Today I Learned
오늘은 만들어진 feature들로 모델을 돌려봤다.
k-fold CV LightGBM
import lightgbm as lgb
import numpy as np
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
# 학습에 사용할 특징 열
feature_columns = [col for col in temp_train_df.columns if col not in ['deposit', '_type', 'index']]
# 학습 데이터 준비
X = temp_train_df[feature_columns]
y = temp_train_df['deposit']
# 결측치 대체
X['recent_deposit'] = X['recent_deposit'].fillna(39000)
# LightGBM 파라미터 설정
params = {
'objective': 'regression',
'metric': 'mae',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'seed': 42
}
# 콜백 함수 정의
def print_evaluation(period=10):
def callback(env):
if (env.iteration + 1) % period == 0:
train_mae = env.evaluation_result_list[0][2]
val_mae = env.evaluation_result_list[1][2]
print(f"[{env.iteration + 1}] Train MAE: {train_mae:.4f}, Val MAE: {val_mae:.4f}")
return callback
# 5-fold 교차 검증 설정
n_folds = 5
kf = KFold(n_splits=n_folds, shuffle=True, random_state=42)
# 각 폴드의 예측 결과를 저장할 리스트
oof_predictions = np.zeros(len(X))
test_predictions = np.zeros(len(test_df))
# 교차 검증 수행
for fold, (train_idx, val_idx) in enumerate(kf.split(X), 1):
print(f"\nFold {fold}")
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
dtrain = lgb.Dataset(X_train, label=y_train)
dval = lgb.Dataset(X_val, label=y_val, reference=dtrain)
model = lgb.train(
params,
dtrain,
num_boost_round=1000,
valid_sets=[dtrain, dval],
callbacks=[print_evaluation(period=100)]
)
# 검증 세트에 대한 예측
oof_predictions[val_idx] = model.predict(X_val)
# 테스트 세트에 대한 예측
test_predictions += model.predict(test_df[feature_columns]) / n_folds
# 전체 검증 세트에 대한 MAE 계산
oof_mae = mean_absolute_error(y, oof_predictions)
print(f"\nOverall OOF MAE: {oof_mae:.4f}")
# 테스트 세트에 대한 최종 예측 결과
y_pred = test_predictions
print("\nTraining completed.")- 사용한 컬럼은 아래와 같다
columns = ['apt_idx', 'index', 'area_m2', 'contract_type', 'floor', 'built_year', 'latitude', 'longitude', 'deposit', '_type', 'grid_id', 'interest_rate', 'diff_interest_rate', 'apt_deposit_rank', 'apt_area_deposit_rank', 'recent_deposit', 'nearest_subway_distance', 'num_subway_within_1km', 'category_interchange_within_1km', 'num_subway_within_500m', 'category_interchange_within_500m']
-
feature importance
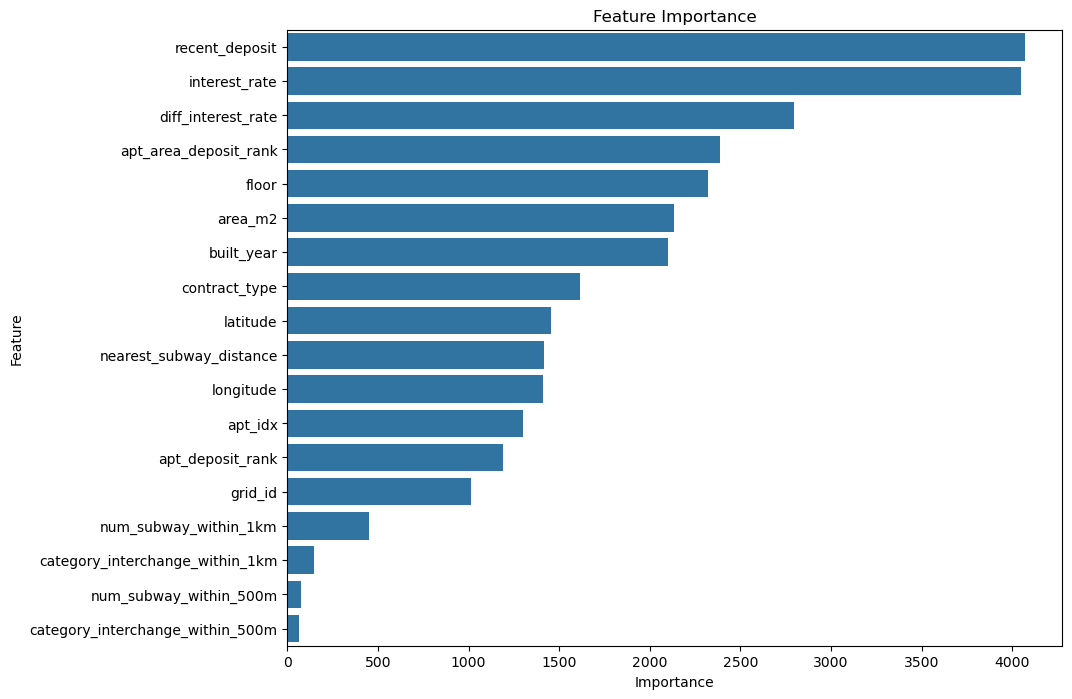
-
결과는 [1000] Train MAE: 3881.4096, Val MAE: 3923.5255
public score는 제출후 파악

Full-Stack Dev / MLOps