Today I Learned
오늘 배운 내용은 Embedding과 Retrieval!
Retrieval
Embedding
고차원 데이터를 저차원의 연속적인 벡터 공간으로 변환하는 기법
-
복잡한 데이터를
차원축소해서 더 쉽게 처리하고 분석할 수 있게 해준다.
고차원 데이터의 차원의 저주를 해결해주고 계산 속도를 높이며 일반화 능력도 향상된다. -
임베딩 후,
유사한 의미를 가진 데이터는 거리상 가까워진다.
즉, 데이터간 의미적 유사성을 벡터공간에서 표현할 수 있다. -
단어 임베딩(Word2Vec), 문장/문서 임베딩(BERT), 그래프임베딩(Node2Vec), 이미지 임베딩(주로 CNN)
-
추천시스템(비슷한 케이스끼리 매칭), 텍스트나 이미지 검색, 이상탐지 같은 목적으로 임베딩을 사용할 수 있다.
-
cf. PCA와 t-SNE
둘 다 엄밀히 임베딩이라고는 할 수 없지만 차원축소 기법이다.
PCA는 연속형 데이터를 선형변환해서 차원축소하는 기법이고,
t-SNE 는 복잡한 데이터를 비선형 변환하는 차원축소 기법으로 주로 시각화에 쓰인다.
Retrieval
주어진 입력과 유사한 데이터를 DB에서 검색해오는 것.
-
임베딩 후 의미가 비슷한 벡터는 공간상에서 가까워지는 점을 이용해 검색한다.
-
데이터가 충분히 크고 임베딩 성능이 좋으면 추가 학습 없이도 분류를 수행할 수 있다.
-
임베딩 방법에따라 멀티모달 검색(텍스트, 이미지, 오디오 등)이 가능하다.
ex) 텍스트로 이미지 검색
Distance Metrics
Retrieval에서 거리 측정방법. 기본적으로 거리가 작을수록 유사하다고 판단.
- 두 데이터 포인트 간의 유사성이나 차이를 수치화하는 개념
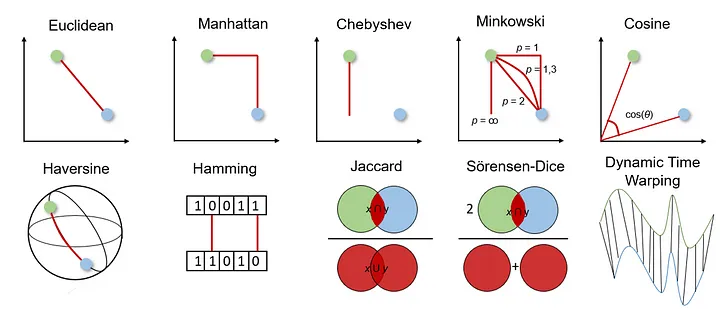 이미지 출처 : medium.com/@jodancker
이미지 출처 : medium.com/@jodancker
-
유클리드 거리
가장 직관적이고 많이 쓰는 방법. 두 점간의 직선거리. 연속형 데이터에 적합
이미지 검색이나 추천시스템에 쓰인다. -
맨해튼 거리
=L1 거리. 두 점간 축방향 거리의 합. 격자구조의 데이터에 적합하고 이상치에 덜 민감.
도시 블록 거리계산이나 텍스트 분류에 쓰인다. -
코사인 유사도
각도만 가진다. -1~1의 값을 가지며 1에 가까울수록 유사하다.
두 벡터간 각도의 코사인 값. 벡터의 크기보다 방향을 중시한다.
텍스트 문서 유사도나 추천시스템에 쓰인다.
딥러닝 Retrieval
1. Arcface
얼굴 인식 분야에서 높은 성능을 보이는 딥러닝 기반의 metric learning(특징 학습) 방법
-
코사인 유사도를 사용한다.
-
CNN으로 얼굴 이미지에서 벡터를 추출하고 이를 L2 정규화한다.
