Today I Learned
긴 연휴를 거치고 다시 프로젝트 시작!
강의 복습
모델 평가
- 성능 측정(정확성, 일관성, 신뢰도)
- overfitting, underfitting 예방
- 최적 모델 선택
- Business 목표 달성 평가
혼동행렬(confusion matrix)
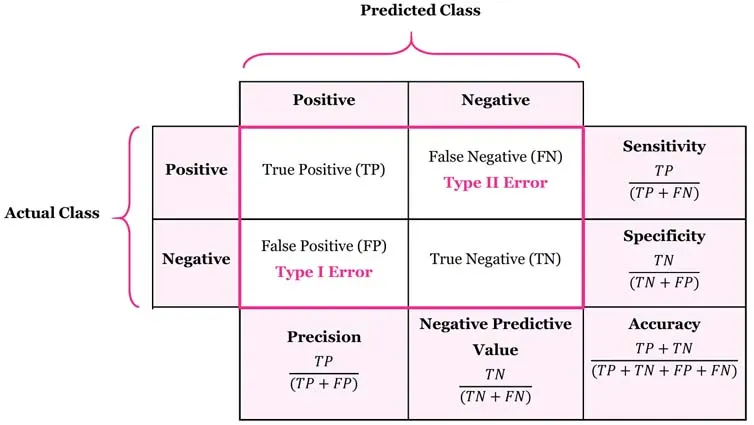 이미지 출처 : manisha-sirsat
이미지 출처 : manisha-sirsat
- 단순 TF가 아니라 클래스가 여러개면 NxN형태로 쓸 수 있다.
평가지표
정확도(Accuracy): (TP + TN) / (TP + TN + FP + FN) 전체에서 올바른 예측 비율
정밀도(Precision): TP / (TP + FP) 예측 클래스의 실제 클래스 비율
재현율(Recall, Sensitivity): TP / (TP + FN) 실제 클래스에 대해 올바른 예측 클래스 비율
F1 점수: 정밀도와 재현율의 조화평균
혼동행렬 시각화 코드
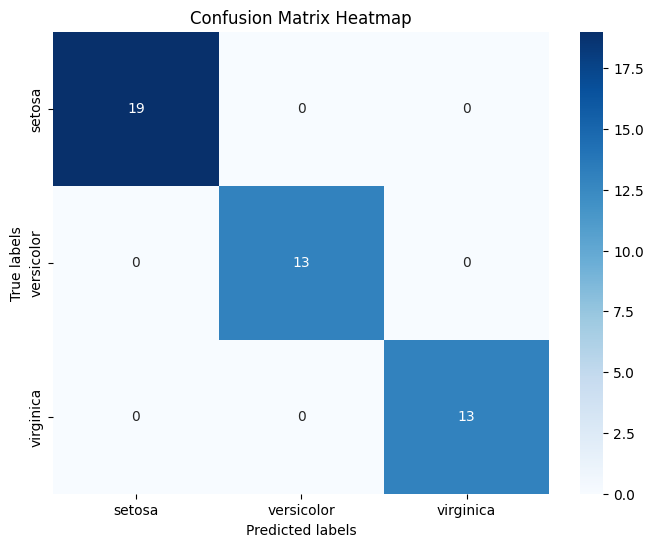
- sklearn.metrics의 confusion_matrix 사용
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
# 데이터 로드
data = load_iris()
X, y = data.data, data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 모델 훈련
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 혼동행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 혼동행렬 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=data.target_names,
yticklabels=data.target_names)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix Heatmap')
plt.show()모델 과적합
training 데이터를 너무 과하게 학습해 검증이나 테스트데이터에는 성능이 떨어지는 것
-
학습 loss 그래프를 보면 train loss는 감소하는데 validation loss는 안떨어지는 경우
데이터마다 차이는 있지만 train accuracy와 test accuracy가 0.1 이상 차이나면 과적합, 과소적합 의심해봐야 -
과적합 방지방법에는 정규화, 교차검증, dropout, early stopping 등이 있다.
정규화
-
가중치의 값이 극단적으로 커지면 과적합이 되기도 하는데 이를 막기 위해 손실함수에 페널티항을 추가하는 것을 정규화라 한다.
-
L1 정규화 (Lasso)
from sklearn.linear_model import Lasso
가중치 절대값의 합을 최소화하는 방식으로 일부 가중치를 딱 0으로 만들어 특성 선택 효과를 만든다. L2보다 더 강도가 강하다. -
L2 정규화 (Ridge)
from sklearn.linear_model import Ridge
가중치 제곱합을 최소화하는 방식으로 모든 가중치를 작게 만들어 모델의 복잡도를 줄인다.
교차검증(Cross-Validation)
데이터셋을 여러 부분집합으로 나눠 모델의 성능을 평가하는 방법
-
데이터셋을 여러 폴드로 나눠 각 폴드가 한번씩 테스트 set이 되도록 모델을 학습하고 평가한다.
그리고 모든 폴드에 대한 평가결과를 평균해 모델의 성능을 추정한다. -
일반화 능력을 평가할 수 있으며 평가의 신뢰성을 높일 수 있다.
데이터셋이 작을때 더 유용한 방법.(너무 적으면 역효과) -
하지만 분할해서 검증과 테스트를 진행하다보니 시간과 비용이 많이 소모되어 시간복잡도를 항상 고려해서 K값을 정해야한다.
-
K-Fold CV
데이터를 무작위로 동일한 K개의 부분집합으로 나누거 1개는 평가, 나머지 k-1로 훈련 시킨다.
모든 데이터를 훈련, 테스트에 사용해 효율적이지만, 시간이 오래 소모된다.
그리고 클래스 분포가 불균형하면 평가에 문제가생길 수 있다. -
Stratified K-Fold CV
위의 클래스 분포 문제를 해결하기 위해 랜덤이 아니라 전체 데이터의 클래스 분포를 유지하도록 fold를 나눈 방식
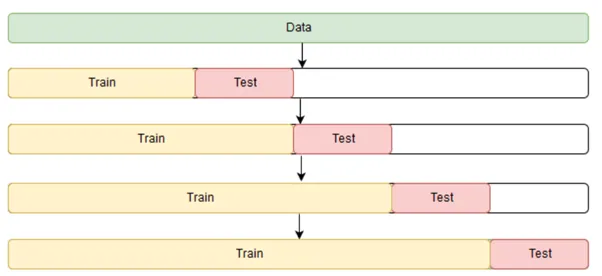 이미지 출처 : medium.com/@soumyachess1496
이미지 출처 : medium.com/@soumyachess1496
- Time series split CV
시계열 분할 교차검증. 시계열데이터의 시간적 순서를 유지해 학습과 테스트를 반복.
피어세션
- 프로젝트 관련해서 EDA와 feature에 대해 토론했다.
회고
- 생각보다 프로젝트 public 점수를 올리기 쉽지 않았다. 상관관계가 있는 feature를 찾으려면 좀 더 고생해야할 것 같다.
