Today I Learned
3주차 마지막날! 오늘은 Seaborn 라이브러리 코드를 정리해보았다.
강의 복습
Seaborn
통계 관련 정보시각화를 제공하는 Python 시각화 라이브러리
EDA 과정에서 정적인 결과물을 만들기 유용하다.
- 주요 plot 함수
| 함수 | 설명 |
|---|---|
histplot() | 히스토그램을 그려 데이터의 분포를 시각화. |
kdeplot() | KDE를 사용해 데이터의 분포를 부드러운 곡선으로 시각화. |
rugplot() | 데이터 포인트를 축에 작은 선으로 표시. |
ecdfplot() | 누적 분포 함수(CDF)를 시각화. |
boxplot() | 박스플롯으로 데이터의 분포와 이상치 시각화. |
violinplot() | 박스플롯과 KDE를 결합해 데이터의 분포를 시각화. |
stripplot() | 데이터 포인트를 점으로 나열해 범주형 데이터 시각화. |
swarmplot() | 점이 겹치지 않게 배치하여 범주형 데이터 시각화. |
countplot() | 범주형 데이터의 개수를 막대그래프로 시각화. |
pointplot() | 범주형 데이터의 평균과 신뢰 구간을 점으로 시각화. |
barplot() | 범주형 데이터의 평균과 신뢰 구간을 막대그래프로 시각화. |
scatterplot() | 두 변수 간의 관계를 점으로 시각화. |
lineplot() | 두 변수 간의 관계를 선으로 시각화. |
relplot() | scatterplot과 lineplot의 범용 인터페이스. |
pairplot() | 여러 변수 간의 쌍 관계를 한꺼번에 시각화. |
regplot() | 회귀선을 포함한 산점도를 시각화. |
lmplot() | 회귀선과 다양한 조건에 따른 플롯을 시각화. |
residplot() | 회귀 분석의 잔차를 시각화. |
heatmap() | 2차원 데이터(매트릭스)를 색상으로 시각화. |
clustermap() | 클러스터링된 데이터 매트릭스를 색상으로 시각화. |
Countplot
pandas의 value_counts()를 이용하면 데이터 값들의 빈도 정보를 볼 수 있지만, countplot을 사용하면 barplot으로 빠르게 시각화 해준다. x대신 y를 사용하면 horizontal로 가능
sns.countplot(x='sex', data=데이터, order=sorted(데이터['sex'].unique))-
hue='gender', palette='Set1' 처럼 hue와 palette로 색 지정을 할 수 있다.
-
matplotlib과 사용할 때는 ax=axes[0] 처럼 파라미터에 ax를 지정해주면 subplot으로 넣을 수 있다.
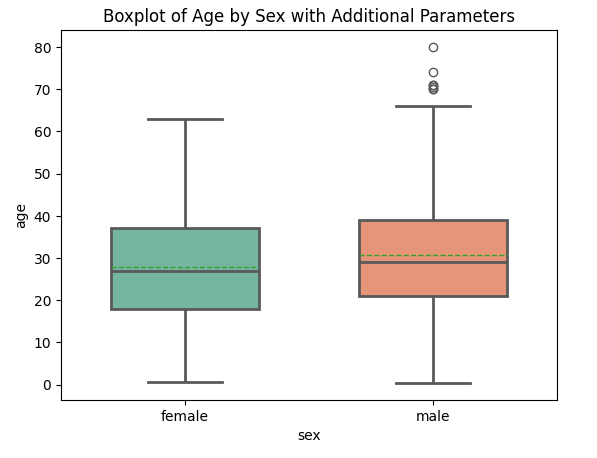
box plot
데이터 분포를 시각화해준다. 중앙, 사분위수, 최대, 최소값을 직관적으로 보여준다.
-
box는 Q1~Q3의 범위고 상자 안의 선은 Q2(중간값)이다.
