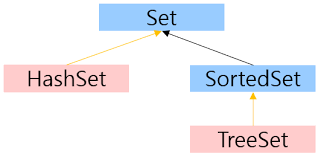
Set인터페이스
Set인터페이스는 중복을 허용하지 않고 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용된다. Set인터페이스를 구현한 클래스로는 HashSet, TreeSet 등이 있다.
HashSet
HashSet은 Set인터페이스를 구현한 가장 대표적인 컬렉션이며, Set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다.
HashSet에 새로운 요소를 추가할 때는 add메서드나 addAll메서드를 사용하는데, 만일 HashSet에 이미 저장되어 있는 요소와 중복된 요소를 추가하고자 한다면 이 메서드들은 false를 반환함으로써 중복된 요소이기 때문에 추가에 실패했다는 것을 알린다.
이러한 HashSet의 특징을 이용하면, 컬렉션 내의 중복 요소들을 쉽게 제거할 수 있다.
ArrayList와 같이 List인터페이스를 구현한 컬렉션과 달리 HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
예제1
import java.util.*;
public class HashSetEx1 {
public static void main(String[] args){
Object[] objArr = {"1", new Integer(1), "2", "2", "3", "3", "4", "4", "4"};
Set set = new HashSet();
for(int i = 0; i < objArr.length; i++){
set.add(objArr[i]); // HashSet에 objArr의 요소들을 저장한다.
}
// HashSet에 저장된 요소들을 출력한다.
System.out.println(set);
}
}
결과
[1, 1, 2, 3, 4]결과에서 보이듯이 중복된 값은 저장되지 않았다. add메서드는 객체를 추가할 때 HashSet에 이미 있는 객체가 있으면 중복으로 간주하고 저장하지 않는다. 그리고는 작업이 실패했다는 의미로 false를 반환한다.
1이 두번 출력 된 것을 확인할 수 있는데 String인스턴스와 Integer인스턴스로 생성된 각각의 1이기 때문에 중복으로 간주하지 않는다.
Set을 구현한 컬렉션 클래스는 List를 구현한 컬렉션 클래스와 달리 순서를 유지하지 않기 때문에 저장한 순서와 다를 수 있다.
만일 중복을 제거하는 동시에 저장한 순서를 유지하고 싶으면 LinkedHashSet을 사용해야한다.
예제2
import java.util.*;
public class HashSetLotto {
public static void main(String[] args){
Set set = new HashSet();
for(int i = 0; set.size() < 6; i++){
int num = (int)(Math.random() * 45);
set.add(new Integer(num));
}
List list = new LinkedList(set); // LinkedlIST(Collection c)
Collections.sort(list); // Collections.sort(List list)
System.out.println(list);
}
}
결과
[3, 5, 12, 19, 30, 33]중복된 값은 저장되지 않는 HashSet의 성질을 이용해서 로또번호를 만드는 예제이다. Math.random()을 사용했기 때문에 실행할 때 마다 결과는 다를 것이다.
번호를 크기순으로 정렬하기 위해서 Collections클래스의 sort(List list)를 사용했다. 이 메서드는 인자로 List인터페이스 타입을 필요로 하기 때문이 LinkedList클래스의 생성자 LinkedList(Collection c)를 이용해서 HashSet에 저장된 객체들을 LinkedList에 담아서 처리했다.
실행결과의 정렬기준은, 컬렉션에 저장된 객체가 Integer이기 때문에 Integer클래스에 정의된 기본정렬이 사용되었다.
TreeSet
TreeSet은 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다.
- 정렬, 검색, 범위검색(range search)에 높은 성능을 보이는 자료구조
- TreeSet은 이진 검색 트리의 성능을 향상시킨 '레드 - 블랙 트리(Red - Black tree)'로 구현되어 있다.
- 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
이진 트리(binary tree)는 링크드리스트처럼 여러 개의 노드(node)가 서로 연결된 구조로, 각 노드에 최대 2개의 노드를 연결할 수 있으며 '루트(root)'라고 불리는 하나의 노드에서부터 시작해서 계속 확장해 나갈 수 있다.
위 아래로 연결된 두 노드를 '부모 - 자식관계'에 있다고 하며 위의 노드를 부모 노드, 아래의 노드를 자식 노드라 한다. 부모 - 자식관계는 상대적인 것이며 하나의 부모 노드는 최대 두 개의 자식 노드와 연결된 수 있다.
