Today I Learned
오늘 공부한 내용은 정규화!
Regularization(정규화)
Overfitting 문제를 해결하고 일반화 성능을 높이기 위해 규제를 거는 방법.
기법
Early Stopping
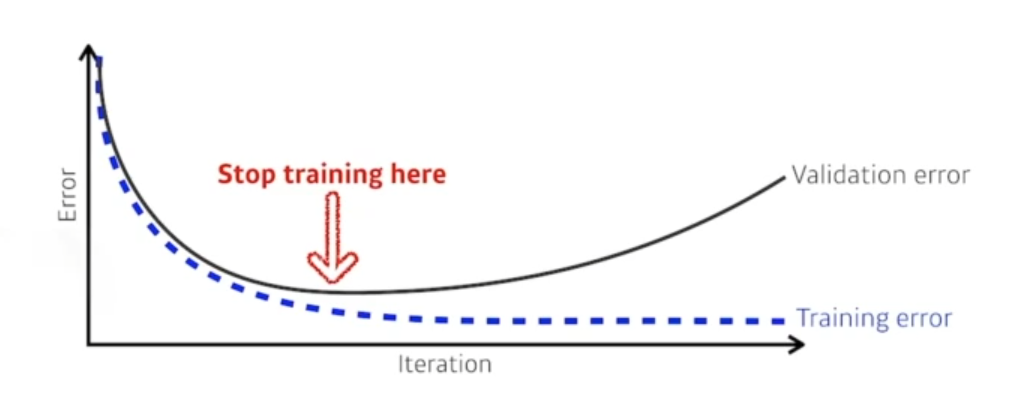
-
훈련 데이터나 검증 데이터에 대한 오차가 감소하지 않거나 증가하는 지점을 기준으로, 훈련을 미리 종료하는 기법
-
훈련에 사용하지 않은 validation 데이터의 에러가 가장 적게 나오는 지점에서 멈춘다.
-
모델이 과적합되기 전에 훈련을 중지하여 일반화 성능을 향상시킵니다.
Parameter Norm Penalty
-
파라미터가 (절대값이)너무 커지지 않게 하는것. 최대한 부드러운 함수를 만들어 일반화 성능을 높이려한다.
-
모델의 가중치를 제한하기 위해 가중치의 크기에 대한 페널티를 부과하는 기법이다.
-
주로 L1 정규화 또는 L2 정규화와 같은 방법을 사용한다.
Data Augmentation
-
훈련 데이터의 다양성을 증가시키기 위해 기존 데이터에 변형을 가하는 기법
-
머신러닝에서 데이터는 일반적으로 많으면 많을수록 좋다. 데이터가 많을수록 일반화 성능이 높아진다.
-
이미지 데이터의 경우 회전, 이동, 반전 등의 변환을 시켜 데이터를 증가시킨다. (단, 이미지의 label이 변하지 않는 선에서 변환을 시켜야한다)
Noise Robustness
-
모델이 입력 데이터에 포함된 노이즈에 강건하게 대응할 수 있도록 훈련하는 기법
-
입력 데이터와 네트워크의 weight에 일부러 노이즈를 집어넣는 방식이다.
-
데이터의 노이즈나 잡음이 모델의 성능에 부정적인 영향을 미치는 것을 방지한다.
Label smoothing

-
훈련 데이터 두개를 뽑아서 섞어주는(Mix-up) 방법이다. 라벨과 이미지 둘 다 섞는다.
-
모델이 훈련 데이터에 과도하게 적합되는 것을 방지하기 위해 정확한 레이블 대신 소프트한 타겟 분포를 사용하는 기법이다.
-
모델이 너무 확신을 가지지 않게해서 일반화 성능을 향상시킬 수 있다.
실제로 분류문제에서 데이터셋이 한정적일 때 성능 향상에 큰 도움이 된다.
Dropout
-
훈련 중에 랜덤하게 일부 뉴런을 비활성화시키는 기법으로 network의 일부 weight를 0으로 만든다.
-
모델이 특정 뉴런에 너무 의존하지 않고 다양한 특징을 학습할 수 있도록 돕는다.
Batch normalization
-
훈련 중에 각 레이어의 입력을 정규화하는 기법
-
모델의 안정성을 향상시키고 학습 속도를 가속화하는데 도움을 준다.
-
일반적인 분류문제에서 성능향상에 도움을 주긴 하지만, 논문의 성능에 대해서 논란이 다소 있다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
