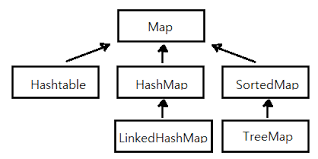
Map인터페이스
Map인터페이스에 대해 특징을 얘기하자면 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로 저장한다는 특징을 갖는다.
HashMap
HashMap은 Map과 마찬가지로 키(key)와 값(value)으로 이루어진 형태로 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
그리고 키와 값을 각각 Object타입으로 저장한다. 즉(Object, Object)의 형태로 저장하기 때문에 어떠한 객체도 저장할 수 있지만 키는 주로 String을 대문자 또는 소문자로 통일해서 사용하곤 한다.
키(key) 컬렉션 내의 키(key) 중에서 유일해야 한다.
값(value) 키(key)와 달리 데이터의 중복을 허용한다.
키는 저장된 값을 찾는데 사용되는 것이기 때문에 컬렉션 내에서 유일(unique)헤야 한다. 만일 하나의 키에 대해 여러 검색결과 값을 얻는다면 원하는 값이 어떤 것인지 알 수 없기 때문이다.
예제1
import java.util.*;
public class HashMapEx1 {
public static void main(String[] args){
HashMap map = new HashMap<>();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
Scanner s = new Scanner(System.in); // 화면으로부터 라인단위로 입력받는다.
while(true){
System.out.println("id와 password를 입력해주세요.");
System.out.print("id : ");
String id = s.nextLine().trim();
System.out.print("password : ");
String password = s.nextLine().trim();
System.out.println();
if(!map.containsKey(id)){
System.out.println("입력하신 id는 존재하지 않습니다." + " 다시 입력해주세요.");
continue;
} else {
if(!(map.get(id).equals(password))){
System.out.println("비밀번호가 일치하지 않습니다. 다시 입력해주세요.");
} else {
System.out.println("id와 password가 일치합니다.");
break;
}
}
} // while
} // main의 끝
}
결과
id와 password를 입력해주세요.
id : asdf
password : 1111
비밀번호가 일치하지 않습니다. 다시 입력해주세요.
id와 password를 입력해주세요.
id : asdf
password : 1234
id와 password가 일치합니다.HashMap을 생성하고 사용자 ID와 비밀번호를 키와 값의 쌍(pair)으로 저장한 다음 입력된 사용자 ID를 키로 HashMap에서 검색해서 얻은 값(비밀번호)을 입력된 비밀번호와 비교하는 예제이다.
HashMap map = new HashMap<>();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");위의 코드는 HashMap을 생성하고 데이터를 저장하는 부분인데 이 코드가 실행되고 나면 HashMap에는 아래와 같은 형태로 데이터가 저장된다.
| 키(key) | 값(value) |
|---|---|
| myId | 1234 |
| asdf | 1234 |
3개의 데이터 쌍을 저장했지만 실제로는 2개 밖에 저장되지 않는 이유는 중복된 키가 있기 때문이다. 세 번째로 저장한 데이터의 키인 'asdf'는 이미 존재하기 때문에 새로 추가되는 대신 기존의 값을 덮어썼다. 그래서 키 'asdf'에 연결된 값은 '1234'가 된다.
Map은 값은 중복을 허용하지만 키는 중복을 허용하지 않기 때문에 저장하려는 두 데이터 중에서 어느 쪽을 키로 할 것인지를 잘 결정해야한다.
예제2
import java.util.*;
public class HashMapEx2 {
public static void main(String[] args){
HashMap map = new HashMap<>();
map.put("김자바", new Integer(100));
map.put("이자바", new Integer(100));
map.put("강자바", new Integer(80));
map.put("안자바", new Integer(90));
Set set = map.entrySet();
Iterator it = set.iterator();
while(it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
System.out.println("이름 : " + e.getKey() + ", 점수 : " + e.getValue());
}
set = map.keySet();
System.out.println("참가자 명단 : " + set);
Collection values = map.values();
it = values.iterator();
int total = 0;
while(it.hasNext()){
Integer i = (Integer)it.next();
total += i.intValue();
}
System.out.println("총점 : " + total);
System.out.println("평균 : " + (float)total/set.size());
System.out.println("최고점수 : " + Collections.max(values));
System.out.println("최저점수 : " + Collections.min(values));
}
}
결과
이름 : 안자바, 점수 : 90
이름 : 김자바, 점수 : 100
이름 : 강자바, 점수 : 80
이름 : 이자바, 점수 : 100
참가자 명단 : [안자바, 김자바, 강자바, 이자바]
총점 : 370
평균 : 92.5
최고점수 : 100
최저점수 : 80HashMap의 기본적인 메서드를 이용해서 데이터를 저장하고 읽어오는 예제이다. entrySet()을 이용해서 키와 값을 함께 읽어 올 수도 있고 keySet()이나 values()를 이용해서 키와 값을 따로 읽어 올 수 있다.
예제3
import java.util.*;
public class HashMapEx3 {
static HashMap phoneBook = new HashMap<>();
public static void main(String[] args){
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("회사", "이과장", "010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
} // main
// 그룹에 전화번호를 추가하는 메서드
static void addPhoneNo(String groupName, String name, String tel){
addGroup(groupName);
HashMap group = (HashMap)phoneBook.get(groupName);
group.put(tel, name); // 이름은 중복될 수 있으니 전화번호를 key로 저장한다.
