Today I Learned
오늘은 AI 강의 피처엔지니어링 파트를 수강했다.
Feature Engineering
원본 데이터로부터 도메인 지식을 바탕으로 문제를 해결하는 데 도움이 되는 feature를 생성, 변환하고 이를 머신러닝 모델에 적합한 형식으로 변환하는 작업
-
feature : 머신 러닝 모델이 학습하는 데이터의 각 속성이나 변수
모델이 예측을 위해 사용하는 입력 데이터의 특성들 -
label 별 분포가 확연히 다른 피처가 좋은 피처다. 머신러닝 모델은 결국 타겟을 구분할 수 있는 패턴을 인식하는 것이고, 따라서 어떤 피처가 타겟 레이블 별로 분포가 다르면 모델이 이 패턴을 쉽게 인식할 수 있기 때문에 좋은 피처라 할 수 있다. -
딥 러닝이 아닌 머신러닝에서는 모델의 성능을 올리는 데
가장 중요한 핵심적인 단계
(딥러닝은 모델이 알아서 피처를 찾지만 일반 머신러닝은 사람이 골라야한다) -
피처 엔지니어링은 원본 데이터에서 유용한 피처를 찾아내고, 새로운 피처를 만들고, 불필요한 피처를 제거하는 등의 작업을 말한다.
기법
1. Pandas GroupBy Aggregation
원본 데이터에서 주어진 feature에 고객 id 기반으로 Pandas GroupBy Aggregation 함수를 적용해 새로운 feature 생성.
- GroupBy
GroupBy는 데이터를 하나 이상의 키(key)를 기준으로 그룹화하는 작업
ex) 고객 데이터를 지역별로 그룹화
grouped = data.groupby('region')- Aggregation
Aggregation은 그룹화된 데이터에 적용할 연산을 지정하는 작업
sum(), mean(), median(), min(), max(), std(), skew() 등의 aggregation 함수가 있다.
(skew는 왜도로 데이터 분포의 비대칭성을 나타내는 지표, 0이면 정규분포 양이면 우측 치우침)
ex) 각 지역별 고객 수, 평균 구매액 등
region_counts = grouped.size() # 각 지역별 고객 수
region_means = grouped['purchase_amount'].mean() # 각 지역별 평균 구매액- 응용
GroupBy와 Aggregation을 조합하면 다중 레벨 그룹화, 다중 집계 같은 복잡한 데이터 처리도 가능하다.
# 지역, 제품별로 그룹화하고 판매량과 매출액 집계
sales_stats = data.groupby(['region', 'product'])['quantity', 'revenue'].agg(['sum', 'mean'])- 프로젝트에선 total-sum, price-sum, price-count 같은 GroupBy Aggregation을 사용하면 분포가 다르게 나온다.
2. Cross Validation을 이용한 Out of Fold 예측
모델 training 시 Cross Validation(교차 검증)을 적용해서 Out of Fold Validation 성능 측정 및 Test 데이터 예측을 통해 성능을 향상하는 기법
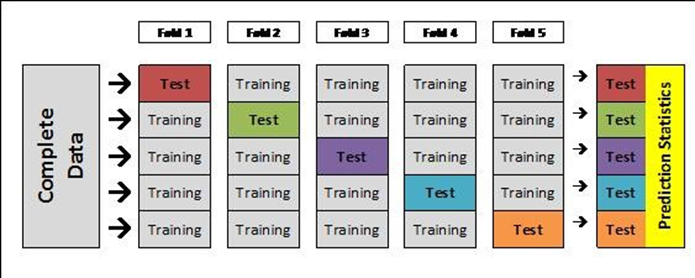
-
Cross Validation : 데이터를 여러개의 fold로 나눠서 Validation 성능을 측정하는 방법
-
Out of Fold 예측은 폴드마다 트레이닝한 모델로 test 데이터를 예측하고, 이러면 폴드 개수만큼의 test 데이터 결과가 나오는데 이를 average 앙상블에서 최종 테스트 예측 값으로 사용하는 방식이다.
-
캐글같은 머신러닝 경진대회에선 대부분 이 방식을 사용한다.
3. LightGBM Early Stopping
-
Early Stopping
Iteration을 통해 반복학습이 가능한 머신러닝 모델에서 validation 성능 측정을 통해 가장 성능이 좋은 하이터퍼라미터에서 학습을 조기종료하는 Regulation 방법
ex) Boosting 트리 모델 트리 개수, 딥러닝의 Epoch 수 -
LightGBM에서는 몇개의 트리를 만들지
n_estimators라는 하이퍼 파라미터로 설정하고 이만큼 트리를 만들지만 이 트리 수가 최적값이라고는 볼 수 없다. -
Early Stopping은 validation 데이터가 있으면 n_estimators는 충분히 크게 설정하고,
early_stopping_rounds를 적절한 값으로 설정한다. -
트리를 추가할 때 마다 validation 성능을 측정하고 이 성능이 early_stopping_rounds 값 이상 연속으로 성능이 좋아지지 않으면 더이상 트리를 만들지 않고 validation 성능이 가장 좋은 트리 개수를 최종 트리 개수로 사용한다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
