
세미나에 앞서 팀의 목적을 이해해야한다.
특정 서비스만을 위해 개발하는 것이 아니라 데이터와 플랫폼을 필요로 하는 타 서비스에서도 사용할 수 있게 일을 하고 있다.
그렇다면 Data Scientist들은 어떤 것들을 필요로 하는가?

따라서 사용자들이 필요로 하는 데이터 분석 환경 파이프라인을 제공하는 일을 하고 있고 어떻게 하고 있는지 하나씩 이야기를 소개하는 세션이었다.
나는 이 세션을 통해 해결하고자 했던 물음표는
- BigQuery가 타 서비스에 비해 가지는 특장점
- 데이터 파이프라인 구현을 하며 겪은 시행착오와 해결법
이 두 가지 정도였다.
아직 다뤄본 적 없는 분야이기에 이 정도의 목표에 집중하며 들었다.
BigQuery 기반의 데이터 웨어하우스
sk텔레콤의 사례
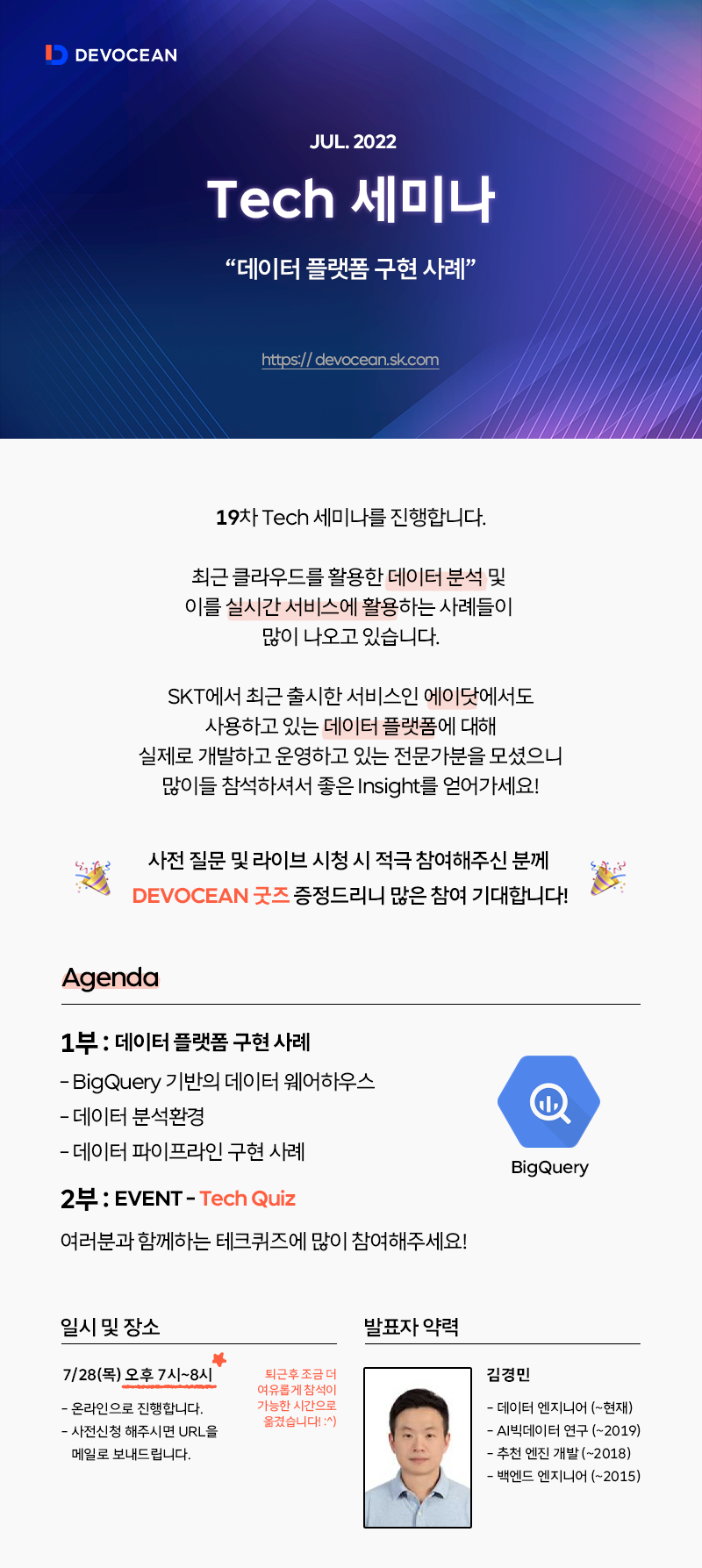
sk텔레콤에서는 모든 데이터가 흘러 들어가는 전사 차원의 Data Lake가 있다.
