Today I Learned
오늘 실험했던 기록을 남겨두려한다.
-
LightGBM 모델에서 더이상 MAE가 내려가지 않아서 여러 방법을 시도하던 중, 에러난 파일에서 결과가 좋아지는 이상한 현상을 발견했다.
-
에러난 파일은 V2버전에서 interest_rate와 diff_interest_rate가 문제가 있는 파일이었고, 이를 제대로 고친버전에서 오히려 MAE가 훨씬 높게 찍혔다.
-
feature importance 상에서는 두 지표가 높게 잡혀있었기 때문에 두 지표가 학습을 잘 시키지 못하는 지표라고 생각해 쳐낸 후 아래의 상태로 다시 실험했다.
LightGBM (EDA/김건율/LightGBM/MODEL_LightGBM_2.ipynb)
data set: v4- test public score : 4018.9173
- Overall OOF MAE: 3908.5850
change: + 'arima_deposit_index' columns + (contract_year_month)columns: v4에서 ['area_m2_price', 'area_price', 'year_month', 'contract_ymd', 'original_index', 'interest_rate', 'diff_interest_rate'] 제거
params = {
'objective': 'regression',
'metric': 'mae',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'seed': 42
}
model = lgb.train(
params,
dtrain,
num_boost_round=1000,
valid_sets=[dtrain, dval],
callbacks=[print_evaluation(period=100)]
)
k=5- feature importance
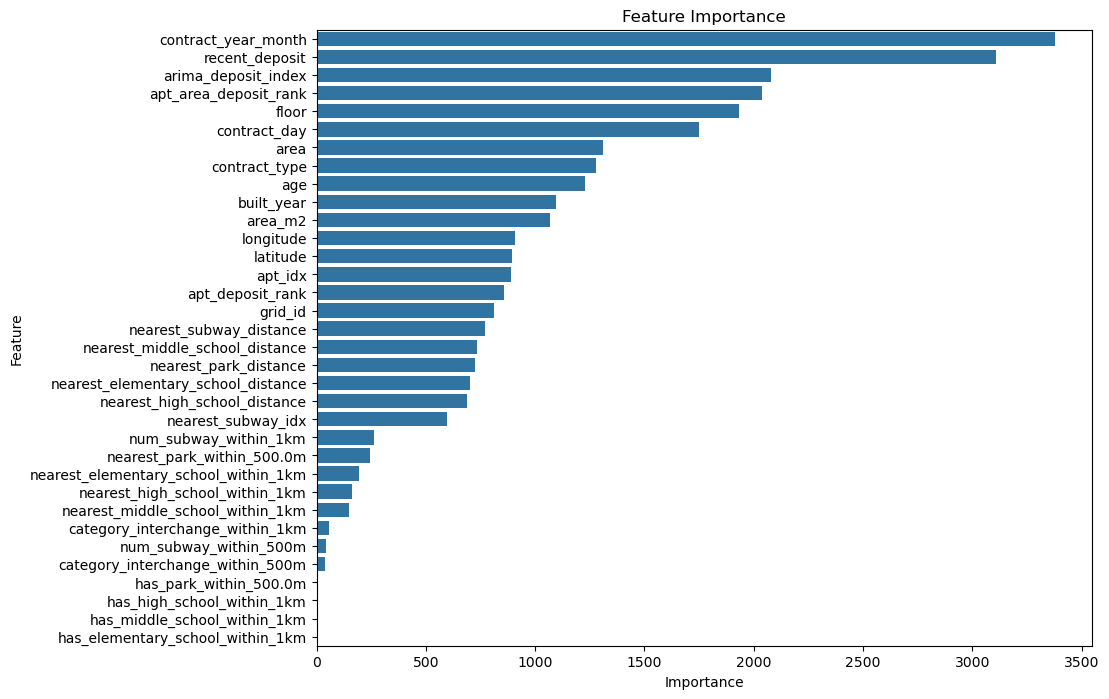
-
Public score 4836.6036 -> 4018.9173로 개선 성공.
-
모든 피쳐를 넣는다고 좋은게 아니다. 걸러야할 피처가 더 있을 수 있으니 계속 실험해봐야겠다.

Full-Stack Dev / MLOps