-
수염은 Q1과 Q3 기준으로 1.5 * IQR값을 나타낸다. 이 범위를 초과하면 outlier로 본다.
import seaborn as sns
import matplotlib.pyplot as plt
# 타이타닉 데이터셋 로드
titanic = sns.load_dataset('titanic')
# 성별에 따른 나이 분포 박스플롯
sns.boxplot(x='sex', y='age', data=titanic,
palette='Set2', # 팔레트 색상 설정
order=['female', 'male'], # x축 순서 지정
showmeans=True, # 평균값 표시
meanline=True, # 평균값을 선으로 표시
width=0.6, # 박스의 너비 설정
linewidth=2) # 박스 선의 두께 설정
# 제목 설정
plt.title('Boxplot of Age by Sex with Additional Parameters')
# 그래프 표시
plt.show()
violinplot
sns.violinplot()
boxplot에서 분포까지 보여주는 plot
-
연속적이지 않은 데이터를 연속적으로 보여줘서 오차가 발생한다.
-
분포만 빠르게 볼때는 사용가능하지만 히스토그램 같은걸로 보는게 더 낫다.
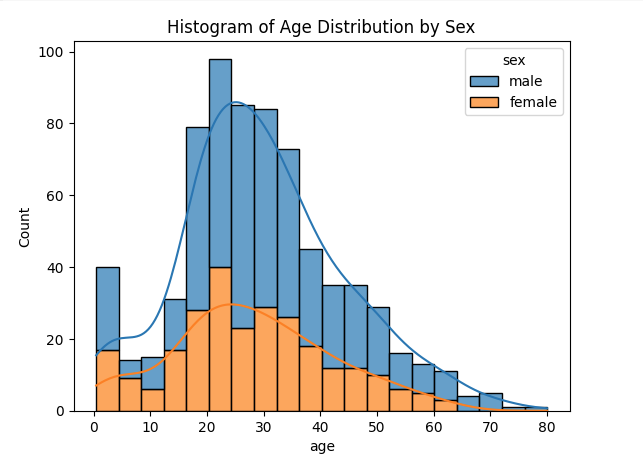
histplot
sns.histplot() 히스토그램을 시각화
- multiple='stack'으로 쌓아서 표현한 histplot 예시
multiple은 layer, dodge, stack, fill을 사용할 수 있다.
import seaborn as sns
import matplotlib.pyplot as plt
# 타이타닉 데이터셋 로드
titanic = sns.load_dataset('titanic')
# 나이 분포를 히스토그램으로 시각화
sns.histplot(data=titanic,
x='age', # x축 변수 설정
bins=20, # 빈(bin) 수 설정
kde=True, # KDE 커널 밀도 추정선 추가
color='skyblue', # 히스토그램 색상 설정
edgecolor='black', # 각 빈의 테두리 색상 설정
hue='sex', # 성별에 따른 색상 구분
multiple='stack', # 겹치지 않고 쌓아서 표현
alpha=0.7) # 투명도 설정
# 그래프 제목 설정
plt.title('Histogram of Age Distribution by Sex')
# 그래프 출력
plt.show()
- kdeplot은 연속확률밀도를 보여준다. 겹쳐서 보더라도 잘 보인다.