유저 정보나 서비스 로그 정보, 네트워크 통신 등 다양한 Data Lake에 모이고 있는데
아쉽게도 이 전체를 관리하고 있진 않고, 이 Data Lake를 관리하는 조직을 갖고 있다.
따라서 데이터를 얻기 위해서 Data Lake로부터 데이터를 받아볼 수밖에 없는 상황이다.
이렇게 받은 데이터를 연관된 데이터 사이언티스트들이 사용할 수 있도록 Data Warehouse에 적재를 하고, 이를 가지고 데이터 사이언티스트들이 작업을 하게 되는 구조이다.
Data Lake vs Data Warehouse
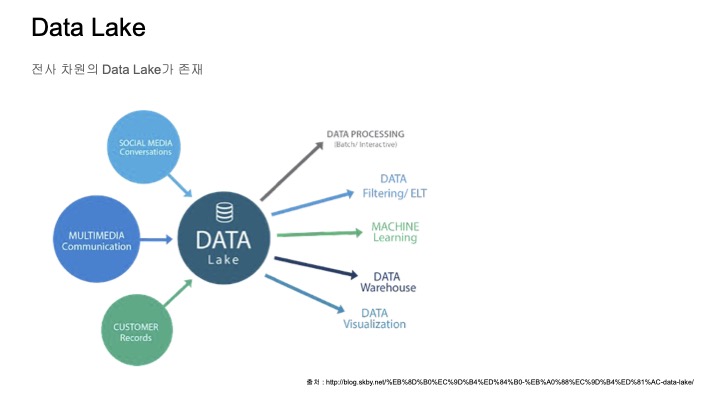
Data Lake는 다양한 종류의 로그 데이터들이 있는 반면에 Data Warehouse는 조금 더 정제되어 있다.
따라서 Data Lake는 머신러닝이나 프로세싱에 적합하고,
Data Warehouse는 Batch processing이나 BI Reporting에 적합하다.
BigQuery

BigQuery 공식 문서를 보면 이점이나 사용 방법에 대해 쉽게 설명되어있다.
주요 이점으로는 아래의 3가지를 강조하고 있다.
- 실시간 분석과 예측 분석으로 유용한 정보 확보
- 손쉬운 데이터 액세스 및 유용한 정보 공유
- 데이터 보호 및 신뢰할 수 있는 운영
그렇다면 기존에 유명한 aws Athena와의 차이점은 어떤 것이 있을까?
BigQuery vs AWS Athena
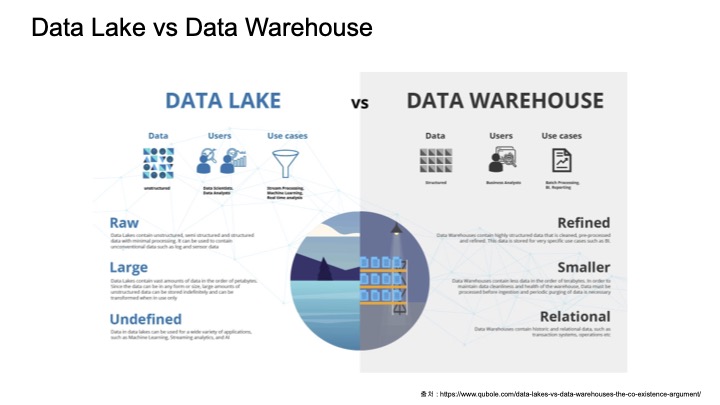
bigQuery vs athena이곳에 자세한 설명이 나와 있어서 첨부해둔다.
이 둘의 가장 큰 차이점은 데이터를 관리하는 방법이다.
aws s3를 사용하고 있다면, athena는 로그를 별도의 경로로 올리지 않아도 되고 그냥 테이블 스키마를 만들면서 s3의 경로만 추가해주기만 하면 된다.
하지만 bigQuery의 경우에는 로그를 별도의 경로로 올려주어야한다.

결론은 복잡한 작업을 해야 하는 경우엔 bigQuery를 쓰면 좋은 것 같고,
그렇지 않고 s3까지 사용하고 있다면 athena가 편할 것 같다.
sk텔레콤의 경우엔 복잡한 작업을 하게 되는 경우가 많고,
s3를 크게 사용하지 않아서? 아니면 기능적 편의성 때문에 bigQuery를 선택한 것이라 추측된다.
BigQuery 파이프라인
아래는 bigQuery 파이프라인에 대한 설명이다.
