Today I Learned
오늘은 ARIMA / SARIMAX를 적용해서 index를 만들고 그걸 이용해서 deposit을 추정해봤다.
ARIMA / SARIMAX 적용
- ARIMA 적용해서 Index 추정
from statsmodels.tsa.arima.model import ARIMA
month_df = pd.read_csv(os.path.join(processed_path, "month_avg_deposit.csv"))
month_df['contract_ymd'] = pd.to_datetime(month_df['contract_ymd'])
# NaN 값을 가진 행을 제외하고 ARIMA 모델을 훈련
train_df = month_df.dropna(subset=['avg_deposit'])
# ARIMA 모델을 사용하여 avg_deposit 예측
model = ARIMA(train_df['avg_deposit'], order=(6, 1, 1))
model_fit = model.fit()
# NaN 값을 가진 행의 인덱스를 찾기
nan_indices = month_df[month_df['avg_deposit'].isna()].index
# NaN 값을 가진 행의 avg_deposit 예측
predictions = model_fit.predict(start=len(train_df), end=len(train_df) + len(nan_indices) - 1, typ='levels')
# 예측된 값을 month_df에 채우기
month_df.loc[nan_indices, 'avg_deposit'] = predictions.values
# 결과 데이터프레임 생성
results_df = month_df.loc[nan_indices].copy()
results_df['ARIMA'] = predictions.values
# 시각화
fig, ax1 = plt.subplots(figsize=(14, 7))
# avg_deposit 그래프 (왼쪽 축)
ax1.plot(month_df['contract_ymd'], month_df['avg_deposit'], label='Historical Data', color='blue')
ax1.plot(results_df['contract_ymd'], results_df['ARIMA'], label='ARIMA Forecast', color='red')
ax1.set_xlabel('Date')
ax1.set_ylabel('Average Deposit', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
# interest_rate 그래프 (오른쪽 축)
ax2 = ax1.twinx()
ax2.plot(month_df['contract_ymd'], month_df['interest_rate'], label='Interest Rate', color='green')
