Today I Learned
sqld 시험 하루 전. 면접준비 때문에 제대로 준비는 못했던 시험이라 남은 이틀 벼락치기를 몰아서 한 감이 있다. 내일 시험 파이팅!
대용량 데이터에 따른 성능
블록
테이블의 데이터 저장 단위
대량 데이터 발생으로 인한 현상
블록 I/O 횟수 증가 -> 디스크 I/O 가능성 상승 -> 디스크 성능 저하 가능성 상승
- 로우 체이닝 : 행 길이가 너무 길어 여러 블록에 걸쳐 저장되는 현상
- 로우 마이그레이션 : 수정된 데이터가 해당 블록이 아닌 다른 블록의 빈공간에 저장되는 현상
테이블 분할(반정규화 기법)
- 수직분할 : 컬럼 단위로 테이블을 분할해 I/O를 감소. 컬럼이 너무 많을 때 사용
- 수평분할 : 행 단위로 테이블을 분할해 I/O를 감소
파티셔닝
테이블 수평분할 기법. 논리적으로는 하나의 테이블이지만 물리적으로 여러 데이터 파일에 분산 저장. 데이터 조회 범위를 줄여 성능 향상
- Range Partition : 데이터 값의 범위를 기준으로 분할
- List Partition : 특정한 값을 기준으로 분할
- Hash Partition : 해시함수를 적용해 분할. DBMS가 알아서 관리해 데이터 위치를 알 수 없음
- Composite Partition : 여러 파티션 기법을 복합적으로 사용해 분할
DB 구조와 성능
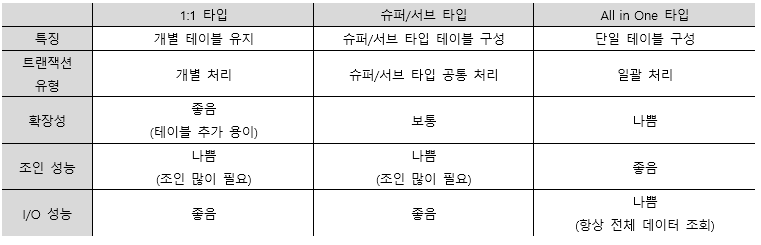
슈퍼/서브 타입 모델 변환을 통한 성능 향상
-
슈퍼/서브 타입 데이터 모델
속성을 할당해 배치하는 수평 분할 형태의 모델
공통 속성은 슈퍼, 차이가 있는 속성은 서브타입으로 구분.
업무를 정확하게 표현할 수 있고, 물리적 모델링 시 선택의 폭 넓힐 수 있음 -
변환 기준 : 데이터 양, 트랜잭션 유형
변환 기술
PK/FK 컬럼 순서 조절을 통한 성능 향상
등호나 BETWEEN 조건이 걸리는 컬럼을 앞으로 이동
인덱스 특성을 고려한 PK/FK DB 성능 향상
물리적 테이블에 FK 제약을 걸어 인덱스 생성
분산 DB 데이터에 따른 성능
분산 DB
분산된 DB를 하나의 가상 시스템으로 사용할 수 있도록 한 DB
물리적 사이트는 분산되어 있으나 논리적으로는 동일한 시스템
-
설계 방식
상향식 : 지역 스키마 작성 후 전역 스키마 작성
하향식 : 전역 스키마 작성 후 지역 스키마 작성 -
장점
신뢰성/가용성, 빠른 응답속도와 비용 절감, 용량 확장 용이 -
단점
관리 및 통제의 어려움, 데이터 무결성 관리 어려움, SW 개발 및 관리 비용 증가, 불규칙한 응답 속도
분산 DB의 투명성
- 분할 투명성 : 하나의 논리적 관계가 분할되어 각 사본이 여러 사이트에 저장
- 위치 투명성 : 사용하려는 데이터 저장 장소가 명시되지 않아도 됨
- 지역사상 투명성 : 지역 DBMS와 물리적 DB의 사상이 보장
- 중복 투명성 : DB 객체 중복 여부를 몰라도 됨
- 장애 투명성 : 구성요소의 장애에 무관하게 트랜잭션의 원자성이 보장
- 병행 투명성 : 다수의 트랜잭션 동시 수행시 결과의 일관성 유지(not 병렬 투명성)
분산 DB 적용 기법
- 테이블 위치 분산 : 설계된 테이블의 위치를 분산
- 테이블 분할 분산 : 수평/수직으로 테이블을 쪼개서 분산
- 테이블 복제 분산 : 동일한 테이블을 다른 지역이나 서버에 동시 생성. 부분/광역 복제
- 테이블 요약 분산 : 분석요약 / 통합요약

Full-Stack Dev / MLOps