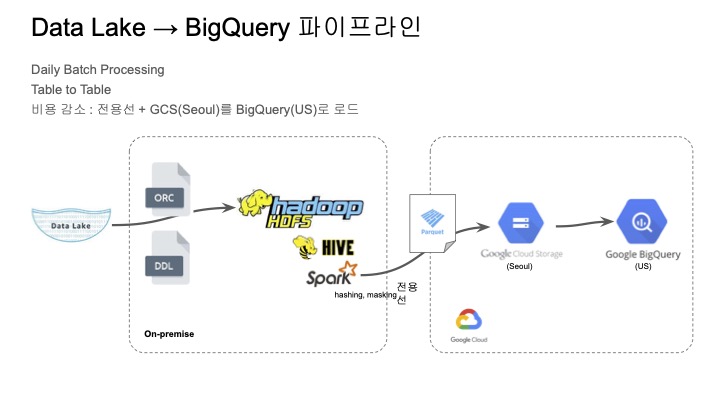
특이한 점은 중간에 클라우드 스토리지(Seoul)를 거치고 bigQuery로 로드하고 있으며,
bigQuery는 US 리전으로 사용하고 있다.
일단 정액제를 사용하면 클라우드 스토리지에서 bigQuery로 로드하는 비용이 무료이고,
US 리전에서는 이제 클라우드 스토리지 버킷에서 bigQuery로 나가는 데이터 이그레스 비용이 비용 절감 효과가 크기 때문에 이런 방식을 사용을 하고 있다고 한다.
Airflow
파이프라인을 구현하기 위해서는 워크 플로우를 관리하는 툴이 필요한데,
sk텔레콤은 Airflow를 사용하고 있다.
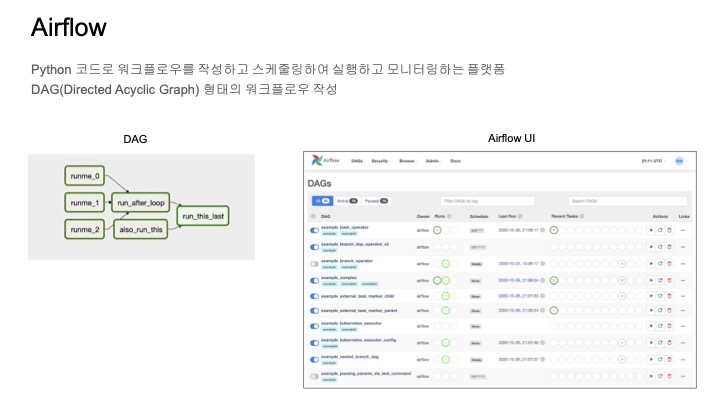
python 코드를 작성하여 DAG를 정의할 수 있는데, DAG안의 각 단계들을 task라고 한다.
Airflow 스케줄러가 코드를 파싱해서 DAG에 등록해서 스케줄링하게 되는 방식이고,
스케줄 된 DAG는 Airflow UI를 통해 쉽게 볼 수 있다.

또한 DAG를 python으로 파이프라인(데이터 확인 -> 전송 -> 로드)을 구성하고 Airflow를 배포하면 UI에서 작업의 진행 상태를 확인할 수 있다는 장점도 있다.
Backfill
모든 게 잘 되면 좋겠지만, 항상 어딘가 문제가 생겨서 제대로 되지 않는 경우가 종종 발생하는데
이런 경우, 데이터에 구멍이 생기게 되는 문제점이 발생한다.
이 구멍을 메우는 작업이 backfill이라고 하고 backfill이 필요한 경우는 아래와 같다.

Airflow에 특정 날짜를 지정하여 이를 해결하는 명령어가 있지만 이는 한계가 있다.

결국 어느 정도 수동으로 하게 되는 상황이 발생했는데,
다뤄야 할 테이블과 데이터가 많기 때문에 아래와 같은 방법을 고안해냈다고 한다.
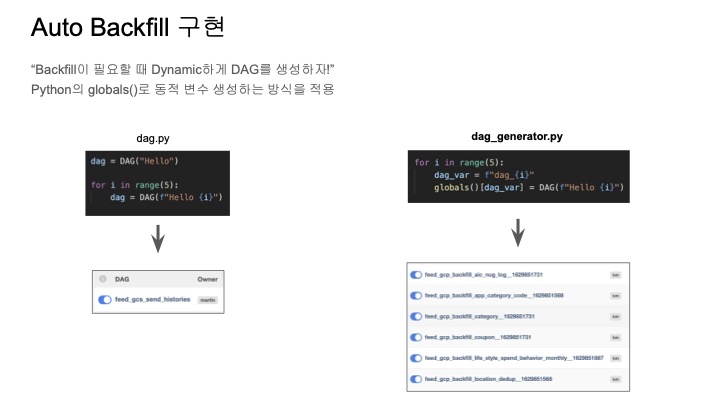
대그를 동적으로 생성하는 방식은 Airflow에서 일반적인 방식은 아니지만,
backfill이 필요할 때 동적으로 DAG를 동적으로 생성한다는 아이디어이다.
