Today I Learned
오늘 공부한 내용은 CNN이후 발전된 CNN들에 대해 공부했다.
Modern CNN
-
Network를 깊게 쌓으면서 parameter 숫자를 줄이는 것이 관건.
적은 parameter로 동일한 output을 내면 일반화 성능이 올라간다. -
1x1 convolution fillter로 채널을 줄이고 파라미터를 줄이는 것이 주요 아이디어다.
AlexNet
-
8-layers에 60mil 파라미터
-
11x11x3의 필터. 5개의 convolutional 레이어. 3개의 Fully Connected 레이어.
-
ReLU 활성화함수를 사용
-
2개의 GPU를 사용해 병렬로 학습
-
Dropout을 적용하여 Overfitting을 방지. 드롭아웃은 학습 중에 랜덤하게 뉴런을 꺼서 모델이 특정 뉴런에 과도하게 의존하는 것을 막는 기법.
-
Data Augmentation 기법을 사용하여 학습 데이터의 다양성을 높임
VGGNet
-
19(or 16)-layers에 110mil 파라미터
-
Convolutional Layer에서 3x3 필터를 사용해서 depth를 늘림
작은 필터 크기는 네트워크의 파라미터 수를 줄이고, 비선형성을 증가시킨다.
ex) 5x5 필터 하나면 409k개 파라미터인데 3x3 필터 2번을 쓰면 295k개로 오히려 더 적음 -
dropout 사용
GoogLeNet
- 22-layers에 4mil 파라미터. alexnet에 비해 층은 3배정도 늘었지만 파라미터는 10배 이상 줄었다.
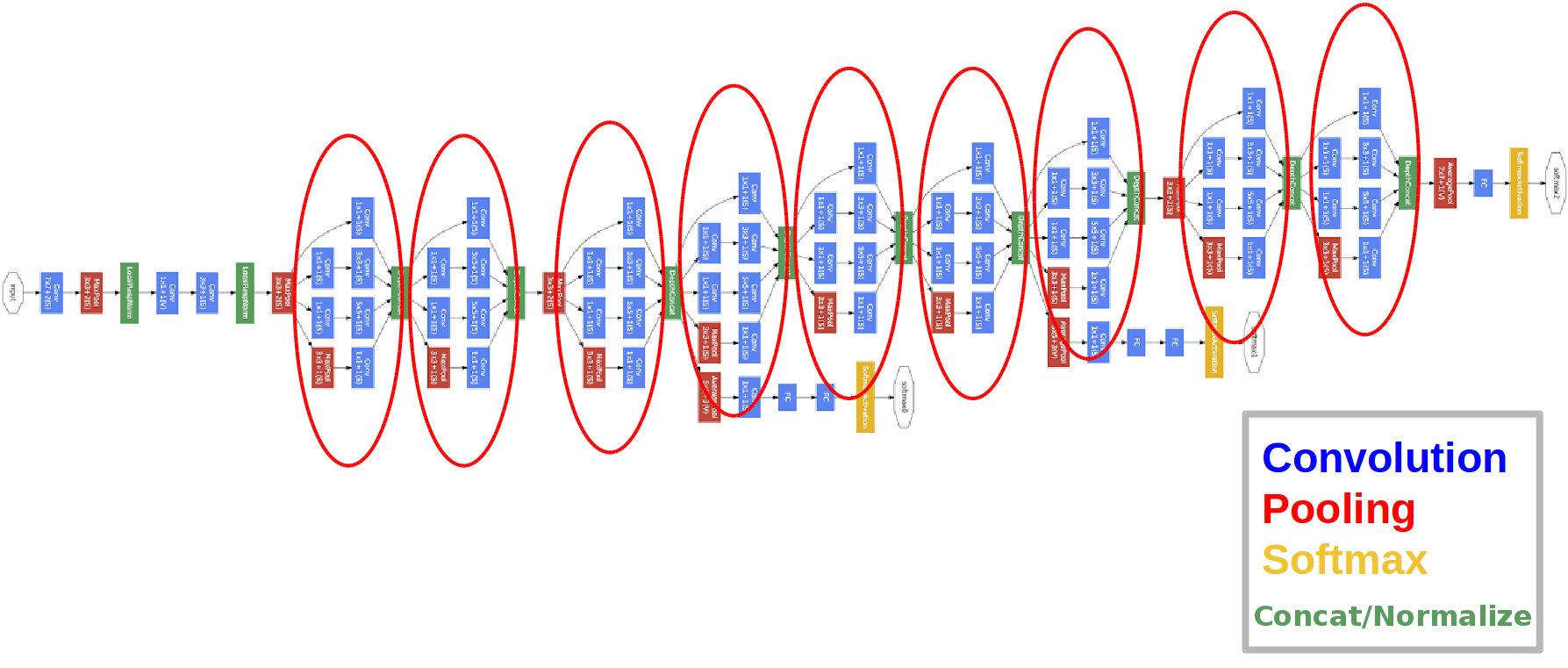
- NiN(Network-in-Network) 네트워크 안에 네트워크가 반복되는 구조를 만듬.
