Today I Learned
SQLD 문제를 풀면서 데이터 모델과 성능 파트를 정리했다.
성능 데이터 모델링
DB 성능 향상을 위한 사항이 데이터 모델링에 반영되도록 하는 것
-
수행 시점: 분석 설계 단계. 늦어질 수록 재업무 비용이 증가
-
고려사항 : 정규화, DB 용량, 트랜잭션 유형 파악을 통한 반정규화
정규화와 성능
정규화
데이터 분해 과정. 이상현상(Anomaly) 제거
-
정규형 : Normal Form. 정규화로 도출된 데이터 모델이 갖춰야 할 특성
-
함수적 종속성 : FD. 결정자와 종속자의 관계. 결정자로 종속자를 알 수 있음
정규화 과정
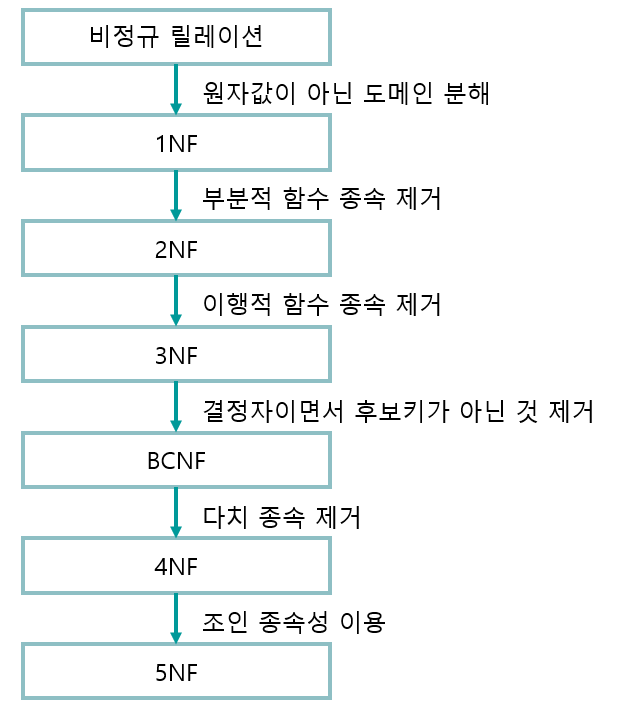
-
1차 정규화 : 속성의 원자성 확보. 다중값 속성을 분리
-
2차 정규화 : 부분 함수 종속성 제거. 일부 기본키에만 종속된 속성 분리
-
3차 정규화 : 이행 함수 종속성 제거. 서로 종속 관계가 있는 일반속성 분리
-
보이스코드 정규화 : BCNF. 후보키가 기본키 속성 중 일부에 함수적 종속일 때 다수의 주식별자 분리
-
4차 정규화 : 다치 종속 분리
-
5차 정규화 : 결합 종속 분리
성능
-
정규화로 인한 성능 향상
입력/수정/삭제시 성능은 향상된다.
유연성증가, 재활용 가능성 증가, 데이터 중복 최소화 -
정규화로 인한 성능 저하
조회 시 조건에 따라 성능 저하 가능
조인을 유발해 자원 소모 多 -> 반정규화나 인덱스로 해결 가능.
반정규화
데이터 중복을 허용해 조인을 줄이는 DB 성능 향상 방법
데이터 무결성을 희생하고 조회 성능 향상
- 대상을 조사하고 다른 방법을 검토한 뒤 반정규화 적용
테이블 반정규화
-
테이블 병합
1:1 테이블 병합, 1:N 테이블 병합, 슈퍼/서브타입 테이블 병합 -
테이블 분할 : 수직/수평
-
테이블 추가
중복테이블, 통계 테이블, 이력 테이블, 부분 테이블
컬럼 반정규화
- 중복 컬럼 추가
- 파생 컬럼 추가(필요한 값 미리 계산한 컬럼 추가)
- 이력 테이블 컬럼 추가
- PK에 의한 컬럼 추가
- 시스템 오작동을 위한 컬럼 추가
관계 반정규화
데이터 무결성 보장 가능
- 중복관계 추가