특징 벡터와 가중치 벡터간 각도를 계산하고 마진을 더해 손실 계산을 수행한다. -
같은 클래스끼리는 가까워지고 클래스가 다르면 멀어지도록 학습한다.
이로인해 클래스간 경계가 명확해져 인식 정확도가 높다.
2. CLIP
Contrastive Language-Image Pre-training.
openAI에서 2021년에 발표한 멀티모달 AI 모델.
-
이미지와 텍스트를 동시에 이해하고 처리할 수 있다.
-
이미지와 상관있는 텍스트의 내적은 크게 만들고 상관없는 텍스트의 내적은 작게 만든다.
-
이미지 분류나 이미지 검색 등에 쓰이고 유연하게 시각적 작업에 적용할 수 있다.
-
제로샷 학습: 특정 태스크에 대한 추가 학습 없이 다양한 작업을 수행할 수 있다.
3. DINO
2021년 facebook에서 발표한 자기지도학습 기반의 CV 모델.
-
레이블이 없는 이미지 데이터만 사용해서 학습해 의미있는 특징을 학습한다.
-
이미지 처리에 Transformer 아키텍처를 사용한다.
-
학습된 특징이 자연스럽게 의미 있는 클러스터를 형성한다.
-
이미지 분류, 객체 검출, 세그멘테이션, 특징 추출, 이미지 검색 등에 쓰인다.
Faiss
Facebook AI Research에서 개발한 고성능 유사도 검색 및 군집화 라이브러리
-
유사도 검색과 클러스터링을 위한 라이브러리로 딥러닝 모델에서 생성된 고차원 벡터 데이터를 처리하는 데 최적화되어있다.
-
임베딩 벡터를 효율적으로 저장하고 검색할수 있는 구조를 제공한다.
사용방법
-
이미지나 텍스트를 임베딩벡터로 변환해야하는데, 사전학습된 모델을 활용한다.
(이미지는 DINO, 텍스트는 BERT 같은 모델 사용가능) -
cuda같은 GPU를 사용하는 것이 좋다.
-
사용 코드
import numpy as np
import faiss
# 데이터 생성
dimension = 64 # 벡터의 차원
nb_vectors = 10000 # 데이터셋의 벡터 수
nb_queries = 10 # 쿼리 벡터 수
# 랜덤 데이터셋 생성 (훈련 데이터)
dataset = np.random.random((nb_vectors, dimension)).astype('float32')
# 랜덤 쿼리 벡터 생성
queries = np.random.random((nb_queries, dimension)).astype('float32')
# Flat 인덱스 생성 (가장 기본적인 인덱스 유형)
index = faiss.IndexFlatL2(dimension)
# 데이터셋을 인덱스에 추가
index.add(dataset)
print(f"데이터셋 크기: {index.ntotal}")
# 검색 수행
k = 5 # 각 쿼리에 대해 상위 5개의 가장 가까운 이웃을 찾음
distances, indices = index.search(queries, k)
# 결과 출력
for i in range(nb_queries):
print(f"\n쿼리 {i}의 결과:")
for j in range(k):
print(f" {j+1}번째 가장 가까운 벡터: 인덱스 {indices[i][j]}, 거리 {distances[i][j]}")
# IVF 인덱스 사용 예시 (더 빠른 검색을 위한 인덱스)
nlist = 100 # 벡터 공간을 100개의 셀로 나눔
quantizer = faiss.IndexFlatL2(dimension)
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist, faiss.METRIC_L2)
# IVF 인덱스 학습 및 데이터 추가
index_ivf.train(dataset)
index_ivf.add(dataset)
# IVF 인덱스로 검색 수행
index_ivf.nprobe = 10 # 검색 시 탐색할 셀의 수
distances_ivf, indices_ivf = index_ivf.search(queries, k)
print("\nIVF 인덱스 검색 결과:")
for i in range(nb_queries):
print(f"\n쿼리 {i}의 결과:")
for j in range(k):
print(f" {j+1}번째 가장 가까운 벡터: 인덱스 {indices_ivf[i][j]}, 거리 {distances_ivf[i][j]}")