Today I Learned
오늘은 공원 데이터를 이용해서 클러스터링을 시도해봤다.
클러스터링 실습
parkInfo 전처리
-
latitude, longitude, area의 세 컬럼으로 된 parkInfo는 수도권 이외에 전국 데이터도 담고 있어서 전처리가 필요했다.
-
최 외곽 아파트 위도, 경도 기준 동서남북 + 5Km 정도까지를 limit으로 두고 추렸다.
# df(train+test된 아파트 좌표)에서 latitude와 longtitude의 min, max값 구하기
min_lat = df['latitude'].min()
max_lat = df['latitude'].max()
min_long = df['longitude'].min()
max_long = df['longitude'].max()
print(min_lat, max_lat, min_long, max_long)
# 5km에 해당하는 위도, 경도 변화량 계산
lat_change = 5 / 111 # 위도 1도 = 약 111km
long_change = 5 / 89 # 경도 1도 = 약 89km (한국 위도에서의 근사값)
# 확장된 범위 계산
extended_min_lat = min_lat - lat_change
extended_max_lat = max_lat + lat_change
extended_min_long = min_long - long_change
extended_max_long = max_long + long_change
print(extended_min_lat, extended_max_lat, extended_min_long, extended_max_long)
# park_info에서 확장된 범위 내의 공원만 추출
extracted_park_info = park_info[
park_info['latitude'].between(extended_min_lat, extended_max_lat) &
park_info['longitude'].between(extended_min_long, extended_max_long)
]
print(extracted_park_info.shape)
extracted_park_info.head()k-means(k=5)
- 간단하게 위도 경도로만 k-means를 시도해봤다.
from sklearn.cluster import KMeans
# K-means 클러스터링
kmeans = KMeans(n_clusters=5, random_state=42)
extracted_park_info['cluster'] = kmeans.fit_predict(extracted_park_info[['latitude', 'longitude']])
# 산점도 그리기
plt.figure(figsize=(10, 8))
scatter = plt.scatter(extracted_park_info['longitude'], extracted_park_info['latitude'],
c=extracted_park_info['cluster'], cmap='viridis')
# 범례 추가
plt.colorbar(scatter)
plt.title('K-means Clustering of Parks')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()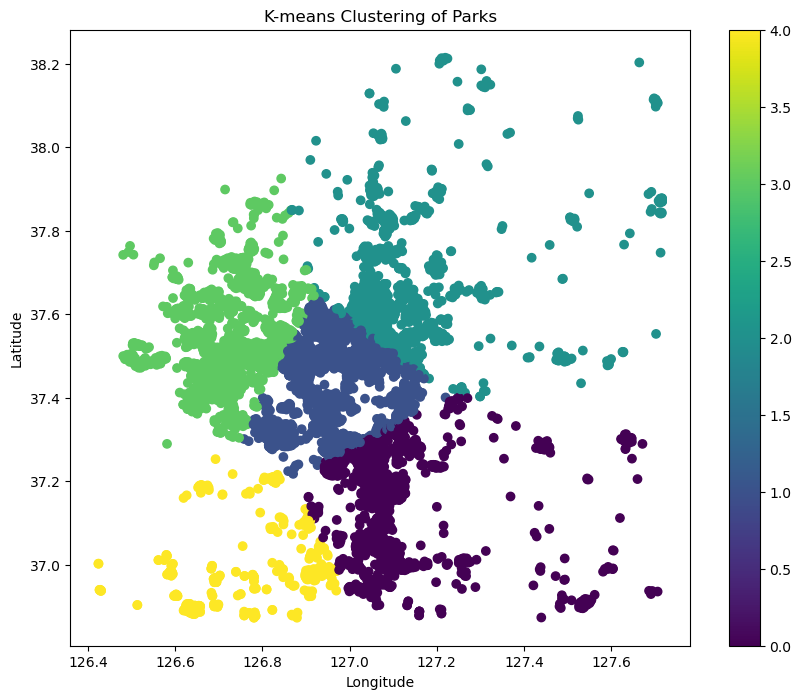
- 깔끔하게 잘리긴한데 이게 큰 의미가 있는지는 모르겠다.
DBSCAN
- DBSCAN을 이용해 클러스터링을 하고, folium으로 html파일로 시각화도 시도해보았다.
