자세한 내용은 논문을 참고하세요.
PANDA: Adapting Pretrained Features for Anomaly Detection and Segmentation :
https://openaccess.thecvf.com/content/CVPR2021/papers/Reiss_PANDA_Adapting_Pretrained_Features_for_Anomaly_Detection_and_Segmentation_CVPR_2021_paper.pdf
연구실 내에서 세미나를 진행하며 준비한 자료를 바탕으로 정리하는 글입니다. 궁금한 점이나 문제가 있는 부분은 댓글로 작성해주세요!
0. Background
-
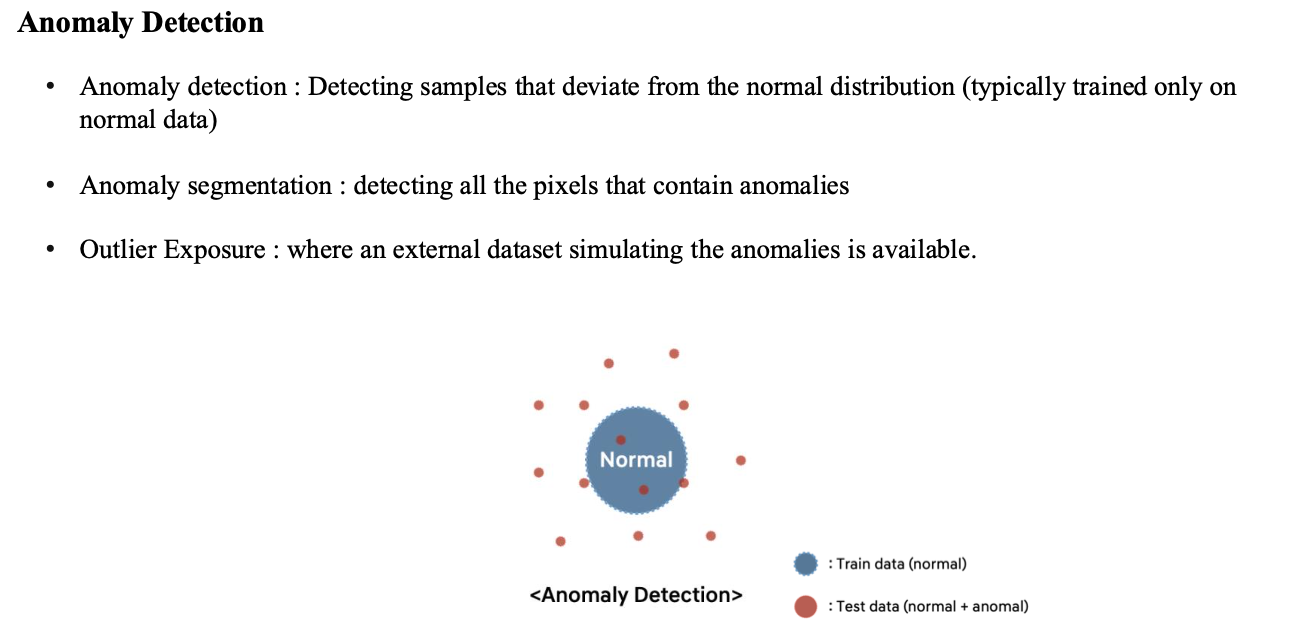
Anomaly detection이란 Normal data만을 이용하여 학습을 진행, normal data의 distribution을 학습한 뒤 abnormal data가 test가 들어왔을 때 distribution 밖의 범위에 표현되도록 함.
-
Anomaly segmentation은 동일하게 normal data만 학습을 진행하는데, 이미지의 모든 pixel에 대해 abnormality를 판단하는 task
-
Outlier exposure는 train에서 abnormal data를 어느정도 사용할 수 있는 경우를 의미, train 과정에서 abnormal data의 distribution도 학습할 수 있는 상황을 의미함.
Normal data를 어떻게 정의할까?
- 완벽한 Normal data를 확실하게 정의하는 것은 힘들어서 일반적으로 표현을 Normal control / Healthy control로 표현을 함. 또한 task별로 해당 task 관점에서의 문제가 있는 데이터를 abnormal로 정의하는 것으로 확인됨.