joint plot
두 변수간 관계와 각 변수의 분포를 같이 보여주는 plot
import seaborn as sns
import matplotlib.pyplot as plt
# 타이타닉 데이터셋 로드
titanic = sns.load_dataset('titanic')
# 성별에 따라 나이와 요금 간의 관계를 시각화
sns.jointplot(x='age', y='fare', data=titanic, hue='sex', kind='scatter', palette='Set1')
# 그래프 제목 설정
plt.suptitle('Jointplot of Age and Fare by Gender', y=1.02)
# 그래프 출력
plt.show()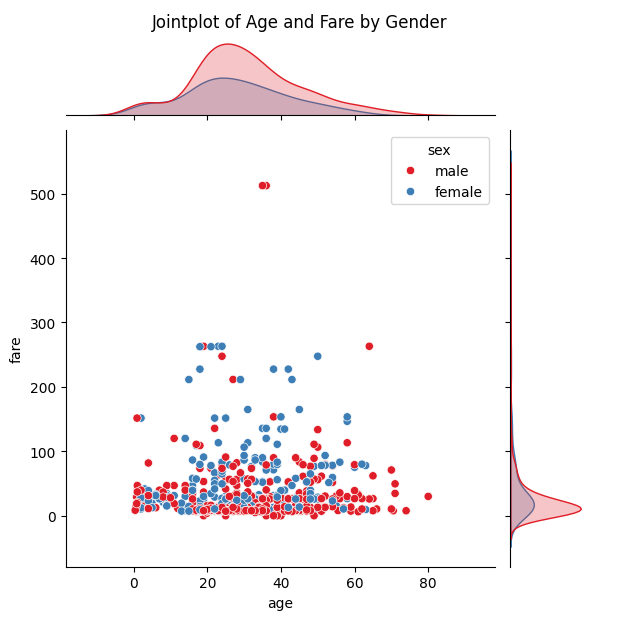
- kind: 플롯의 종류를 지정한다.
('scatter', 'hist', 'kde', 'reg', 'hex', 'resid')
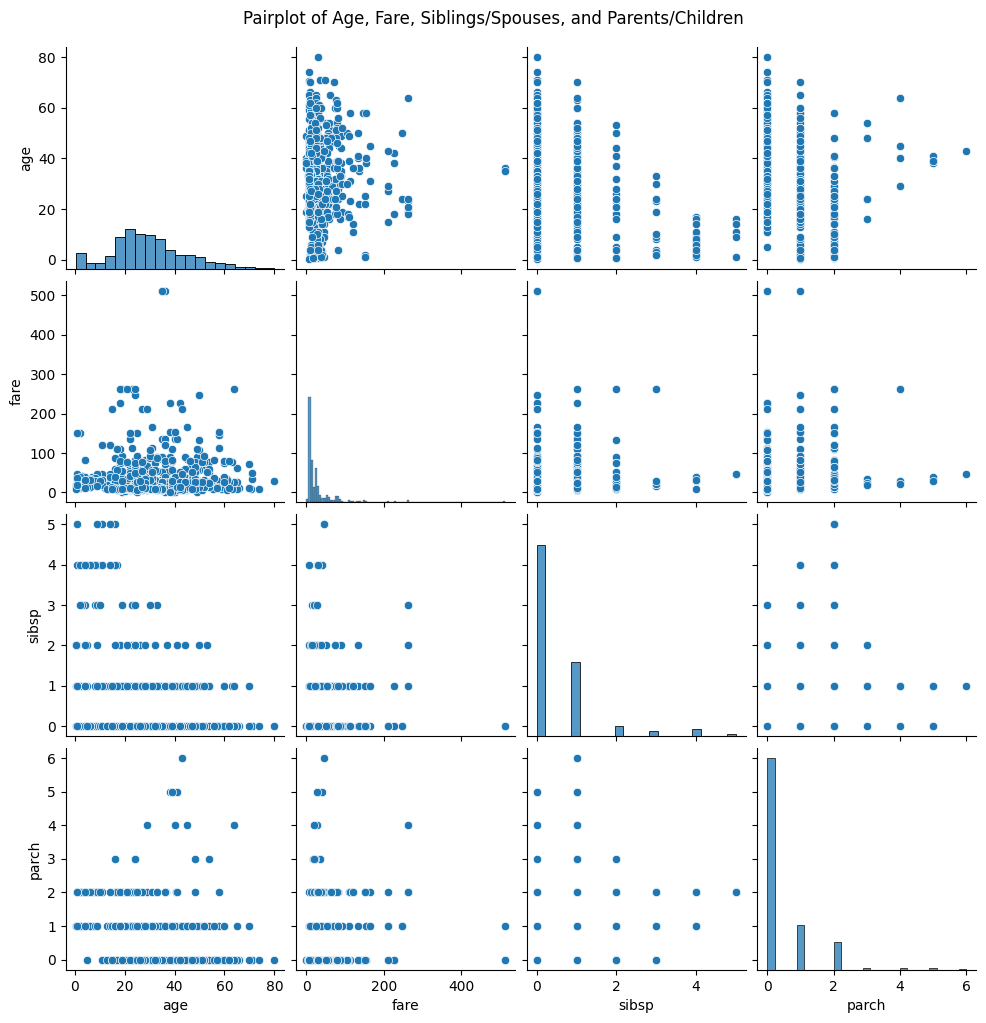
pari plot
sns.pariplot() 여러 변수간 쌍 관계를 시각화할 때 사용
import seaborn as sns
import matplotlib.pyplot as plt
# 타이타닉 데이터셋 로드
titanic = sns.load_dataset('titanic')
# 'age', 'fare', 'sibsp', 'parch' 변수를 사용하여 pairplot 생성
sns.pairplot(titanic[['age', 'fare', 'sibsp', 'parch']].dropna())
# 그래프 제목 설정
plt.suptitle('Pairplot of Age, Fare, Siblings/Spouses, and Parents/Children', y=1.02)
# 그래프 출력
plt.show()
Facet Grid
데이터의 하위 집합을 사용해 여러 플롯을 배열해 시각화할 때 유용한 클래스
- FacetGrid 객체 생성 후 map()으로 플롯을 그린다.
import seaborn as sns
import matplotlib.pyplot as plt
# 타이타닉 데이터셋 로드
titanic = sns.load_dataset('titanic')
# FacetGrid 생성: 'sex'에 따라 행을 구분하고 'class'에 따라 열을 구분
g = sns.FacetGrid(titanic, col='class', row='sex', margin_titles=True)