-
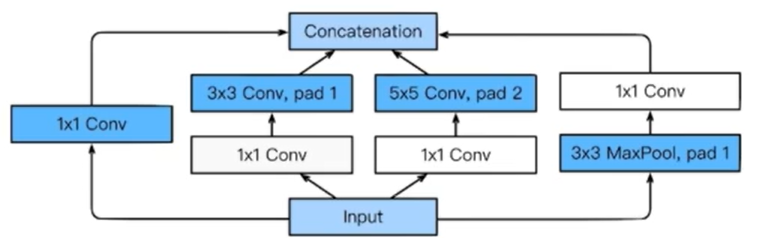
Inception block
1개의 입력에 대해 여러 filter를 거침.
1x1 Convolution에 넣어 channel을 줄였다가, 3x3나 5x5 Conv를 거치게해 다시 확장하는 방식
결과적으로 채널 수를 줄여 파라미터를 줄임 -
1x1 Convolution
special dimmension은 그대로 가고 channel을 줄여서 파라미터를 줄인다.
128 -> 128 : 147k개
128 -> 32(1x1 Conv) -> 128 : 4k+36k = 40k
ResNet
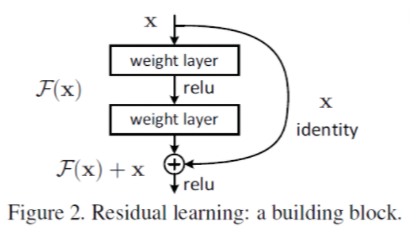
-
네트워크(layer)가 깊어지면 파라미터 수가 늘어 trainning error가 더 발생해 학습이 오히려 잘 안되는 문제가 발생하는데, 이를 해결해주어 레이어를 더 깊게 쌓을 수 있게 해준 논문이다.
-
잔차 학습(Residual Learning)으로 입력 데이터와 출력 데이터 간의 잔차를 학습하는 데 중점을 둔다. 레이어를 건너뛰는(shortcut) 경로를 학습하여 네트워크의 깊이를 증가시키면서 학습 능력을 향상시킨다.
DenseNet
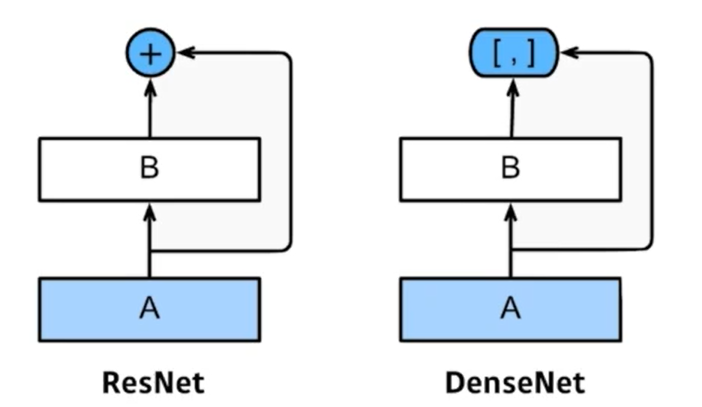
- ResNet은 나온 값을 더하는것(f(x) + x)이라면 DenseNet은 두 값을 따로 쌓아서 관리(concatenation)한다. 이러면 채널이 계속 늘어날 수 있는데 1x1 conv를 활용해서 dimmension을 줄인다.
본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다.