ax2.set_ylabel('Interest Rate', color='green')
ax2.tick_params(axis='y', labelcolor='green')
# 제목 및 범례
plt.title('Deposit Price Forecast and Interest Rate')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc='upper left')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 결과 출력
print(results_df[['contract_ymd', 'ARIMA']])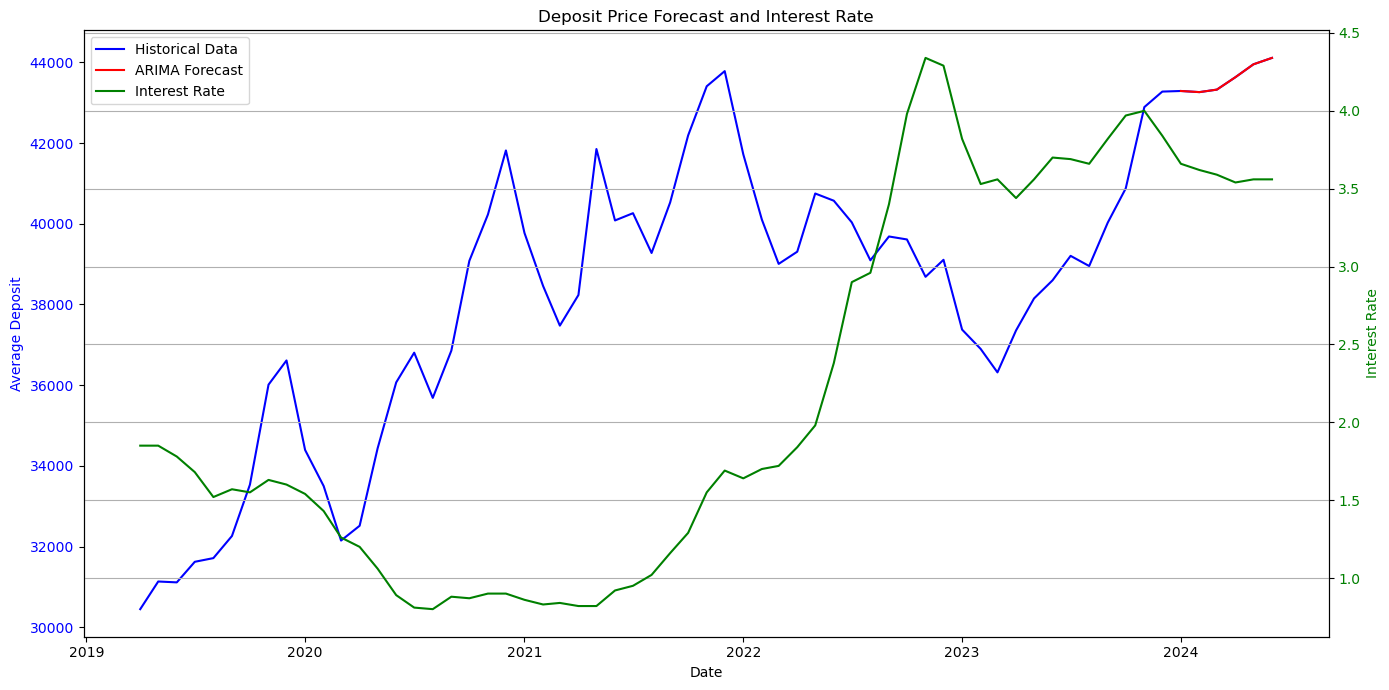
- SARIMAX 적용해서 index 추정
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_absolute_error
# 데이터 로드
month_df = pd.read_csv(os.path.join(processed_path, "month_avg_deposit.csv"))
month_df['contract_ymd'] = pd.to_datetime(month_df['contract_ymd'])
# 데이터 분할
train_df = month_df[month_df['contract_ymd'] < '2023-01-01']
validation_df = month_df[(month_df['contract_ymd'] >= '2023-01-01') & (month_df['contract_ymd'] < '2024-01-01')]
test_df = month_df[month_df['contract_ymd'] >= '2024-01-01']
# SARIMAX 모델 훈련
model = SARIMAX(train_df['avg_deposit'],
exog=train_df['interest_rate'],
order=(2, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=True,
enforce_invertibility=True)
model_fit = model.fit()
# Validation set 예측
validation_exog = validation_df['interest_rate']
validation_predictions = model_fit.forecast(steps=len(validation_df), exog=validation_exog)
# Test set 예측
test_exog = test_df['interest_rate']
test_predictions = model_fit.forecast(steps=len(test_df), exog=test_exog)
# Validation MAE 계산
validation_mae = mean_absolute_error(validation_df['avg_deposit'], validation_predictions)