1. Introduction
-
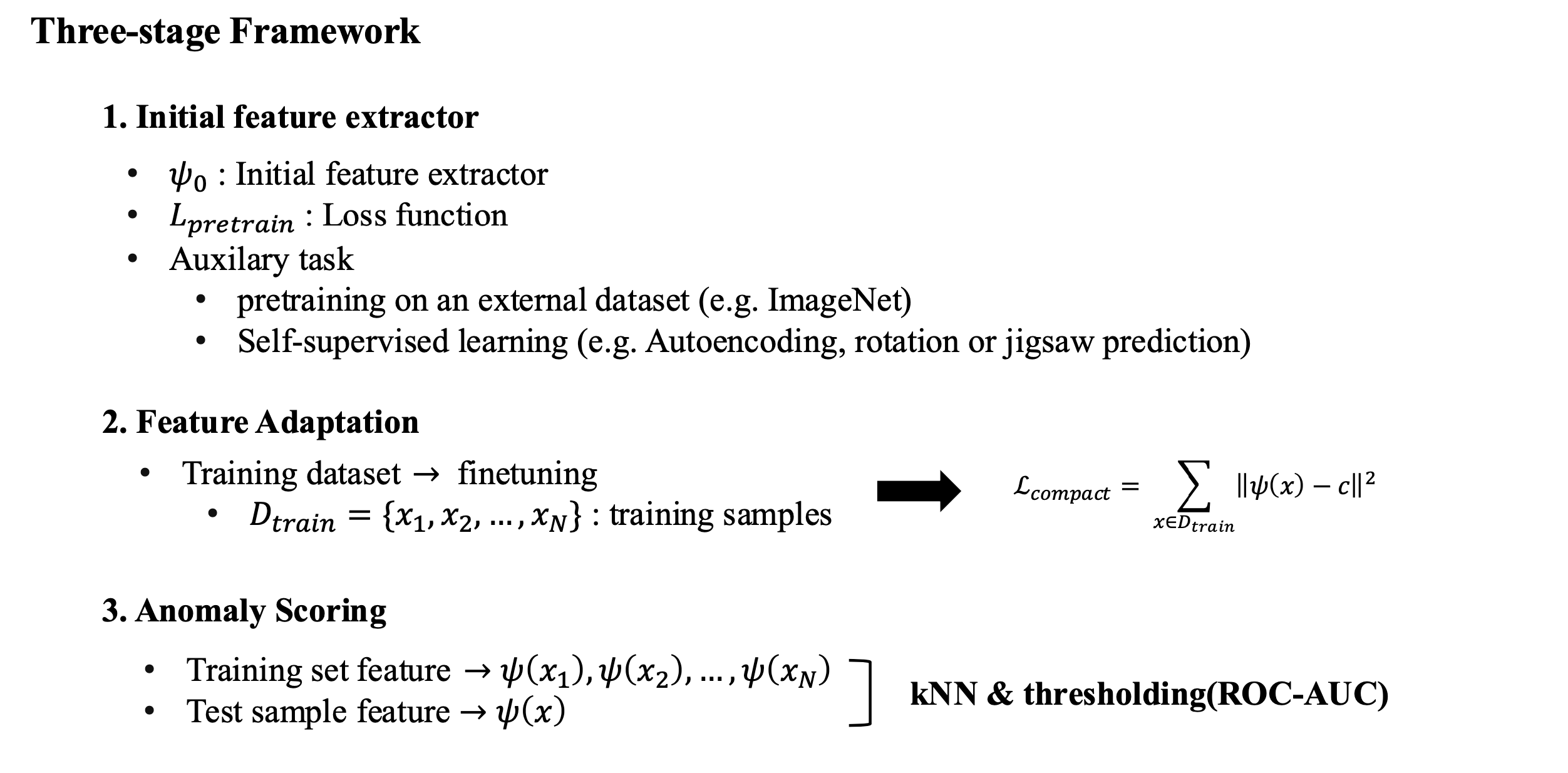
일반적으로 anomaly detection은 3단계로 진행을 함.
-
첫 번째로 초기 feature extractor를 학습. feature를 추출하는 방식에는 크게 2가지가 존재
- 외부 데이터로 pre-training : ImageNet과 같은 많은 양의 data를 통해 feature를 추출하는 능력을 학습
- Self-supervised learning : 외부 데이터가 아닌 보유하고 있는 데이터를 이용하여 학습, Autoencoder와 같이 reconstruction을 통해 학습을 하거나 특정 task를 통해 label이 없는 상황에서도 feature를 잘 추출하도록 학습
-
두 번째로 사전학습한 encoder를 현재 data로 fine-tuning 진행. 를 이용하여 학습함. 데이터셋 의 중심 로 수렴을 할 수 있도록 하여 데이터 분포를 한 점에 가깝게 모으도록 진행함.
-
마지막으로 test sample data의 feature과 traning sample feature들에 대해 knn을 통해 top-k개의 거리를 구하고, 이를 anomaly score로 사용함. 이 후 ROC-curve를 그리고 ROC-AUC를 계산

-
One-class classification task에서 앞서 설명한 방식(data 중심 로 모이도록 학습)으로 학습을 하게 되면 모든 train data가 fine-tuning 단계에서 feature를 잘 표현하는 능력을 잃으며 중심 c, 즉 한 점으로 모이게 되어 성능이 급격히 안 좋아지게 됨.
-
한 점으로 data distribution을 모으게 된다면 test 단계에서 normal data가 들어와도 abnormal이라고 대답할 확률이 매우 높아지게 됨.
-
이러한 문제를 Catastrophic collapse라고 함.