그러나 DAG같은 경우 전역 스코프에 존재해야하는데 왼쪽의 경우에는 for문을 이용해서 DAG를 생성해도 결국 DAG라는 변수에 겹쳐 쓰기 때문에 하나만 생성이 되는 문제점이 있다.
그를 해결하기 위해서 오른쪽과 같이 globals 함수를 이용하여 딕셔너리 형태로 만들어 주고,
이 딕셔너리 아이템을 추가해서 변수를 동적으로 선언하여 해결할 수 있다.
이렇게 구현한 Auto Backfill 아키텍쳐는 아래와 같이 구성되어 있다.
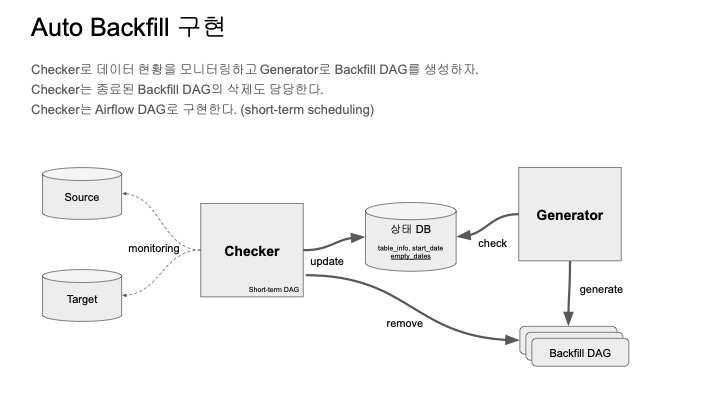
Checker가 소스와 타겟을 모니터링하면서 상태DB에 저장한다.
그리고 Generator가 상태DB를 보면서 동적으로 backfill DAG를 생성한다.
하지만 이렇게 생성된 DAG가 자동으로 사라지지 않는다.
이는 Checker가 주기적으로 backfill DAG를 모니터링 하면서 종료된 DAG들은 정리해줌으로써 해결한다.
이렇게 하면 Checker와 Generator를 이용하는 Airflow내에서 auto backfill의 문제를 해결할 수 있다.
그렇다면 이제 실시간의 경우엔 어떻게 할까?
실시간 처리
보통 실시간의 경우에는 스트리밍 플랫폼을 사용하여 전송하는 경우가 많은데,
스트리밍을 사용할 수 없는 경우에 대해서는 아래와 같이 처리한다.
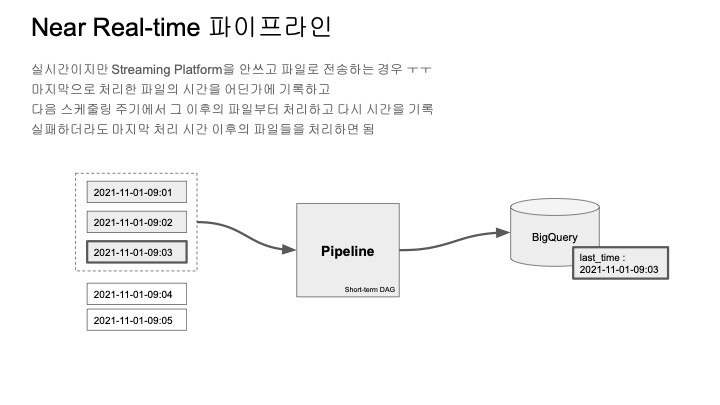
데이터가 특정 경로에서 시간순으로 쌓인다고 가정하고,
소스 경로에 쌓인 데이터들을 파이프라인이 처리하고 나면 마지막 처리 데이터 시간을 기록한다.
이때, 기록은 bigquery의 labeling이라는 기능을 이용해서
bigquery tabel자체 메타 데이터 형식으로 저장한다.
또, 계속해서 데이터가 들어오면 마지막 처리 시간보다 나중에 들어온 데이터를 감지해서 처리하도록 되어있다.

이렇게 labeling을 했을 때 가지는 장점은
- 마지막 처리 시간이라는 체크 포인트가 있어서 실패해도 계속 이어서 처리할 수 있다.
- 상태 정보를 관리하는 DB나 저장소를 별도로 관리하지 않아도 돼서 아키텍처가 심플해지고 운영 포인트가 줄어든다.