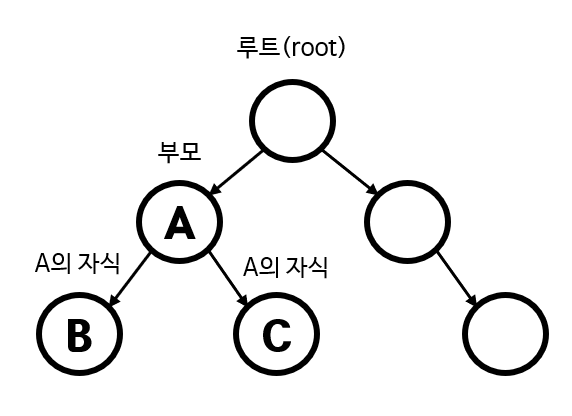
예를 들어 데이터를 5, 1, 7의 순서로 저장한 이진 트리의 구조는 아래와 같이 표현할 수 있다.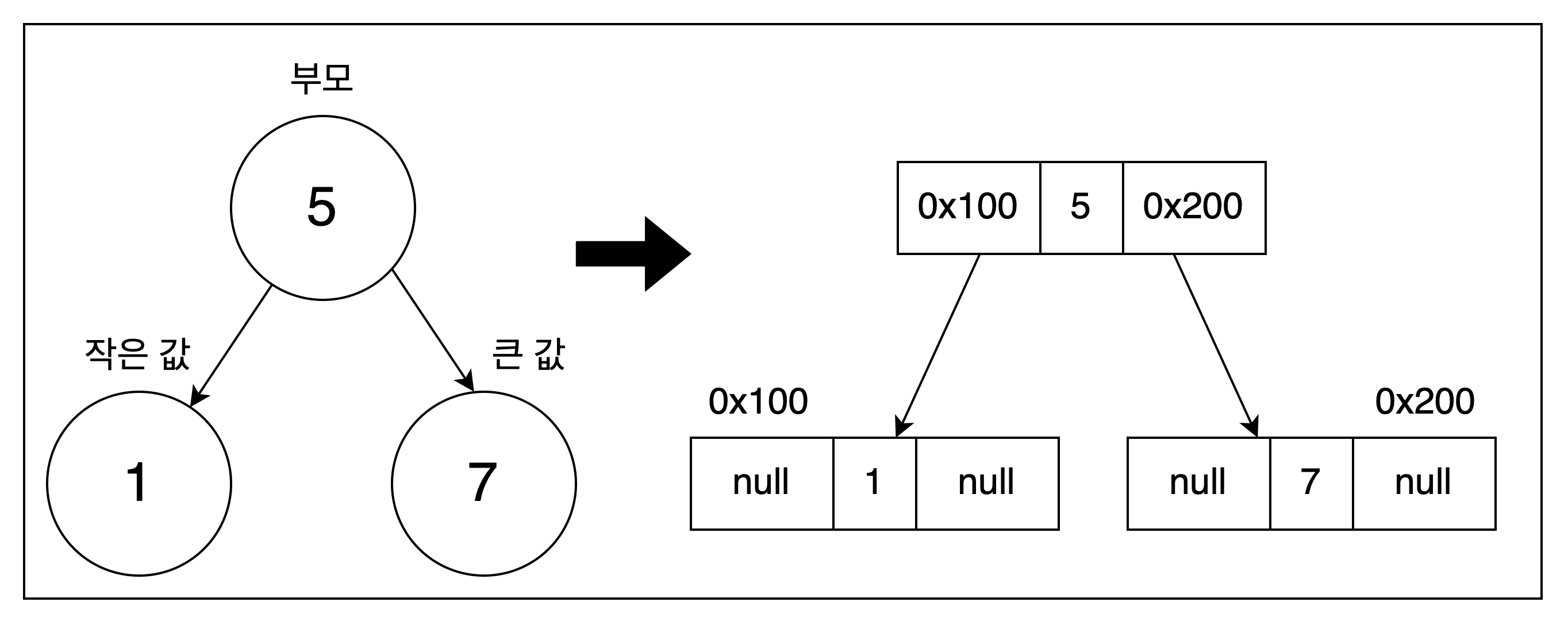
이진 검색 트리(binary search tree)는
- 모든 노드는 최대 두 개의 자식노드를 가질 수 있다.
- 왼쪽 자식노드의 값은 부모노드의 값보다 작고 오른쪽자식노드의 값은 부모노드의 값보다 커야한다.
- 노드의 추가 삭제에 시간이 걸린다.(순차적으로 저장하지 않으므로)
- 검색(범위검색)과 정렬에 유리하다.
- 중복된 값을 저장하지 못한다.
※ 참고 문헌
남궁성, 『Java의 정석 3nd Edition』, 도우출판(2016) 책으로 공부하고 정리한 내용 입니다.