# 각 서브플롯에 산점도 플롯 추가
g.map(sns.scatterplot, 'age', 'fare')
# 플롯 제목 설정
g.set_axis_labels('Age', 'Fare')
g.set_titles(col_template="{col_name} Class", row_template="{row_name} Gender")
plt.show()
-
catplot(Categorical)
범주형 데이터를 변수에 따라 데이터를 나눠서 다양한 플롯을 생성할 수 있다. -
displot(Distribution)
연속형 데이터의 분포를 시각화하는 데 사용된다. -
relplot(Relational)
두 변수간의 관계를 주로 산점도와 line으로 시각화하는 함수 -
lmplot(Regression)
두 변수간의 관계를 선형회귀선과 함께 시각화하는 함수
차원 축소
-
from sklearn.preprocessing import StandardScaler를 이용해 정규화를 진행하고,
from sklearn.decomposition import PCA를 이용해 차원 축소를 진행한다. -
pca = PCA(n_components=2) 를 사용하면 2차원으로 축소된다.
클러스터링
-
from sklearn.cluster import KMeans를 이용해서 클러스터링을 한다.
-
kmeans = KMeans(n_clusters=3, random_state=42)
n_clusters 파라미터로 클러스터 수를 지정해서 진행한다.
피어세션
-
All You Need Is Attention 논문을 각자 읽어 와서 논문에 대해서 얘기했다.
-
동빈나님 github의 논문 코드를 보면서 실제로 코드상에서 어떻게 구현되는지 확인했다.
멘토링
-
선형대수 내용
내적, 외적
벡터 - 단위벡터
행렬 - 항등행렬, 전치행렬, 역행렬, 직교행렬
선형관계, 선형변환?
(중요) 고유벡터, 고유값
SVD(특이값 분해)
PCA - 차원축소기법 -
포트폴리오
포트폴리오
프로젝트 + 스터디
수치적개선율 + 약간의 디테일한 설명 + 서비스 실제 화면
단 너무 세밀하게 있으면 별로 -> 이미지 개괄?
제목 + 개요(1줄) + 본인역할(+기여도) + 결과
포트폴리오를 기반으로 질문하기때문에 유도성 내용 적는게 좋다