print(f"Validation MAE: {validation_mae}")
# 결과 데이터프레임 생성
results_df = pd.concat([validation_df, test_df])
results_df['SARIMAX'] = np.concatenate([validation_predictions, test_predictions])
# 시각화
fig, ax1 = plt.subplots(figsize=(14, 7))
# avg_deposit 그래프 (왼쪽 축)
ax1.plot(month_df['contract_ymd'], month_df['avg_deposit'], label='Historical Data', color='blue')
ax1.plot(results_df['contract_ymd'], results_df['SARIMAX'], label='SARIMAX Forecast', color='red')
ax1.axvline(x=pd.to_datetime('2023-01-01'), color='gray', linestyle='--', label='Validation Start')
ax1.axvline(x=pd.to_datetime('2024-01-01'), color='black', linestyle='--', label='Test Start')
ax1.set_xlabel('Date')
ax1.set_ylabel('Average Deposit', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
# interest_rate 그래프 (오른쪽 축)
ax2 = ax1.twinx()
ax2.plot(month_df['contract_ymd'], month_df['interest_rate'], label='Interest Rate', color='green')
ax2.set_ylabel('Interest Rate', color='green')
ax2.tick_params(axis='y', labelcolor='green')
# 제목 및 범례
plt.title('Deposit Price Forecast and Interest Rate')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc='upper left')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 결과 출력
print(results_df[['contract_ymd', 'avg_deposit', 'SARIMAX']])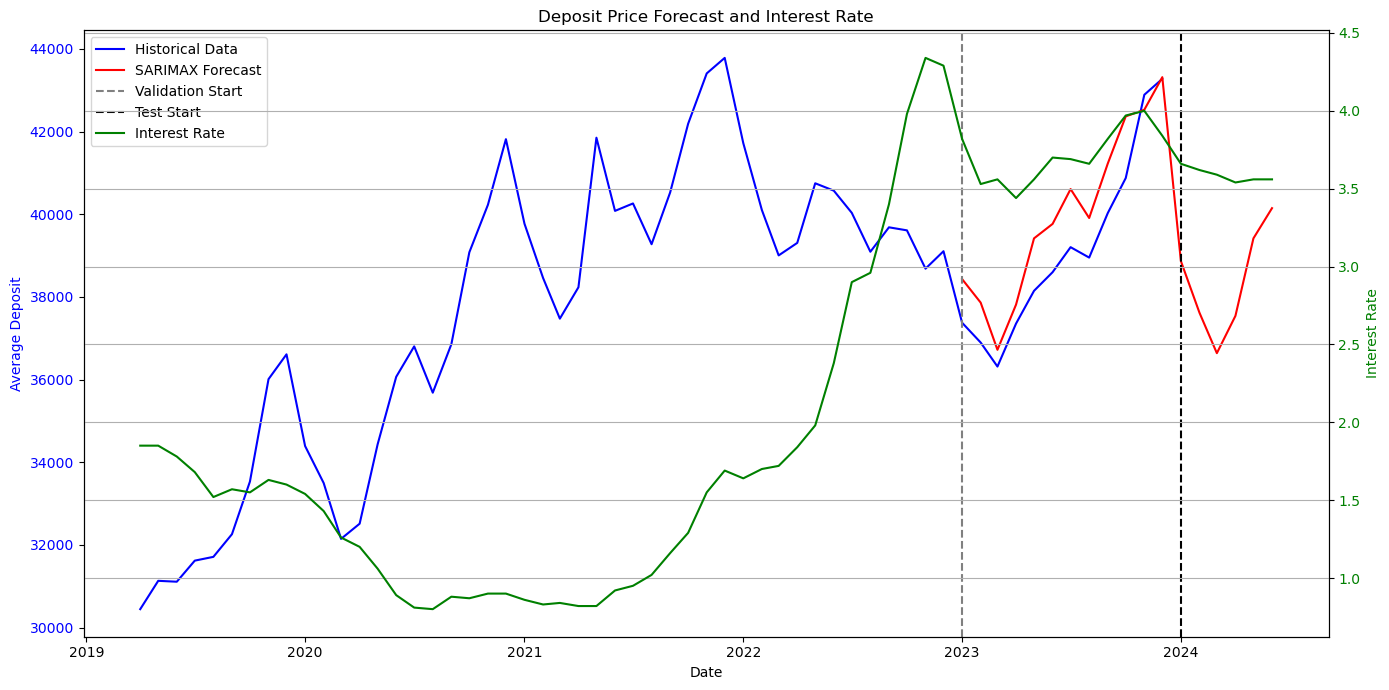
-
생성된 index

-
막상 적용해보니 public score는 이전 값보다 잘 안나오긴했다.
recent_deposit 추정을 처음부터 다시 파봐야될 것 같다.
피어세션
- 오늘 피어세션에서는 생성된 feature들 다 통합해서 모으고 그걸 xgboost로 돌려봤다.

Full-Stack Dev / MLOps