Today I Learned
오늘은 프로젝트 동안 제대로 공부하지 못하고 사용했던 Over-Sampling에 대해 정리해보고자 한다.
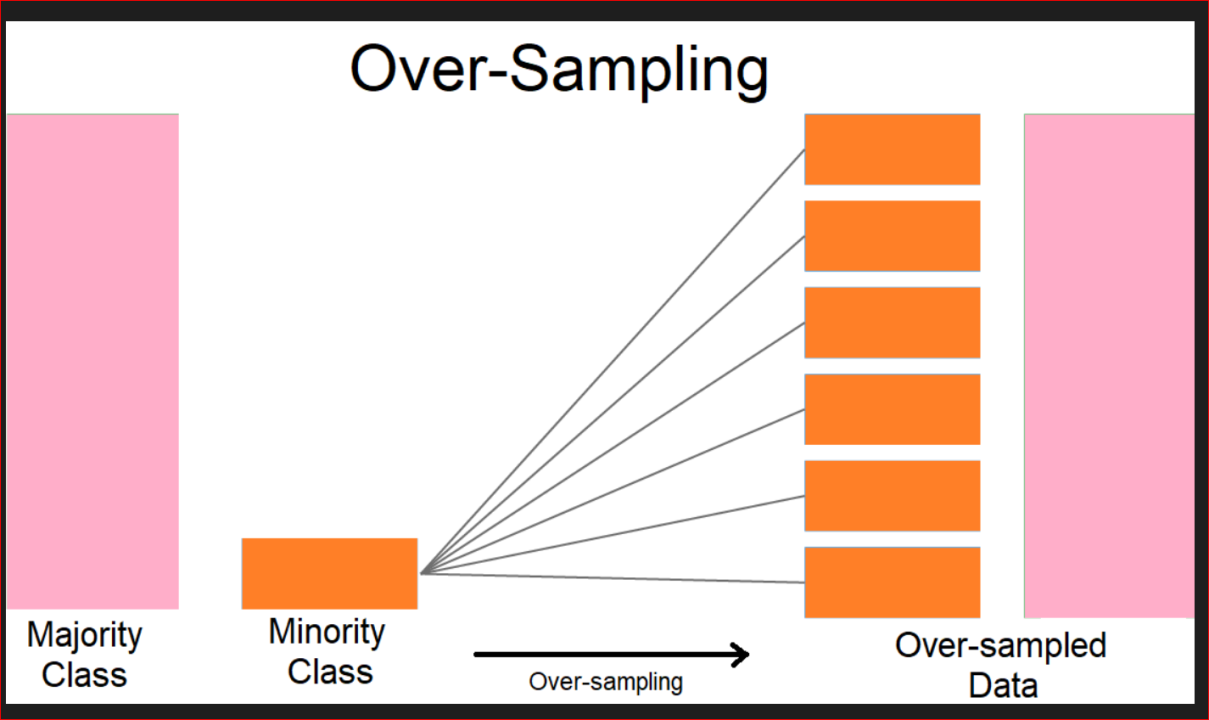
Over-Sampling
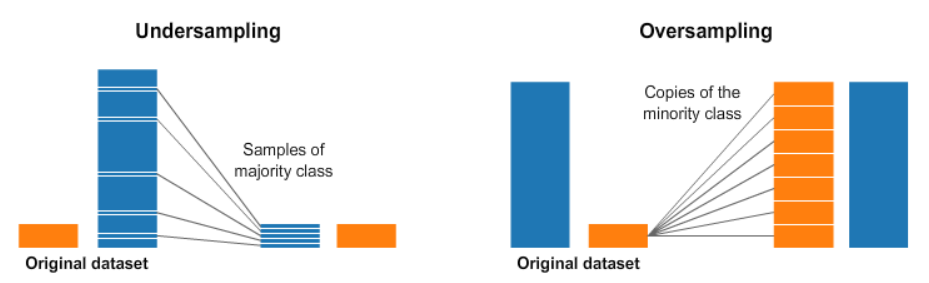 이미지 출처 : kaggle.com/rafjaa
이미지 출처 : kaggle.com/rafjaa
특정 클래스의 샘플 수가 다른 클래스에 비해 현저히 적은 불균형 데이터셋에서 다수 클래스에 편향을 막기 위해 소수 클래스의 샘플을 증가시켜 문제를 해결하는 방법
- 장점
- 데이터 불균형 해소
- 소수 클래스에 대한 모델의 성능 향상
- 기존 데이터를 유지하면서 새로운 정보 추가 가능
- 단점
- 과적합 위험 증가
- 계산 비용 증가
- 인위적 데이터로 인한 노이즈 발생 가능성
- 한 기법만 사용하기보다 여러 기법 사용 후 교차검증 해보는 것도 좋다.
주요 기법
1. Random Over-sampling
소수 클래스에서 무작위로 샘플 복제
-
가장 간단하고 직관적이며 기존 데이터를 그대로 복제해 새로운 정보는 추가하지 않는다.
-
따라서 과적합 위험이 높지만 계산 비용이 낮다.
데이터 셋이 작고 간단하면 이 방법으로도 충분하다.
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X, y)2. SMOTE (Synthetic Minority Over-sampling Technique)
기존 데이터 포인트 간의 보간을 통해 소수 클래스의 샘플들 사이에서 새로운 샘플 생성
- 기존 데이터 특성을 유지하면서 새로운 샘플 생성 가능. 그래서 1에비해 과적합 위험이 낮음.
클래스간 경계가 명확하거나 연속형에 효과적이지만 범주형 특성에는 주의 필요
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)3. ADASYN (Adaptive Synthetic)
SMOTE를 개선한 방법으로 학습하기 어려운 샘플 주변에 더 많은 새 샘플을 생성
-
데이터 분포를 고려해 데이터 생성량을 조절.
클래스간 경계가 복잡한 경우에 효과적이다. -
고차원 데이터에서 노이즈에 민감할 수 있다.
from imblearn.over_sampling import ADASYN
adasyn = ADASYN(random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X, y)
4. Borderline-SMOTE
SMOTE의 변형으로, 클래스 경계 부근의 소수 클래스 샘플에 집중하여 새로운 샘플을 생성
-
소수 클래스의 샘플을 안전, 위험, 노이즈로 분류해서 위험 샘플 주변에 새 샘플을 생성
-
클래스 간 경계를 더 명확하게 만들어 분류 성능 향상에 효과적이다.
-
노이즈에 덜 민감하며, 과적합 위험이 SMOTE보다 낮고, 복잡한 데이터셋에서 성능이 좋다.
(계산 비용은 높다)
from imblearn.over_sampling import BorderlineSMOTE
borderline_smote = BorderlineSMOTE(random_state=42)
X_resampled, y_resampled = borderline_smote.fit_resample(X, y)5. SVM-SMOTE
Support Vector Machine (SVM)의 개념을 활용하여 클래스 경계 부근에 새로운 샘플 생성
-
SVM을 활용해 클래스간 경계를 찾기 때문에 비선형 경계를 가진 데이터셋에 효과적이다.
-
계산 비용이 높은 편이지만, 복잡한 데이터셋에서 좋은 성능을 보인다.
과적합 위험이 있으므로 파라미터 튜닝에 주의가 필요하다.
from imblearn.over_sampling import SVMSMOTE
svm_smote = SVMSMOTE(random_state=42)
X_resampled, y_resampled = svm_smote.fit_resample(X, y)