데이터 파이프라인 구현 사례
생기게 될 고통
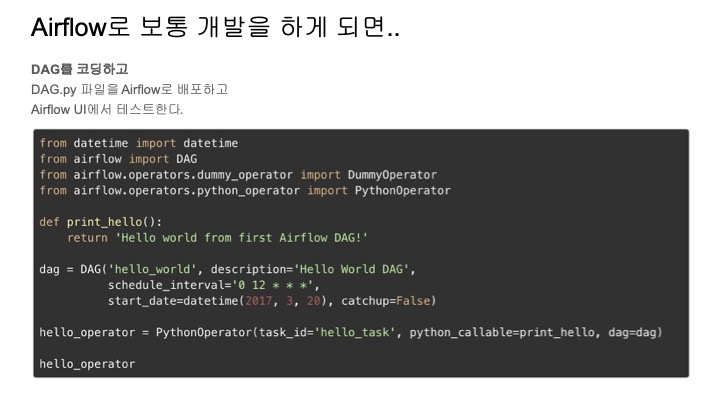
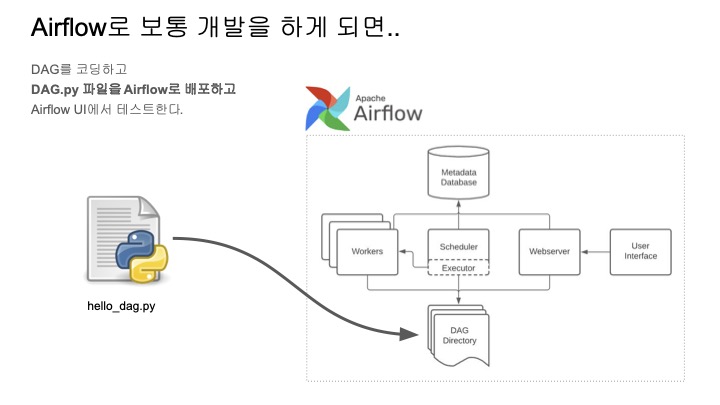
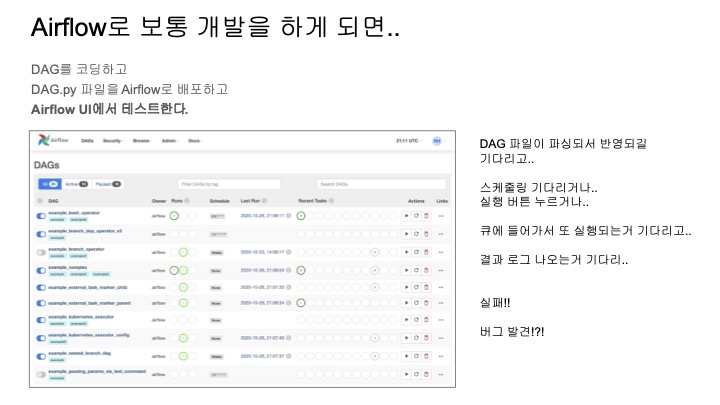


한 마디로 작업환경이 썩 기분 좋지 않다는 것이다.
근데 더 절망적인 것은,
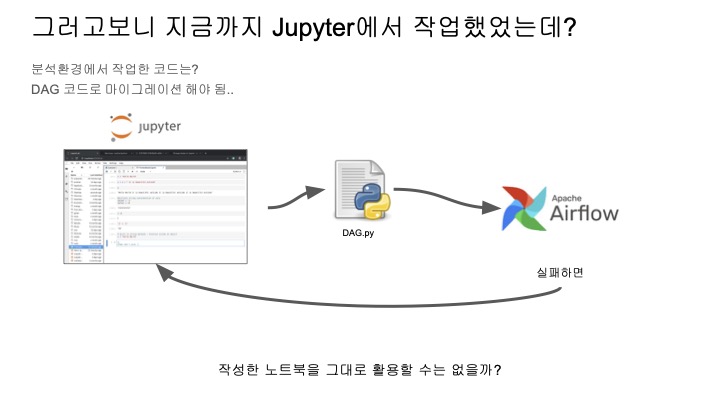
어떻게 하면 편해질 수 있을까?
일단, 작성한 노트북을 그대로 활용할 수 있다면 훨씬 편해질 수 있을 것이다.
이를 위해서 papermill이라는 것을 사용한다.
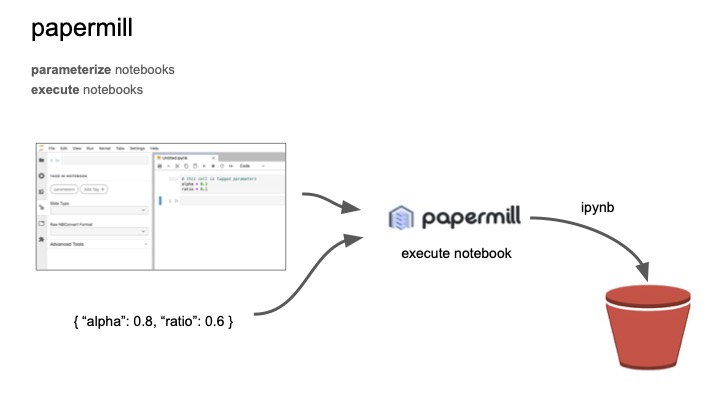
papermill은 노트북에 파라미터를 주입해서 실행시켜주고 저장소에 결과를 업데이트시켜준다.
papermill을 사용하여 노트북을 실행시켜주는 서비스, 줄여서 NES라고 한다.