2. Method
(1) PANDA-Early
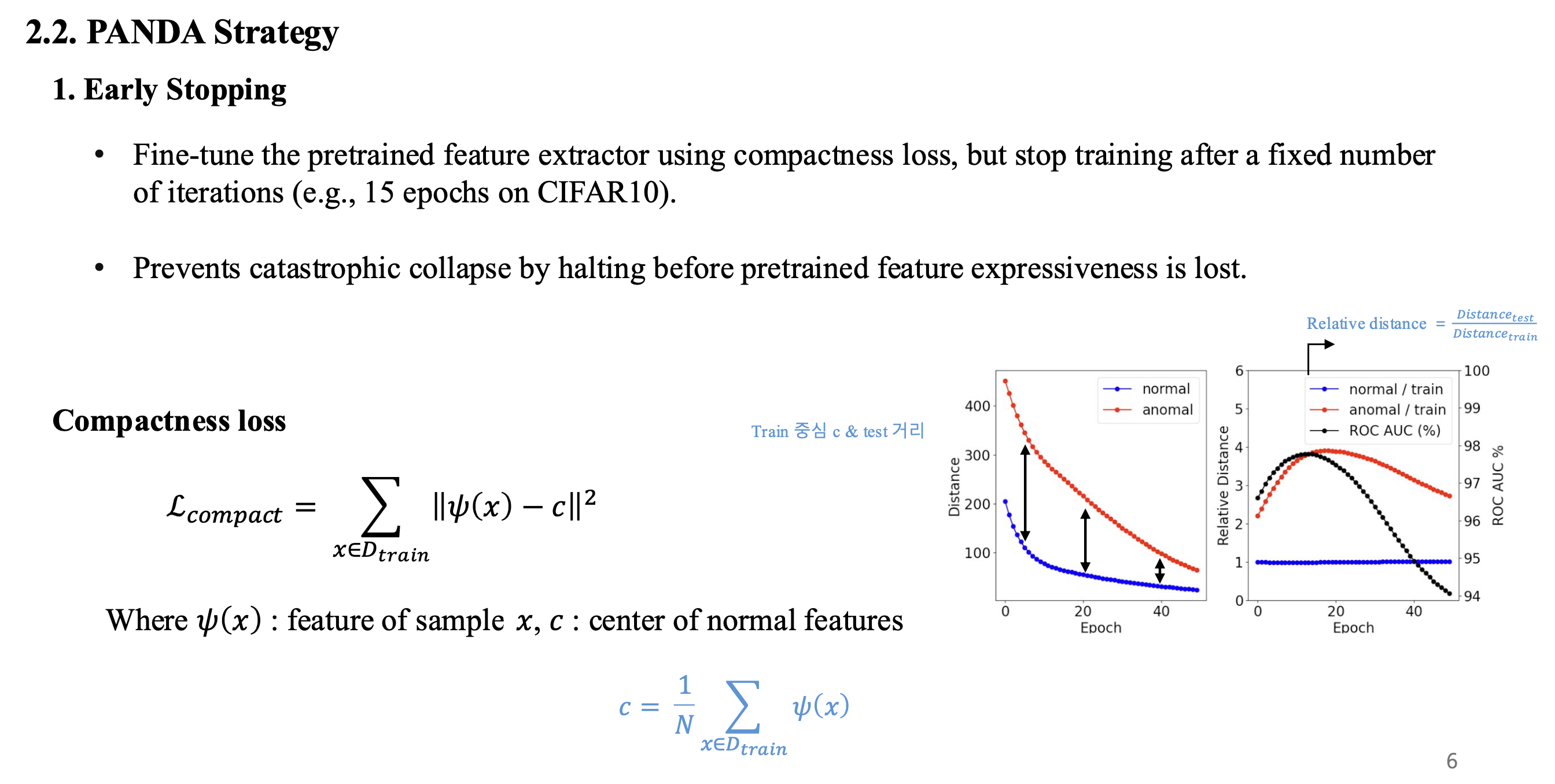
- Catastrophic collapse가 발생하기 전에 학습을 멈추는 방식으로, test data를 통해 ROC AUC가 떨어지는 부분을 확인하여 모델의 epoch를 결정함
- data별로 다르게 확인을 하며, 예시로 논문에서는 CIFAR10 데이터에서는 15 epoch이 최적이라고 하였음.
(2) PANDA-SES
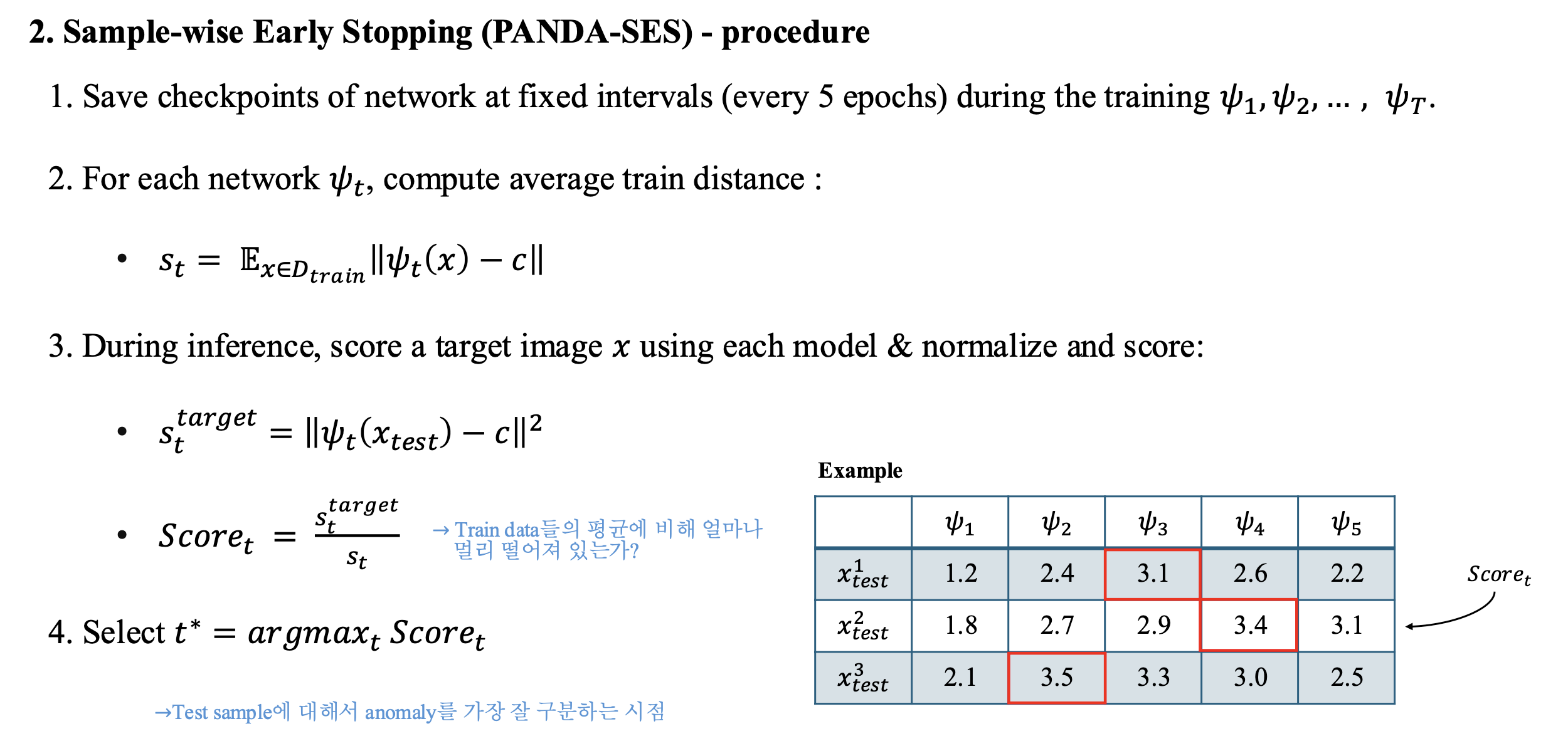
- 전체 dataset에 대해서 하나의 epoch를 정하는 것이 아니라 각 test sample에 대해 최적의 모델을 선정해주는 방식