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 위도와 경도 데이터 추출
X = extracted_park_info[['latitude', 'longitude']].values
# 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# DBSCAN 클러스터링
dbscan = DBSCAN(eps=0.2, min_samples=10)
extracted_park_info['cluster'] = dbscan.fit_predict(X_scaled)
# 클러스터 수와 노이즈 포인트 수 출력
n_clusters = len(set(extracted_park_info['cluster'])) - (1 if -1 in extracted_park_info['cluster'] else 0)
n_noise = list(extracted_park_info['cluster']).count(-1)
print(f"Number of clusters: {n_clusters}")
print(f"Number of noise points: {n_noise}")
# 지도 시각화
# 지도 중심 좌표 계산
center_lat = extracted_park_info['latitude'].mean()
center_lon = extracted_park_info['longitude'].mean()
# 지도 생성
m = folium.Map(location=[center_lat, center_lon], zoom_start=11)
# 클러스터별 색상 지정 (노이즈 포인트를 위한 색상 포함)
colors = ['red', 'blue', 'green', 'purple', 'orange', 'darkred', 'lightred', 'beige', 'darkblue', 'darkgreen', 'cadetblue', 'darkpurple', 'white', 'pink', 'lightblue', 'lightgreen', 'gray', 'black', 'lightgray']
# 마커 클러스터 생성
marker_cluster = MarkerCluster().add_to(m)
# 각 지하철역을 지도에 추가
for idx, row in extracted_park_info.iterrows():
cluster = int(row['cluster'])
color = 'gray' if cluster == -1 else colors[cluster % len(colors)]
folium.CircleMarker(
location=[row['latitude'], row['longitude']],
radius=5,
popup=f"Cluster: {cluster}, Park Index: {row['park_idx']}",
color=color,
fill=True,
fillColor=color
).add_to(marker_cluster)
# 지도 저장
m.save("park_dbscan_clusters_map.html")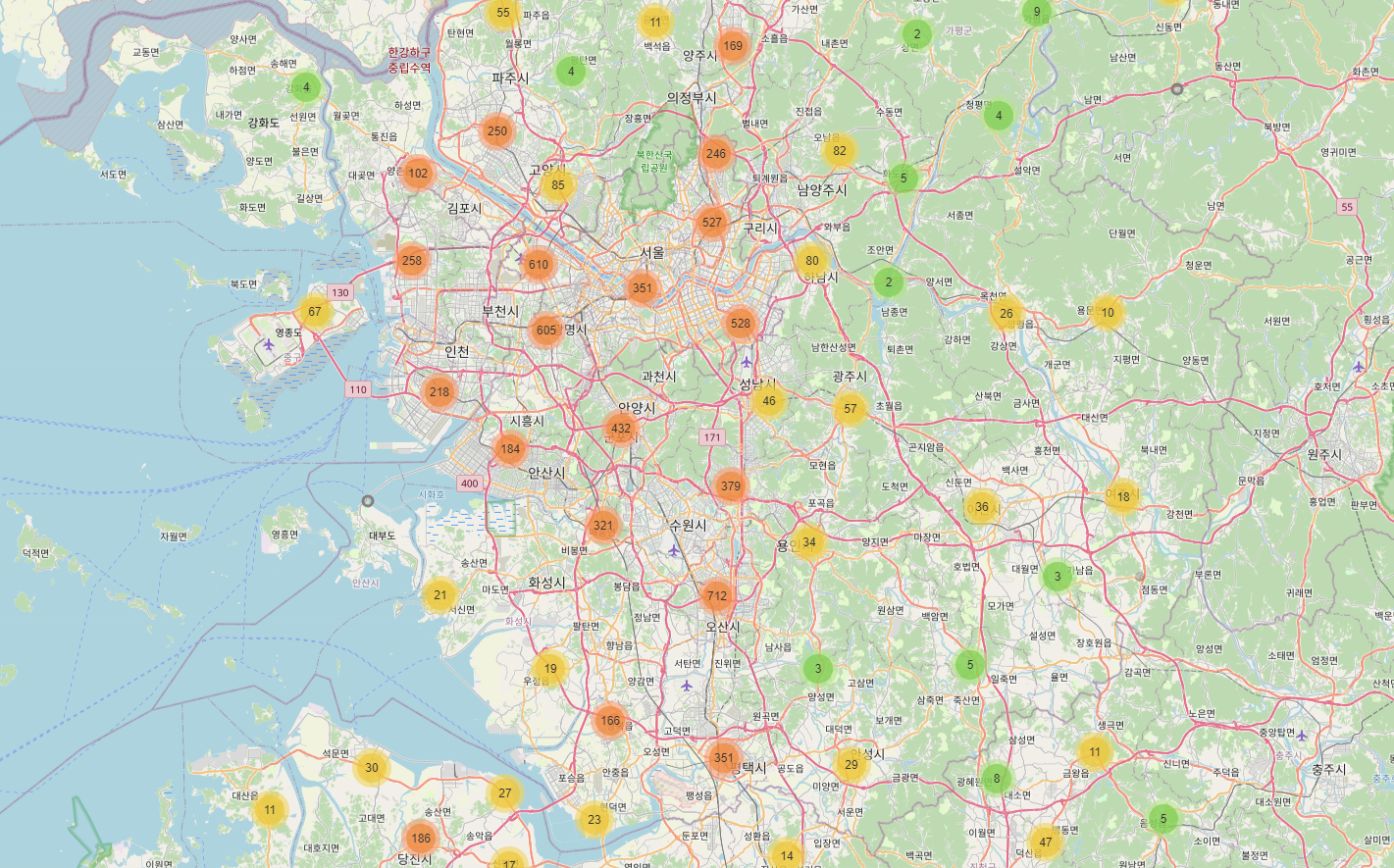
-
지도데이터랑 같이 볼 수 있는 것은 좋았지만, 이것 역시 크게 insight가 보이지는 않았다.