아키텍쳐는 아래와 같다.
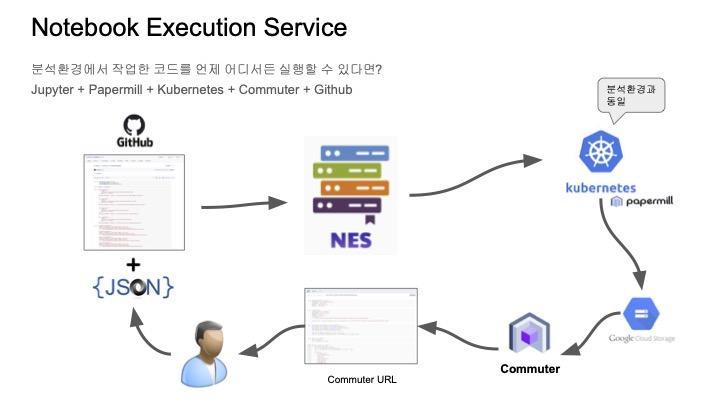
- 실행한 노트북을 깃헙에 푸쉬를 한다.
- 노트북이 위치한 이제 깃헙 주소와 파라미터를 이제 NES에 던져서 실행 요청을 한다.
- NES는 Kubernetes 클러스터에 papermill pod를 생성하여 노트북을 실행한다.(여기서 Kubernetes는 분석환경에서 사용되는 Kubernetes와 같다.)
- 결과는 GCS에 노트북 파일로 저장이 되고 업데이트가 된다.
- Commuter를 사용하면 저장소에 있는 노트북 파일을 웹에서 확인이 가능하다.
- 사용자는 이 Commuter URL에 접속하여 해당 노트의 실행 결과를 확인할 수 있다.
아래는 NES의 실행 과정을 사용자 관점에서 정리한 것이다.
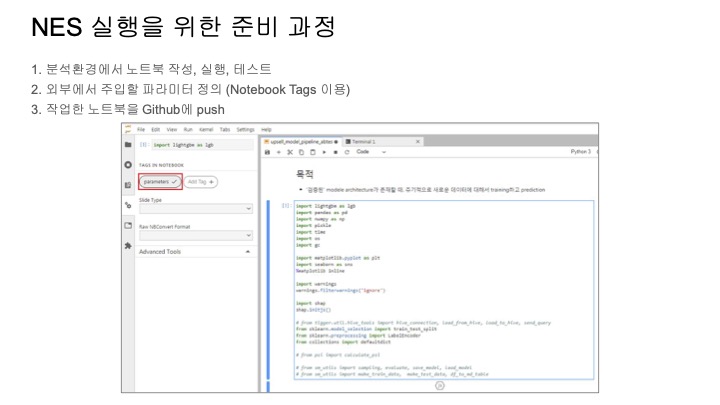
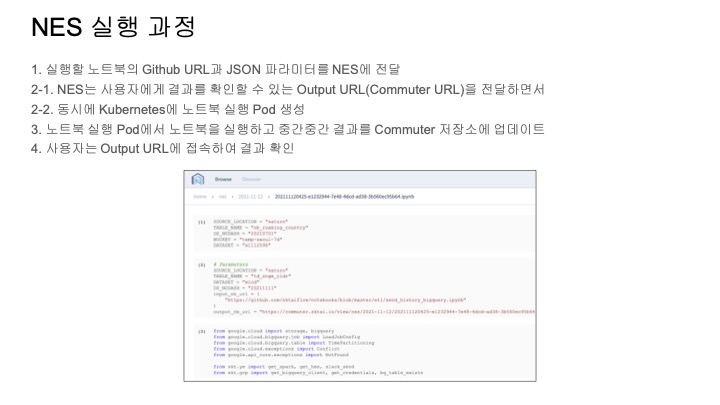
Airflow에서 NES를 이제 실행하려면 NesOperator를 사용해야 되는데 아래와 같이,
실행할 노트북 주소와 파라미터를 생성자에게 전달해주면 노트북을 실행하는 테스크를 쉽게 만들 수 있다.