}
// 그룹을 추가하는 메서드
static void addGroup(String groupName){
if(!phoneBook.containsKey(groupName)){
phoneBook.put(groupName, new HashMap<>());
}
}
static void addPhoneNo(String name, String tel){
addPhoneNo("기타", name, tel);
}
static void printList(){
Set set = phoneBook.entrySet();
Iterator it = set.iterator();
while(it.hasNext()){
Map.Entry e = (Map.Entry)it.next();
Set subSet = ((HashMap)e.getValue()).entrySet();
Iterator subIt = subSet.iterator();
System.out.println(" * " + e.getKey() + " [" + subSet.size() + "]");
while(subIt.hasNext()){
Map.Entry subE = (Map.Entry)subIt.next();
String telNo = (String)subE.getKey();
String name = (String)subE.getValue();
System.out.println(name + " " + telNo);
}
System.out.println();
}
} // printList()
} // class
결과
* 기타 [1]
세탁 010-888-8888
* 친구 [3]
이자바 010-111-1111
김자바 010-222-2222
김자바 010-333-3333
* 회사 [4]
이과장 010-777-7777
김대리 010-444-4444
김대리 010-555-5555
박대리 010-666-6666
HashMap은 데이터를 키와 값을 모두 Object타입으로 저장하기 때문에 HashMap의 값(value)으로 HashMap을 다시 저장할 수 있다. 이렇게 함으로써 하나의 키에 다시 복수의 데이터를 저장할 수 있다.
먼저 전화번호를 저장할 그룹을 만들고 그룹 안에 다시 이름과 전화번호를 저장하도록 했다. 이때 이름대신 전화번호를 키로 사용했다는 것을 확인하자. 이름은 동명이인이 있을 수 있지만 전화번호는 유일하기 때문이다.
예제4
import java.util.*;
public class HashMapEx4 {
public static void main(String[] args){
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D"};
HashMap map = new HashMap<>();
for(int i = 0; i < data.length; i++){
if(map.containsKey(data[i])){
Integer value = (Integer)map.get(data[i]);
map.put(data[i], new Integer(value.intValue() + 1));
} else {
map.put(data[i], new Integer(1));
}
}
Iterator it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
int value = ((Integer)entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
} // main
public static String printBar(char ch, int value){
char[] bar = new char[value];
for(int i = 0; i < bar.length; i++){
bar[i] = ch;
}
return new String(bar); // String(char[] chArr)
}
}
결과
A : ### 3
D : ## 2
Z : # 1
K : ###### 6문자열 배열에 담긴 문자열을 하나씩 읽어서 HashMap에 키로 저장하고 값으로 1을 저장한다. HashMap에 같은 문자열이 키로 저장되어 있는지 containsKey()로 확인하여 이미 저장되어 있는 문자열이면 값을 1증가시킨다.
그리고 그 결과를 printBar()를 이용해서 그래프로 표현했다. 이렇게 하면 문자열 배열에 담긴 문자열들의 빈도수를 구할 수 있다.
한정된 범위 내에 있는 순차적인 값들의 빈도수는 배열을 이용하지만, 이처럼 한정되지 않은 범위의 비순차적인 값들의 빈도수는 HashMap을 이용해서 구할 수 있다.
TreeMap
이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다. 그래서 검색과 정렬에 적합한 컬렉션 클래스이다.
HashMap과 TreeMap의 검색성능에 관해서 대부분 HashMap이 TreeMap보다 더 뛰어나므로 HashMap을 사용하는 것이 좋다. 다만 범위검색이나 정렬이 필요한 경우에는 TreeMap을 사용하는 것이 좋다.
예제1
import java.util.*;
public class TreeMapEx1 {
public static void main(String[] args) {
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D"};
TreeMap map = new TreeMap<>();
for (int i = 0; i < data.length; i++) {
if (map.containsKey(data[i])) {
Integer value = (Integer) map.get(data[i]);
map.put(data[i], new Integer(value.intValue() + 1));
} else {
map.put(data[i], new Integer(1));
}
}
Iterator it = map.entrySet().iterator();
System.out.println("= 기본정렬 =");
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
int value = ((Integer) entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
System.out.println();
// map을 ArrayList로 변환한 다음에 Collections.sort()로 정렬
Set set = map.entrySet();
List list = new ArrayList(set); // ArrayList(Collection c)
// static void sort(List list, Comparator c)
Collections.sort(list, new ValueComparator());
it = list.iterator();
System.out.println("= 값의 크기가 큰 순서로 정렬 =");
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
int value = ((Integer) entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
} // public static void main(String[] args)
static class ValueComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Map.Entry && o2 instanceof Map.Entry){
Map.Entry e1 = (Map.Entry)o1;
Map.Entry e2 = (Map.Entry)o2;
int v1 = ((Integer)e1.getValue()).intValue();
int v2 = ((Integer)e2.getValue()).intValue();
return v2 - v1;
}
return -1;
}
} // static class ValueComparator implements Comparator
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for (int i = 0; i < bar.length; i++) {
bar[i] = ch;
}
return new String(bar); // String(char[] chArr)
}
}
결과
= 기본정렬 =
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
= 값의 크기가 큰 순서로 정렬 =
K : ###### 6
A : ### 3
D : ## 2
Z : # 1이 예제는 HashMapEx4.java를 TreeMap을 이용해서 변형한 것인데 TreeMap을 사용했기 때문에 HashMapEx4.java의 결과와 달리 키가 오름차순으로 정렬되어 있는 것을 알 수 있다. 키가 String인스턴스이기 때문에 String클래스에 정의된 정렬기준에 의해서 정렬된 것이다.
그리고 Comparator를 구현한 클래스와 Collections.sort(List list, Comparator c)를 이용해서 값에 대한 내림차순으로 정렬하는 방법을 보여 준다.
※ 참고 문헌
남궁성, 『Java의 정석 3nd Edition』, 도우출판(2016) 책으로 공부하고 정리한 내용 입니다.
