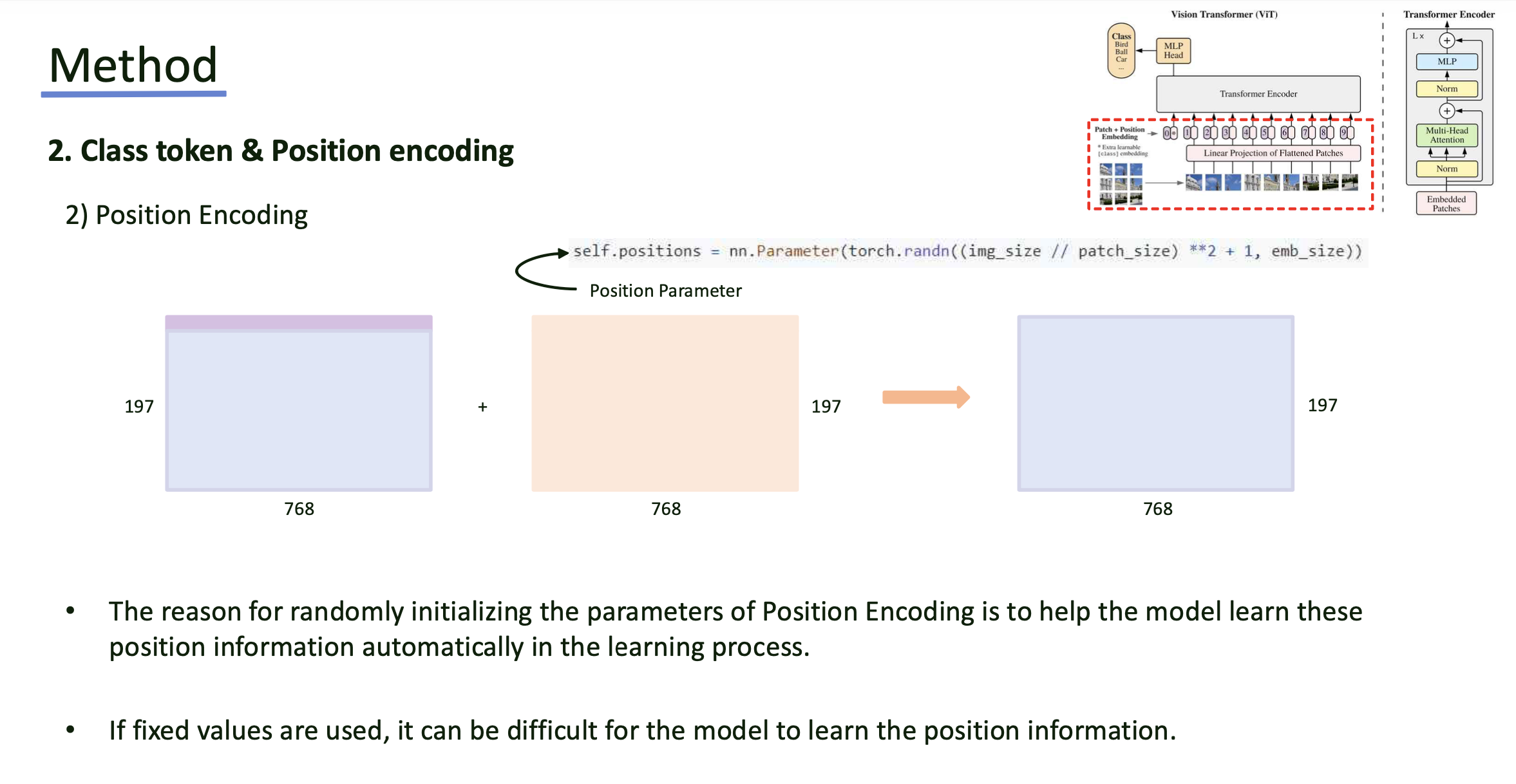
- Position encoding은 patch의 위치 정보를 보존하기 위해 각 토큰에 더해짐.
- embedding은 learnable parameter로 초기화되며, image에서의 공간적 관계를 학습할 수 있도록 함.