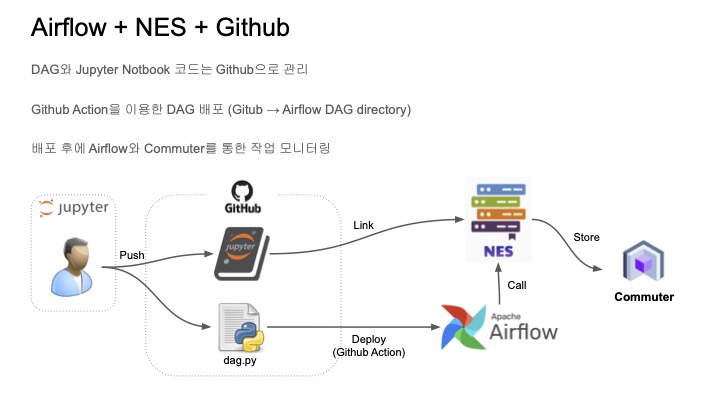
노트북과 DAG 파일을 깃헙에 푸시를 하면 DAG 파일이 Airflow로 배포가 되고 이제 DAG에서는 노트북을 이제 NES 통해서 실행할 수가 있게 된다.
만약 에러가 나더라도 DAG 자체를 수정할 필요 없이,
노트북만 수정해서 깃헙에 푸시하면 따로 DAG 파일을 배포할 필요는 없다.

어떤 문제가 이렇게 해결되는 거 보면 뭔가 짜릿하다.
운영
문제점
- 운영하는 내용이 많음
- 요구사항이 많아짐
- 한정적인 인력
- 하는 일이 시각적으로 보이지 않음
- 프론트 개발자의 부재
해결책

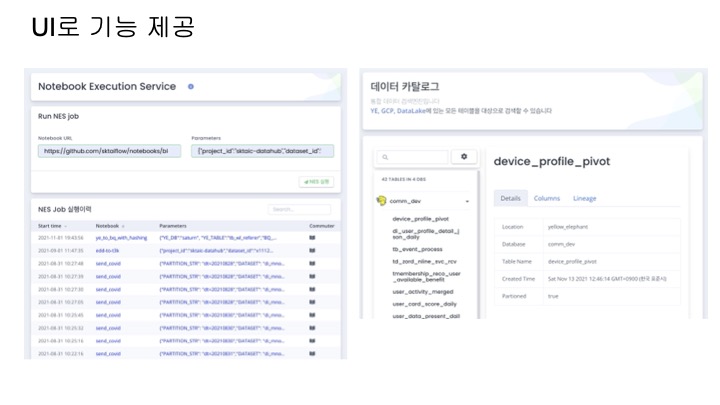
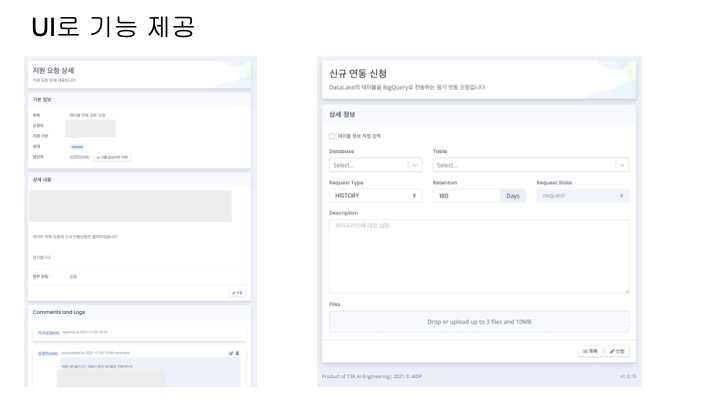
실시간 위치 데이터 처리
아래는 사용자의 위치 정보를 실시간으로 수집하는 파이프라인 아키텍쳐이다.
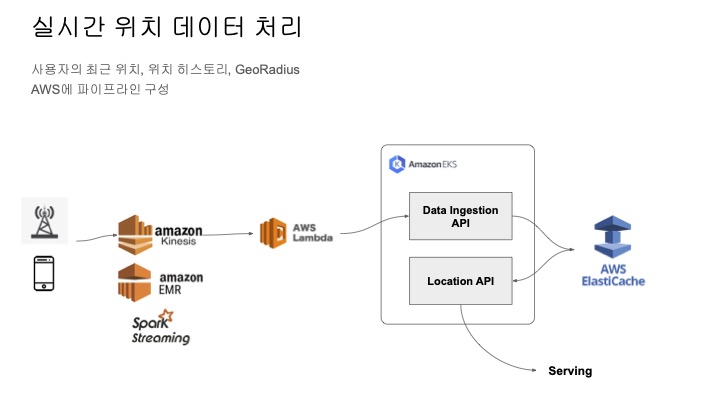
특이한 부분은 데이터 저장 속도를 빠르게 하기 위해서 Data Ingestion API를 두고 있다는 점이다.