- 학습 단계에서 정해준 일정 epoch(논문에서는 5)마다 weight(pt 파일)를 저장
- 학습이 끝난 뒤 모든 train data에 대해 저장한 weight를 기준으로 중심 c와 거리를 계산()
- Inference 단계에서 각 test sample()들과 c 사이의 거리()를 계산하고 로 나누어 상대적 거리를 계산
- 구한 거리들을 기준으로 가장 큰 시점의 model을 각 sample별로 선정하는 방식
- 1, 2번 방식은 엄연히 따지면 cheating에 가까운 생각이 들긴 하지만..일반적인 상황이 아닌(one-class classification) 부분을 고려하면 납득이..그래도 안 되긴 합니다..
(3) PANDA-EWC

- Fisher information matrix를 이용하여 pre-training 단계에서의 중요하게 생각한 feature를 바꿀 때는 패널티를 주는 방식
- fine-tuning 단계에서 parameter 수치가 많이 바뀌는 것은 pre-training 단계에서도 많이 바뀌었을 것이고, 이는 데이터마다 민감하게 반응하며 중요한 feature라는 생각을 가지고, 최대한 pre-training 단계의 feature를 유지하게 함.
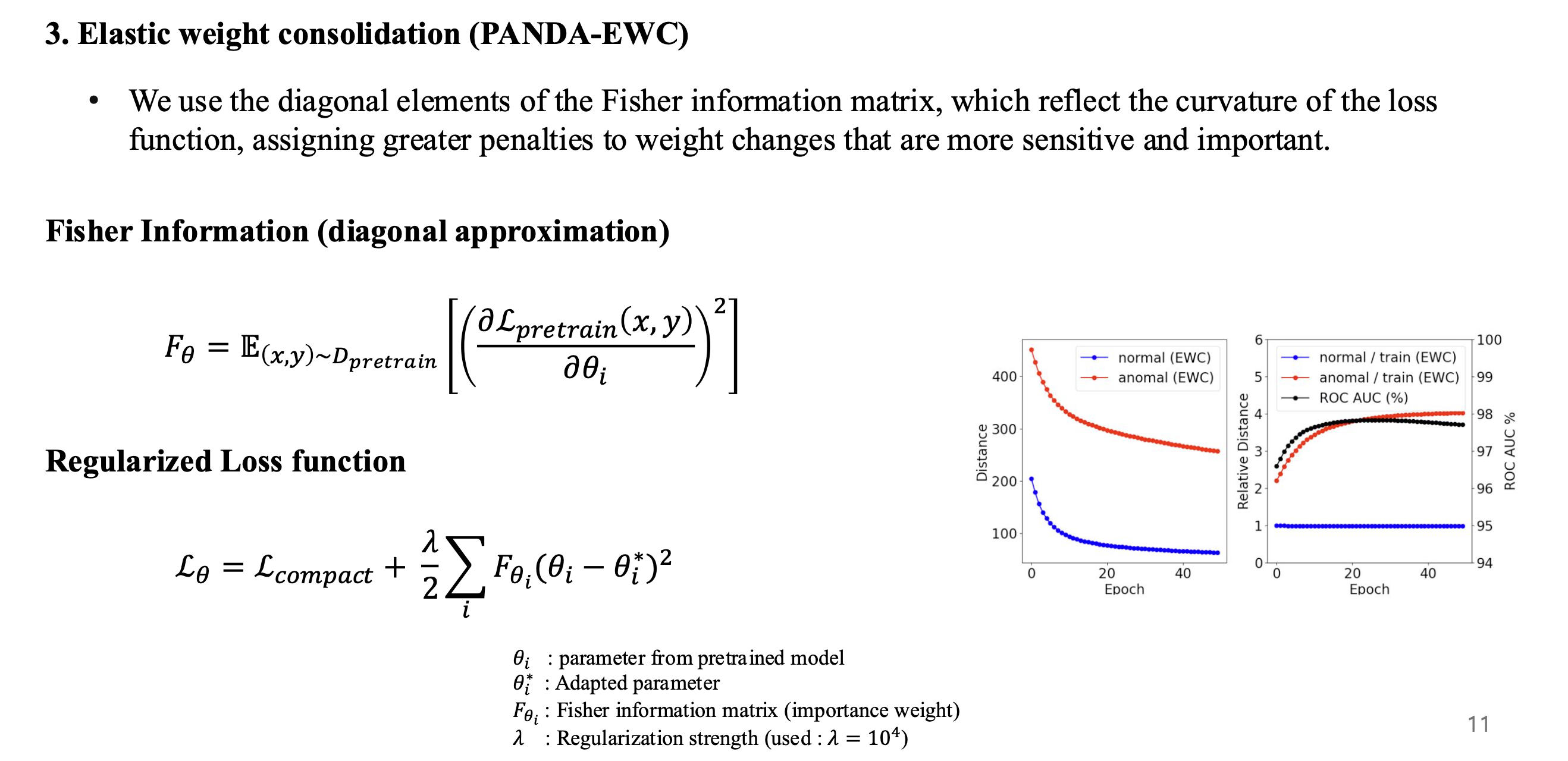