Step 3
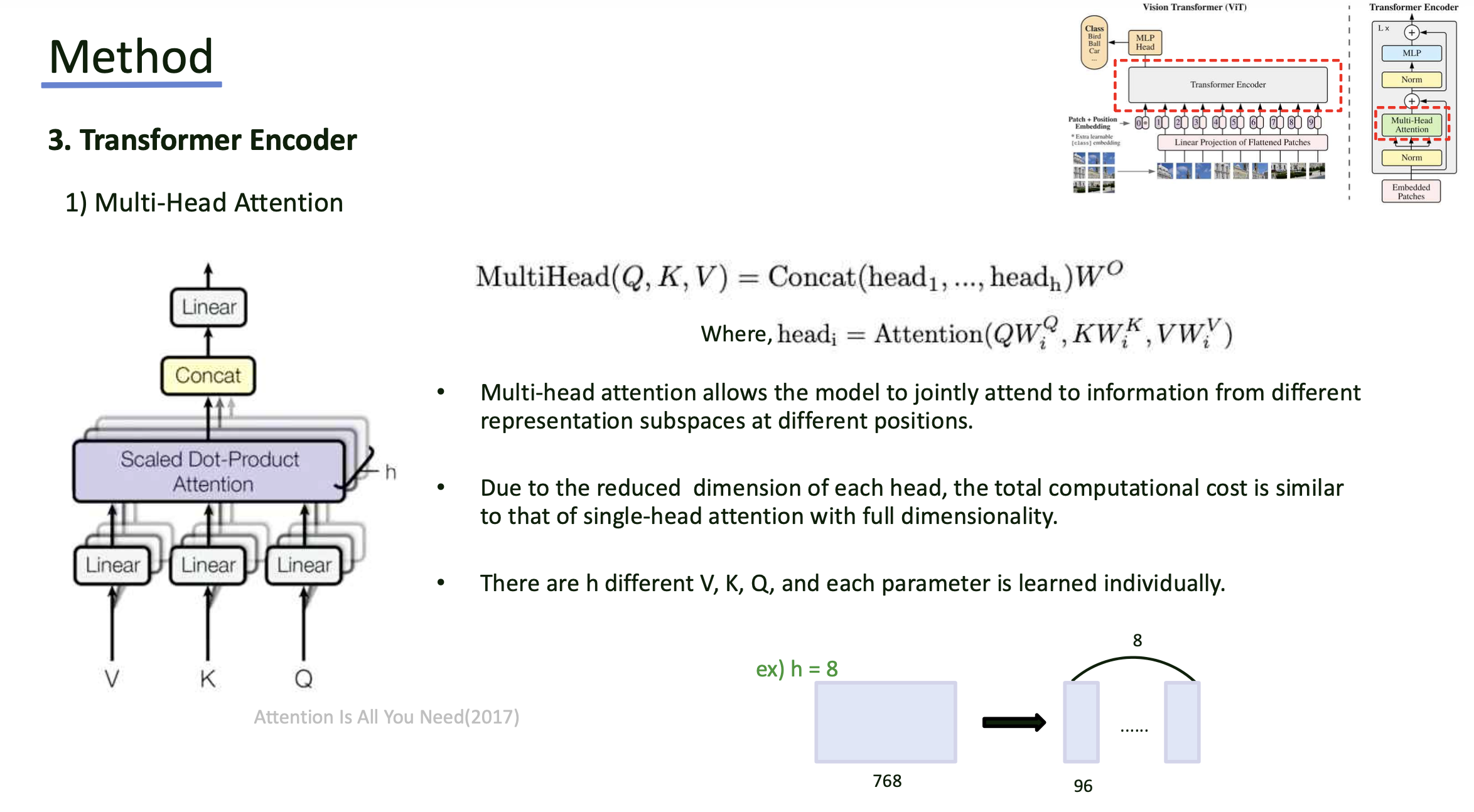
- Transformer의 Multi-Head Attention을 적용하게 됨.
- Sequence에 대해서 Query, Key, Value를 생성하게 되며, Head별로 나누어 Attention 연산을 적용.
