Today I Learned
연휴동안 못나간 진도를 마저 나갔다.
데이터셋 분할
훈련 / 검증 / 테스트 데이터
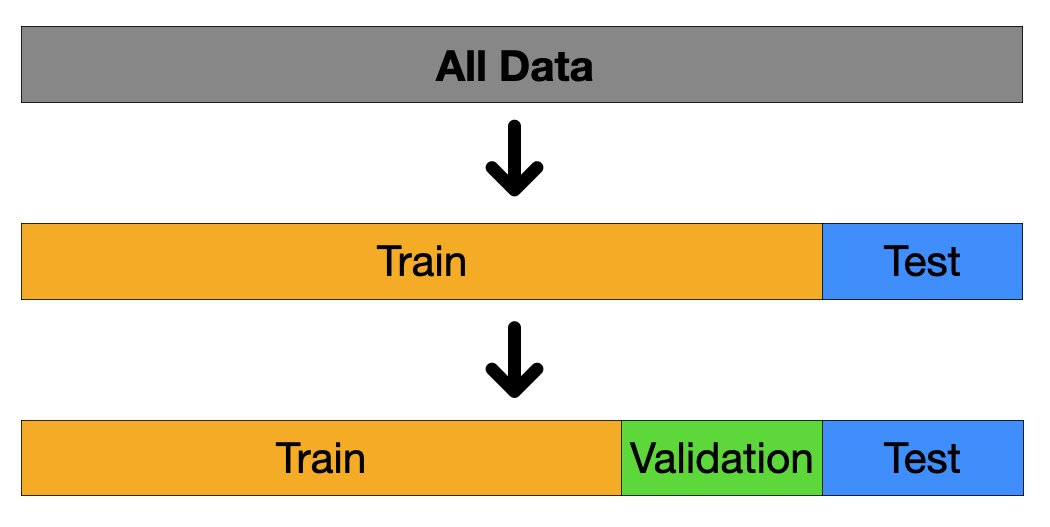 이미지 출처 : pozalabs
이미지 출처 : pozalabs
-
훈련(Training) 데이터
모델을 학습시킬때 사용하는 데이터. 정답(label)이 있으므로 주로 과거 데이터 -
검증(validation) 데이터
모델의 하이퍼파라미터 튜닝이나 성능 평가에 사용되는 데이터
모델이 훈련 데이터에 overfitting되는 것을 막고 일반화 성능을 평가한다. -
테스트(Test) 데이터
모델의 최종 성능을 평가할 때 사용하는 데이터. 현재나 미래시점의 데이터
Sklearn 으로 데이터 분할
- train_test_split() 함수 이용해 분할
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
# random_state : 난수 시드값.
# shuffle : 분할 전 데이터 섞을지 여부. 기본값은 True
# stratify : 데이터 분할 시 클래스(카테고리) 비율을 동일하게 유지해 원본 데이터의 클래스 분포를 반영
- train, validation, test 3가지 데이터로 나누는 방법
from sklearn.model_selection import train_test_split
import numpy as np
# 예시 데이터 생성
X = np.arange(20).reshape((10, 2)) # 입력 데이터
y = np.array([0, 1, 0, 1, 0, 1, 0, 1, 0, 1]) # 타겟 데이터
# Step 1: train과 (validation + test)로 나누기
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.4, random_state=42)
# Step 2: (validation + test) 데이터를 validation과 test로 나누기
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
- 분류문제에선 무작위로 섞기 때문에 레이블 분포가 불균형이 발생할 수 있다. 이를 방지하기 위해 함수의 파라미터에서
stratify=y옵션을 넣어야한다. 여기서 y는 분류문제에서 y값 즉 정답label 데이터셋 변수를 넣어야한다. 회귀에서는 구간화(bining)를 해서 넣으면 된다.
데이터 불균형
-
현실 데이터에서는 특정 클래스가 다른 클래스보다 훨씬 많은 데이터 불균형이 존재한다.
-
따라서 데이터 불균형은 모델이 편향될 수 있고, 평가지표가 왜곡되어 정확도(accuracy)가 의미가 없을 때가 있고, 일반화 성능이 떨어질 수 있다.
-
언더샘플링 : 적은 클래스 수에 많은 클래스를 맞춰 샘플링한다.(큰걸 버린다)
랜덤, tomek links, CNN 등이 있다.
오버샘플링 : 많은 클래스 수에 적은 클래스를 맞춰 샘플링한다.(작은걸 늘린다)
SMOTE, 랜덤, ADASYN, Resampling 등의 방법이 있다. -
imblearn
불균형 데이터셋을 다루는 파이썬 라이브러리
언더샘플링, 오버샘플링, 복합 샘플링이 가능.
scikit-learn과 유사한 API를 제공하여 사용이 쉽다.
데이터 유출
-
훈련 단계에서 사용하면 안되는 검증, 테스트 정보를 사용해서 훈련할 때 발생
-
이벤트 이후 정보를 포함하거나, 타겟변수의 대리변수를 포함하거나, 데이터셋을 나누기 전에 전처리를 해서 훈련에 포함되는 경우 등이 있다.