(3.a) Fisher matrix
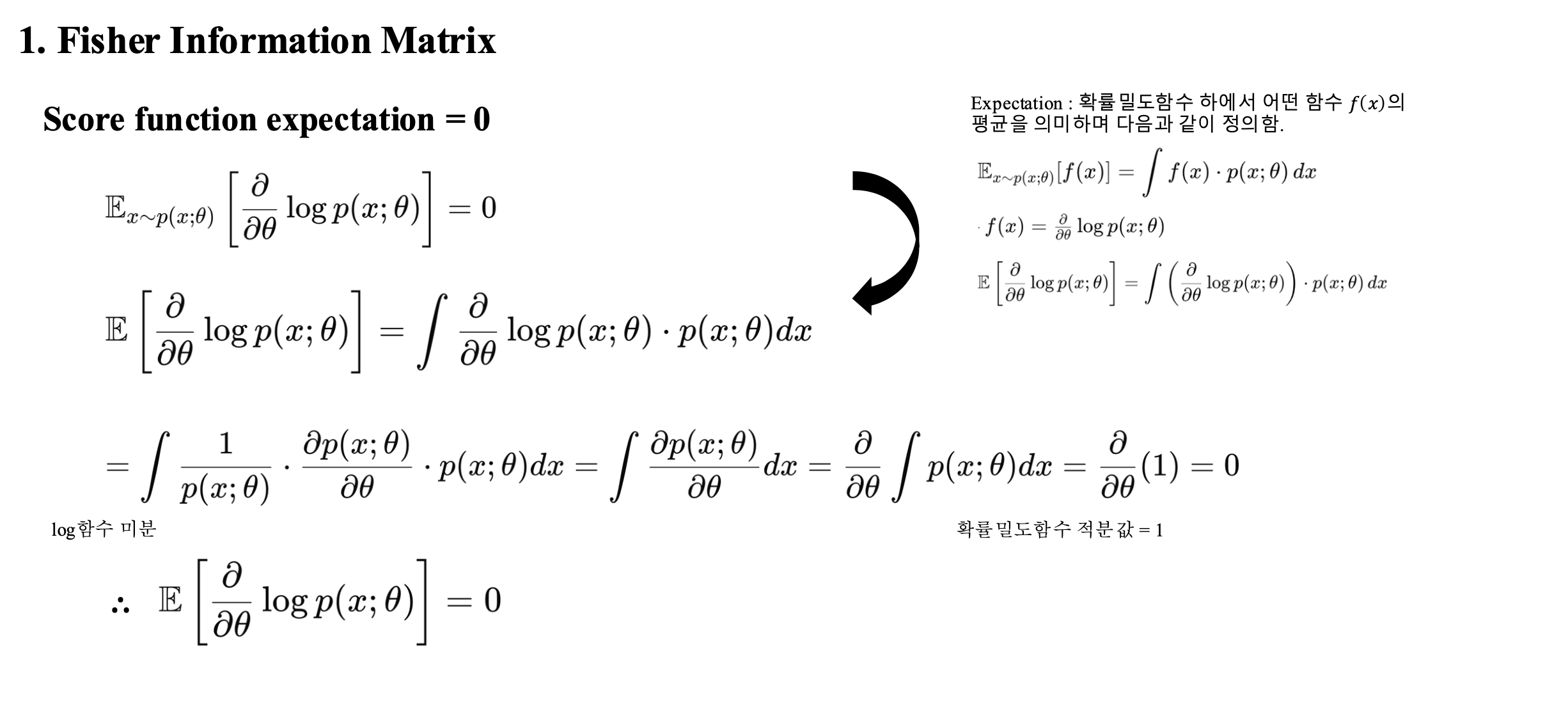
- Fisher information matrix에 대해 추가적인 설명을 적은 appendix 페이지를 만들었어서 함께 첨부함
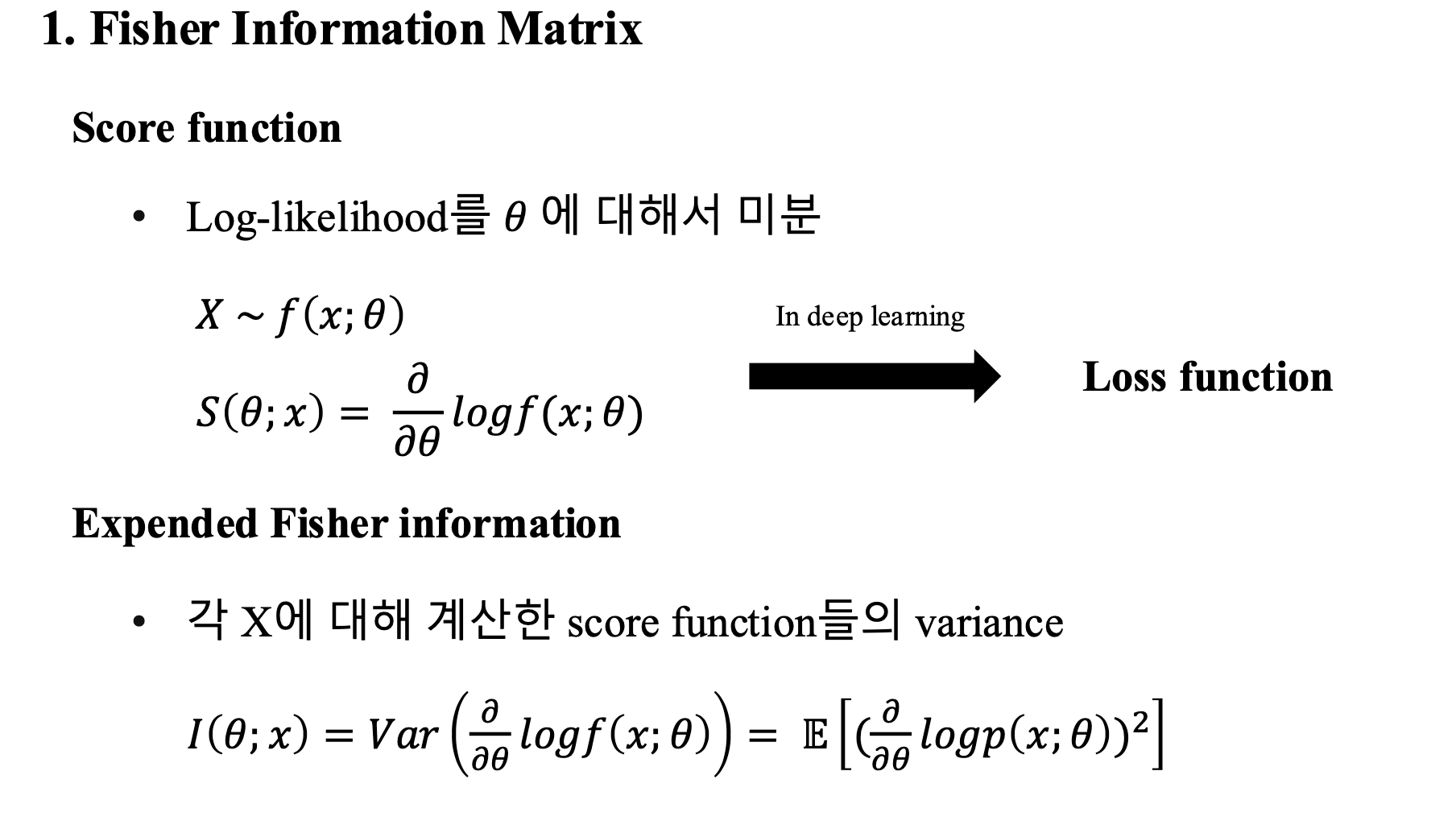
- 왜 Fisher information matrix가 저런 형태인지 증명을 하는 과정 (참고 용도)
3. Baseline
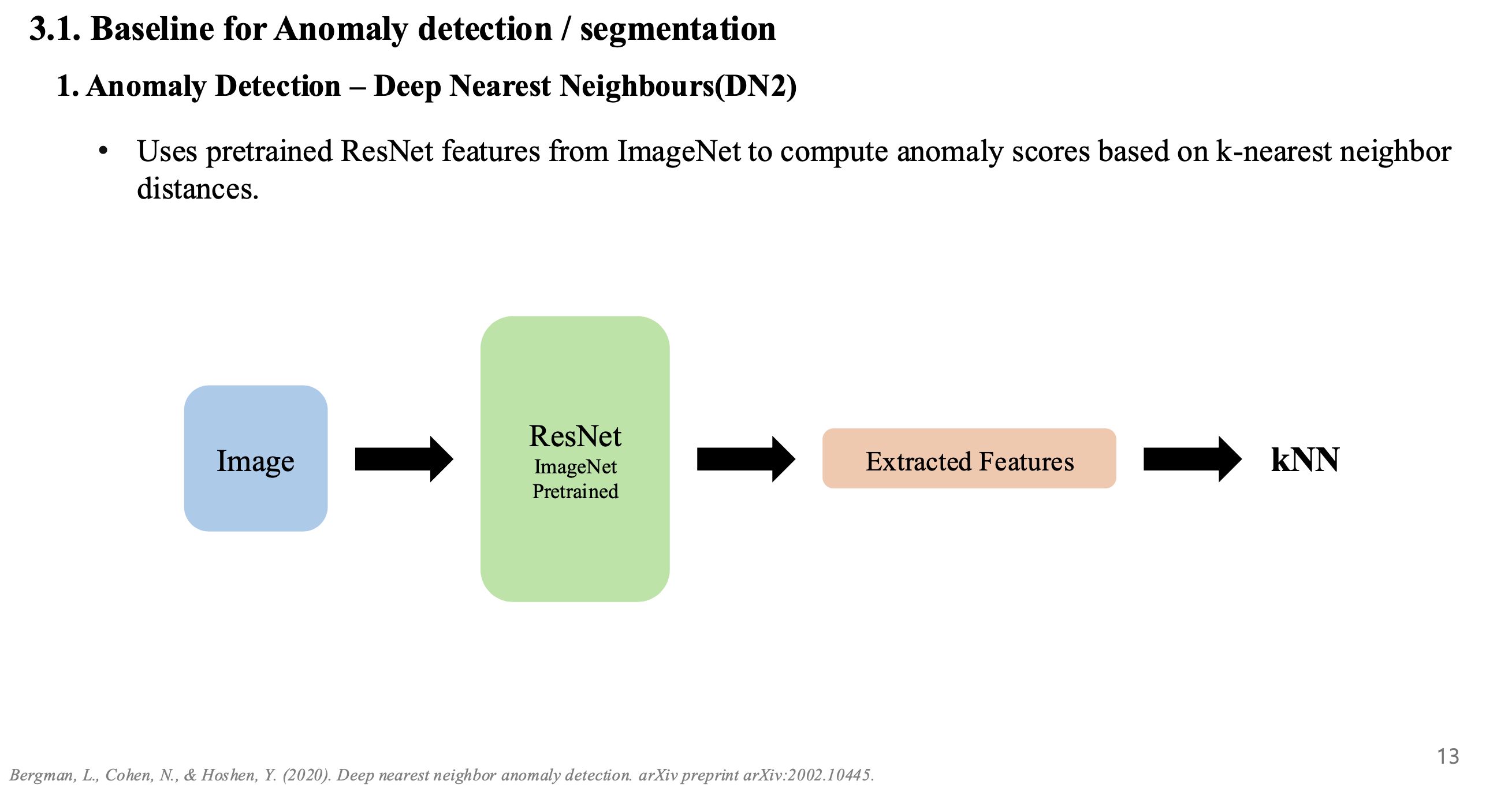
- Anomaly detection에는 DN2 모델을 사용함