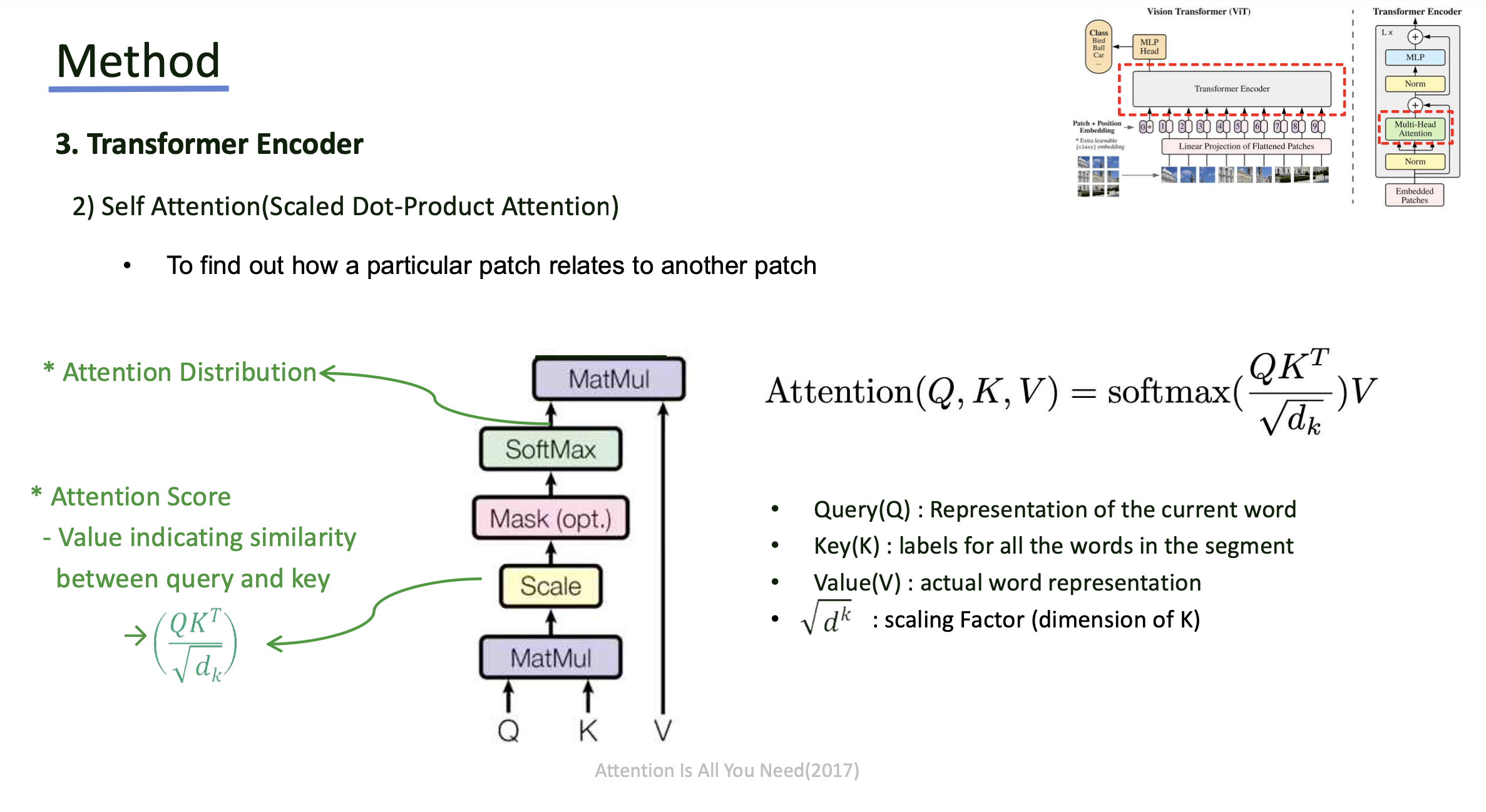
- Self-attention 연산 또한 Transformer와 동일하며, 이 후 MLP layer를 거치는 것도 동일함.