-
DBSCAN에 위도, 경도, 면적까지 세 지표를 넣고 matplotlib으로 3d로도 시각화해서 클러스터링 해봤다.
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# 세 특성 선택
X = extracted_park_info[['latitude', 'longitude', 'area']].values
# 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# DBSCAN 클러스터링
# eps와 min_samples 값은 데이터에 따라 조정이 필요할 수 있습니다
dbscan = DBSCAN(eps=0.5, min_samples=5)
extracted_park_info['cluster'] = dbscan.fit_predict(X_scaled)
# 클러스터 수와 노이즈 포인트 수 출력
n_clusters = len(set(extracted_park_info['cluster'])) - (1 if -1 in extracted_park_info['cluster'] else 0)
n_noise = list(extracted_park_info['cluster']).count(-1)
print(f"Number of clusters: {n_clusters}")
print(f"Number of noise points: {n_noise}")
# 시각화 (3D 산점도)
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 고유한 클러스터 레이블 가져오기
unique_labels = set(extracted_park_info['cluster'])
# 각 클러스터에 대해 다른 색상 사용
for cluster in unique_labels:
cluster_data = extracted_park_info[extracted_park_info['cluster'] == cluster]
if cluster == -1:
# 노이즈 포인트
color = 'gray'
marker = 'x'
else:
color = plt.cm.jet(float(cluster) / max(unique_labels))
marker = 'o'
ax.scatter(cluster_data['longitude'], cluster_data['latitude'], cluster_data['area'],
c=[color], marker=marker, s=50, label=f'Cluster {cluster}')
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
ax.set_zlabel('Area')
ax.set_title('DBSCAN Clustering of Parks (3D)')
plt.legend()
plt.show()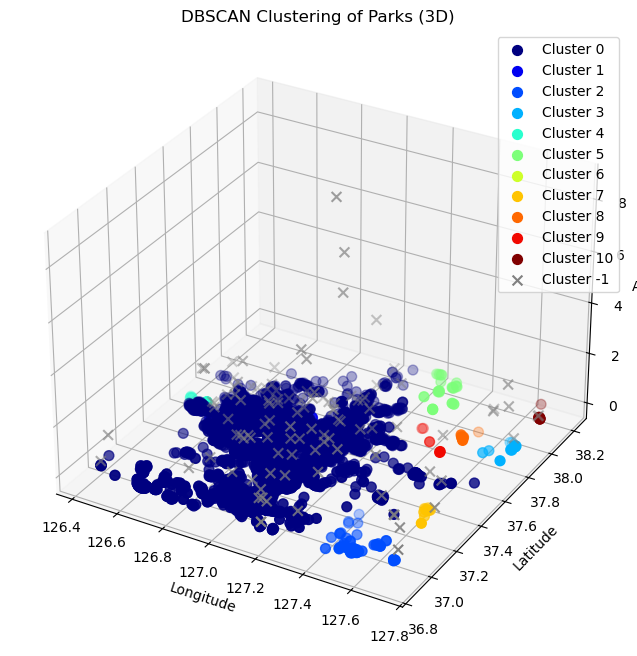
- 오히려 3d가 더 나은거 같긴한데 클러스터링이 제대로 된거 같지는 않다. 이거는 좀 더 고민해봐야겠다. 위도 경도에 가격이나 평당가격으로 클러스터링 해볼까?
피어세션
- 오늘의 화두는 공공임대아파트가 월등히 전세가격이 낮게 나오는데 이걸 어떻게 분류해야하는가 였다. 이부분은 내일 클러스터링으로 한번 처리해보려한다.
회고
- 일주일간 쉬다와서 열심히 달렸다. 일단은 생각보다 진척이 좀 막힌 상태라서 잘 헤쳐나가야 할 것 같다.

Full-Stack Dev / MLOps