- 해당 모델은 외부 데이터셋으로 pre-train을 한 ResNet이며, 최종적으로는 kNN을 이용하여 anomaly scoring을 진행.
- DN2 모델에 PANDA의 3가지 기법을 적용하여 classification을 진행함.
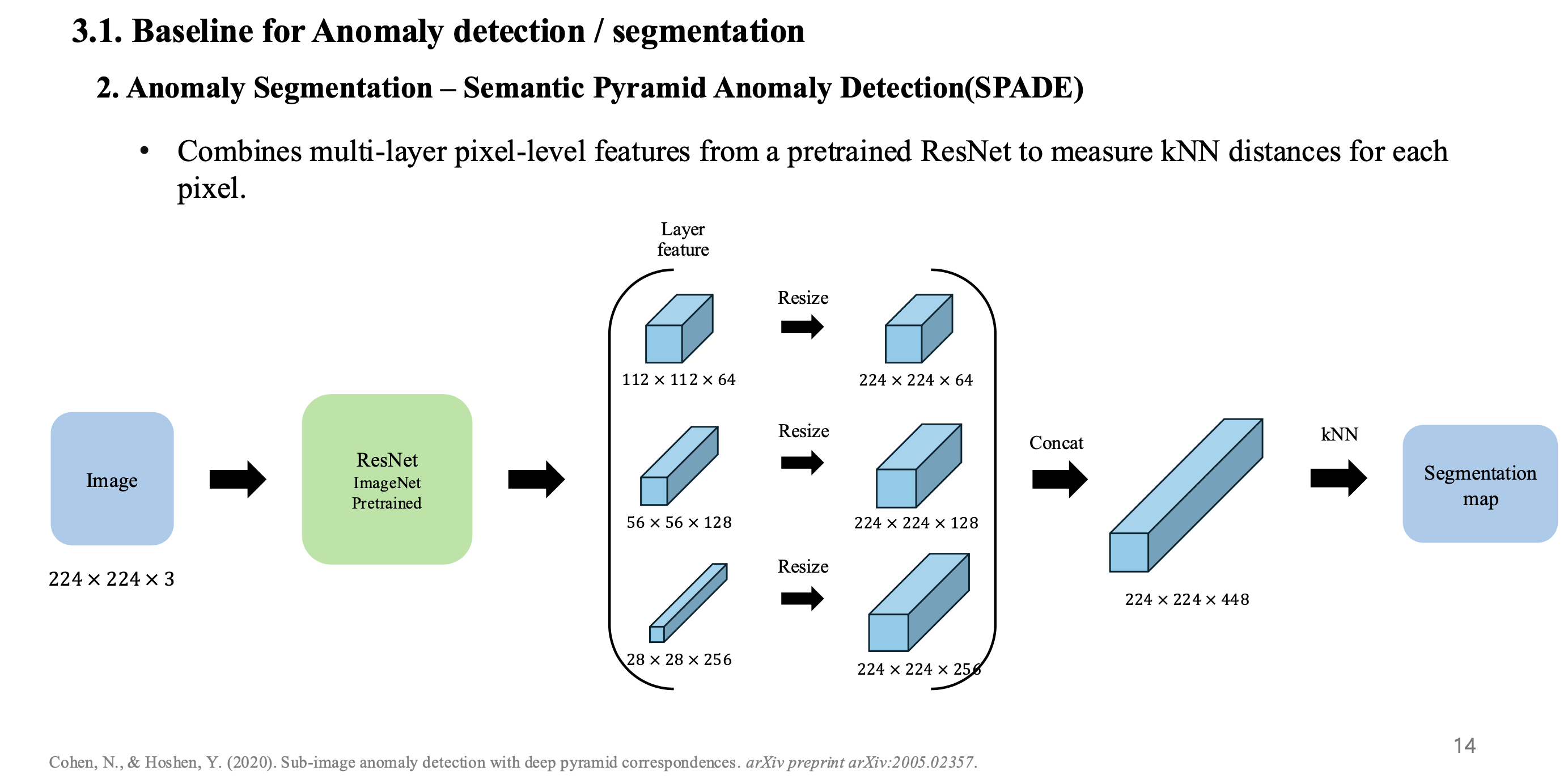
- Anomaly Segmentation에는 SPADE 모델을 사용함.
- DN2와 동일하게 pre-trained ResNet을 사용하여 feature를 추출한 뒤, 각 layer에서 추출된 feature를 resize를 통해 image size로 변경