Step 4
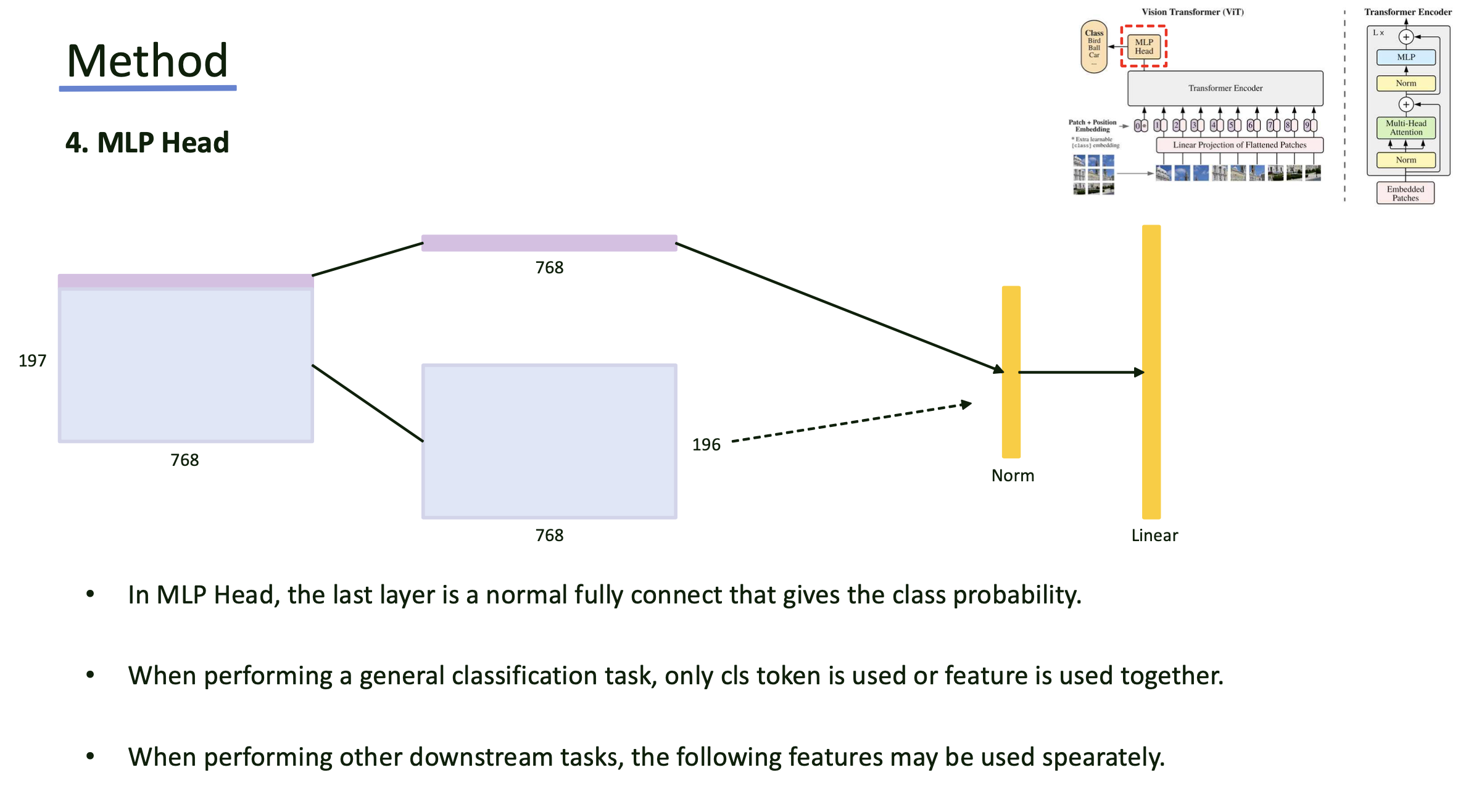
- Encoder를 거친 뒤 나온 feature vector에서 제일 앞에 붙였던 [CLS] 토큰에 대해 normalization, MLP layer를 거쳐 classification을 진행할 수 있음.
- task, pre-training 등 여러 상황에 따라 feature vector를 사용하기도 함.

한양대학교 인공지능학과 대학원생 조권휘입니다.