이것도 크게 특별한 점은 아니기에 인프라 관리를 위한 IaC에 대해 살펴보았다.
IaC
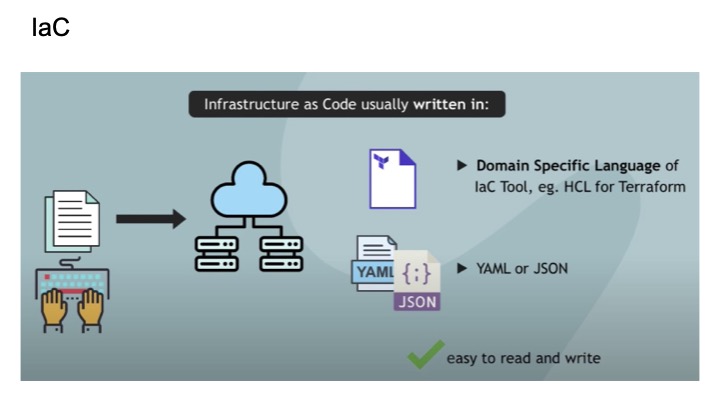
IaC는 코드로 인프라를 관리한다는 것인데 보통 인프라 정의를 할 때,
TerraForm에서는 HCL이라는 벤더사에서 제공하는 domain specific language가 있다.
이걸 사용하거나, yaml이나 json을 사용한다.
하지만 specific language를 학습해야 한다던가 유연성이 떨어질 수 있다.
Pulumi
이를 해결하기 위해서 Pulumi라는 것이 있는데 이는 javascript, python, .net 등등 범용언어를 지원한다.
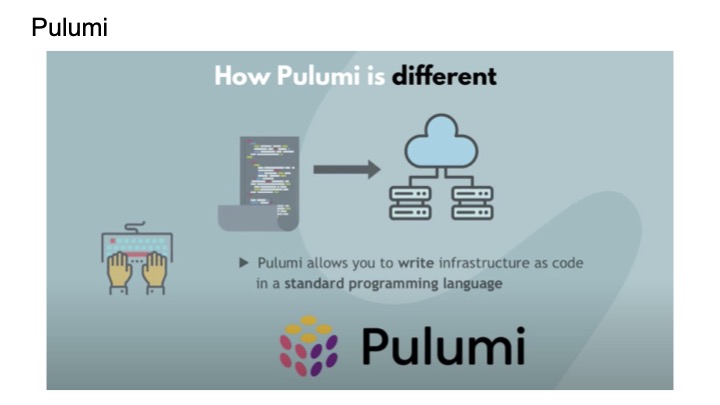

참고로 오픈소스는 아니지만, 계정에 하나만 유지하고 있는 경우 무료로 사용할 수 있다고 한다.
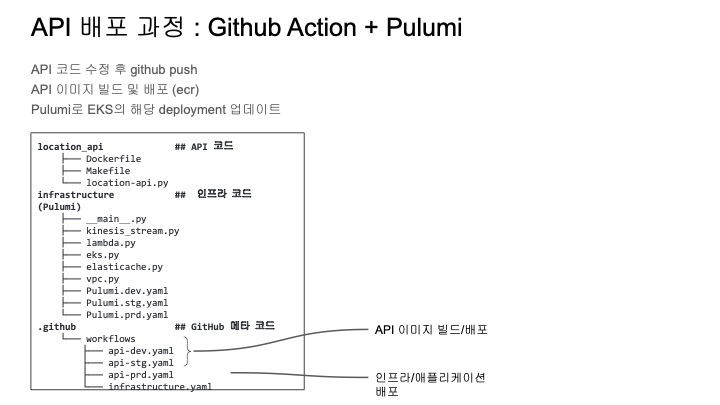
API 배포 과정
이벤트

데보션에서 세미나 실시간 이벤트도 한다.
이런 이벤트를 시작한 지는 얼마 안됬지만 50p씩 2번 해서 총 100p를 주는데,
마일리지 차곡차곡 모으는 재미가 있다.
세미나 후기 테크 퀴즈도 열렸다.
후기
완전 생소한 분야는 아니지만, 알지 못하고 있었던 개념들이었다.
이번 세미나의 모든 내용을 공감하고 흡수하진 못했으나,
결국 개발은 어떠한 문제를 해결하기 위함이라는 목적이니 문제에 대해선 공감하려 노력했다.
아예 모르고 있는 것보다 얕게나마 알고 있거나 문제에 대해 공감해놓는게 나중에 2가지 측면에서 도움이 되었다.
- 문제를 문제로 인식할 수 있다.
- 해결책을 더 쉽게 찾을 수 있었다.
이 측면에서 데보션 세미나는 항상 만족스러웠기에 앞으로도 새로운 이벤트가 생기면 계속 들을 생각이다.