- feature들을 concat하여 모든 pixel 단위마다 anomaly scoring을 하며 classification을 하게 됨.
4. Dataset
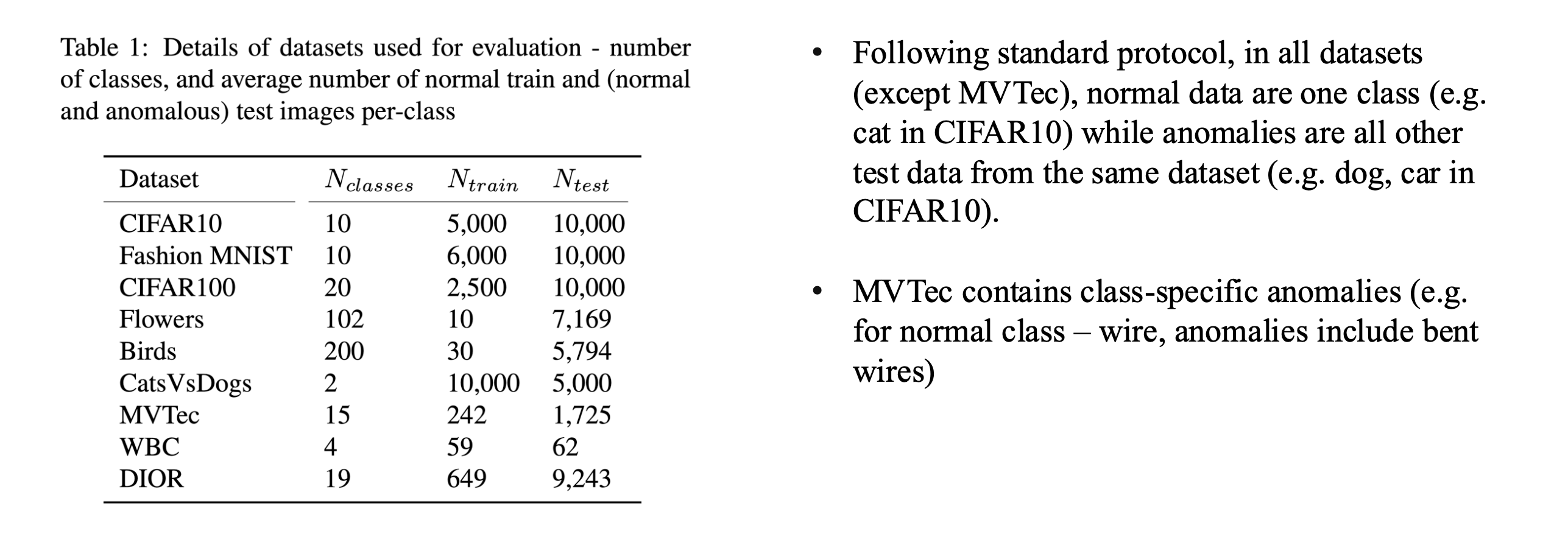
- Dataset을 사용할 때 MVTec을 제외한 나머지 dataset은 하나의 class를 normal, 이 외의 class들은 abnormal data라고 가정하여 실험을 진행.
- 예시로 강아지 사진을 normal이라고 했으면, dataset에 있는 다른 class들(고양이, 사자, 사슴..)은 전부 abnormal data
- MVTec의 경우 정상/비정상 데이터가 구분되어 구성되어 있음.