모델 학습
- 모델 학습 과정
데이터 수집 -> 전처리 -> 모델 학습 -> 모델 평가 -> 모델 배포
Boosting
 이미지 출처 : medium.com/@brijesh_soni
이미지 출처 : medium.com/@brijesh_soni
- 앙상블 머신 러닝기법 중 하나로 여러 개의 약한 학습기(weak learner)를 순차적으로 학습시켜 강한 학습기(strong learner)를 만드는 방법이다. 이전 단계의 오차를 줄이기 위해 잘못 분류된 데이터에 가중치를 높여 반복해 학습을 진행하는 것
AdaBoost(Adaptive Boosting)
첫 모델 학습 후 잘못 예측된 샘플에 큰 가중치를 부여해 다음에는 이걸 고려해 학습
-
첫 모델엔 모든 데이터 샘플에대해 동일한 가중치 1/n을 부여한다.
-
이후 잘못 예측한 샘플에 더 큰 가중치를 부여해 다음 데이터 셋에 더 많이 포함되게한다.
-
최종 예측은 각 weak learner의 예측 결과에 가중치를 부여해 가중 평균을 낸다.
-
sklearn.ensemble의 AdaBoostClassifier를 사용해 구현한다.
n_estimators는 생성할 약한 학습기(결정 스탬프)의 수로 기본값은 50.
learning_rate는 각 분류기의 기여도를 조절하는 학습률로 기본값은 1.0.
random_state는 난수 생성을 위한 시드 값
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# AdaBoost 모델 생성
adaboost = AdaBoostClassifier(n_estimators=50, random_state=42)
# 모델 학습
adaboost.fit(X_train, y_train)
# 예측
y_pred = adaboost.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 새로운 데이터에 대한 예측
new_data = [[5.1, 3.5, 1.4, 0.2]] # 예시 데이터
prediction = adaboost.predict(new_data)
print(f"Prediction for new data: {iris.target_names[prediction[0]]}")Gradient Boosting
첫 모델 학습 후 그 모델의 잔여 오차(실제-예측)를 학습하고 다음에는 이를 줄이기 위해 학습
-
최초 예측값은 종속변수의 평균값(상수값)으로 예측하고 이 값과 모든 샘플의 잔여오차(residual errors)를 계산해 이를 예측하는 모델을 만들어 데이터를 학습한다.
-
다음 모델은 예측값에 이전 모델의 잔여오차를 더해 계산하는데, 그대로 하면 과적합위험이 있으니 이전의 잔여오차에 learning rate를 곱해준다.
-
sklearn.ensemble의 GradientBoostingClassifier를 사용해 구현한다.
n_estimators는 부스팅 단계의 수로 기본값 100.
learning_rate는 각 트리의 기여도로 기본값은 1.0.
max_depth는 각 트리의 최대 깊이로 기본값 3.
random_state는 난수 생성을 위한 시드 값
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Gradient Boosting 모델 생성
gb_classifier = GradientBoostingClassifier(n_estimators=50, learning_rate=1.0, max_depth=1, random_state=42)
# 모델 학습
gb_classifier.fit(X_train, y_train)
# 예측
y_pred = gb_classifier.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 새로운 데이터에 대한 예측
new_data = [[5.1, 3.5, 1.4, 0.2]] # 예시 데이터
prediction = gb_classifier.predict(new_data)
print(f"Prediction for new data: {iris.target_names[prediction[0]]}")XGBoost
Gradient Boosting을 개선해 속도와 성능을 향상시킨 알고리즘
- level-wise Tree Growth를 사용해 균형잡히고 얕은 트리를 만들어 과적합이 적다.
LightGBM
XGBoost보다 더 빠른 학습과 메모리 효율성을 제공하는 알고리즘
-
균형적이진 않지만 필요할 때 분기를 하는 Leaf-wise Tree Growth 방식을 사용한다.
이 방식은 트리의 깊이와 균형에 상관없이 현재 손실을 가장 많이 줄이는 leaf를 확장한다. -
손실함수가 다양해서 회귀, 분류 등 다양한 문제에 대응가능하다.
-
GOSS : gradient가 작으면 이미 해당 데이터는 잘 학습되었다고 가정해 gradient 크기를 가중치로 선택한다. 큰 gradient를 가진 인스턴스를 선택적으로 유지하여 메모리 사용량과 학습 시간을 최적화.
-
EFB : 서로 연관이 적은 feature를 bundle로 묶는 특성 단위 샘플링을 관리하여 효율성을 높인다.
-
연속형 히스토그램 기반 데이터 분할과 학습을 진행한다.
-
lightgbm의 LGBMClassifier를 사용해 구현한다.
from lightgbm import LGBMClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# LGBMClassifier 모델 생성
lgbm_classifier = LGBMClassifier(
n_estimators=50,
learning_rate=1.0,
max_depth=1,
random_state=42
)
# 모델 학습
lgbm_classifier.fit(X_train, y_train)
# 예측
y_pred = lgbm_classifier.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 새로운 데이터에 대한 예측
new_data = [[5.1, 3.5, 1.4, 0.2]] # 예시 데이터
prediction = lgbm_classifier.predict(new_data)
print(f"Prediction for new data: {iris.target_names[prediction[0]]}")