Today I Learned
3번째 프로젝트 시작과 함께 추천시스템에 대해 제대로 학습을 시작했다. 오늘 진행했던 오피스아워 내용은 추후 정리해서 포스팅할 예정!
추천 시스템
사용자의 선호도와 행동패턴을 분석하여 개인화된 아이템이나 콘텐츠를 제안하는 시스템
-
PULL 방식 : 유저가 직접 아이템을 검색하면 시스템이 아이템을 보여준다. 검색엔 사용자의 의도가 반영되어 있다.
-
PUSH 방식 : 사용자의 의도나 키워드를 직접 제안하지 않아도 시스템이 직접 아이템을 제시하는 방법. 추천시스템이 여기에 속한다.
-
Long Tail 현상 : 소수의 인기 상품(head)과 다수의 비인기 상품(tail)이 공존.
추천시스템이 비인기 상품(롱테일)을 사용자에게 노출시켜 다양성과 틈새시장 활성화.
정보의 과포화 상태인 현재, 추천시스템이 더욱 중요해지고 있다.
사용 데이터
1. 유저 데이터
-
유저 프로파일링
유저의 특성, 행동패턴, 선호도 등을 체계적으로 수집하고 분석하여 프로필을 구축하는 과정 -
식별자(identifier) : 유저 id나 브라우저 쿠키, 디바이스 id같은 걸로 유저를 식별한다.
-
명시적 데이터(Explicit Data)
사용자가 직접 공개하는 데이터. 데모그래픽(나이, 성별, 지역, 직업 등)정보나 관심사 설정, 평점, 리뷰, 설문조사 응답 등이 여기에 속한다. 확보하기 어려운 데이터. -
암시적 데이터(Implicit Data)
사용자의 행동을 통해 수집되는 데이터. 검색기록, 클릭로그, 체류시간, 구매이력, 컨텐츠 소비 패턴. 확보하기 쉬우나 다루기 어렵다.
2. 아이템 데이터
-
아이템 프로파일링
상품, 콘텐츠, 서비스 등의 특성과 속성을 체계적으로 분석하고 정리하는 과정 -
도메인에 따라 영상, 음악, 상품, 기사, 그림 등 아이템이 달라진다.
-
아이템 ID로 식별한다.
-
아이템의 고유정보를 메타데이터화해서 사용한다. 도메인별로 정보가 다 달라진다.
3. 유저-아이템 상호작용 데이터
-
유저가 아이템과 상호작용할 때 남는 로그
-
명시적 피드백(Explicit Feedback)
유저가 직접 아이템을 평가한 것. 리뷰, 평점, 좋아요, 위시리스트, 즐겨찾기 등. -
암시적 피드백(Implicit Feedback)
간접적인 평가. 클릭, 조회, 체류시간, 구매이력, 장바구니 추가 등
명시적 피드백보다 훨씬 양이 많다.
RecSys 문제 정의
- RecSys의 목적은 특정 유저에게 적합한 아이템을 추천하기 위해선 유저-아이템 상호작용을 평가할 score가 필요하다. 이 score를 구하기 위해 모델링 하는 것이 목적.
Ranking 문제
- 유저에게 적합한 아이템 Top K개를 추천하는데 아이템간 상대적 순위에 중점을둬서 정확한 수치는 크게 중요하지 않다. 주로 암시적 피드백을 활용한다.
Prediction 문제
- 사용자가 특정 아이템에 부여할 선호도/평점/구매확률/클릭확률 예측
- 주로 명시적 피드백을 활용하고 실제값과 예측값 차이 최소화가 목표다.
- 유저-아이템 행렬을 채우는 문제라고 할 수 있다.
- 정확한 수치 예측에 중점을 둬서 회귀문제로 접근해 RMSE, MAE, AUC 같은 지표를 사용한다.
RecSys 성능 평가 지표
-
비즈니스 측면에서는 매출이나 PV(page view, 방문자수), CTR(Click-Through Rate, 클릭 확률)이 더 늘어났는 지 체크.
-
품질관점에서는 연관성(유저와 아이템 관련성), 다양성, 새로움(novelty, 추천되는 아이템이 중복되지않고 갱신), 참신함(serendipity, 유저의 기대에 없던 뜻밖의 추천)이 있다.
Ranking 사용 지표
-
기본 설명
Precision = (True Positives) / (True Positives + False Positives)
Recall = (True Positives) / (True Positives + False Negatives)
precision은 FP를 줄여야하니 오진을 줄여야하고,
recall은 FN을 줄여야하니 target을 못맞추고 넘어가는걸 줄여야한다. -
Precision@K= 유저가 관심있는 아이템 수 / K
상위 K개 추천 결과 중 관련 있는 아이템의 비율. 추천의 정확성 측정. -
Recall@K= 추천된 유저 관련 아이템 수 / 유저가 관심있는 전체 관련 아이템 수
유저가 관심있는 전체 관련 아이템 중 상위 K개 추천에 포함된 비율
관련 아이템 포함 정도 측정. 망라성을 평가한다. K값이 커질수록 커진다. -
AP@K
Precision@1~Precision@K까지의 평균값. 관련 아이템을 더 높은 순위에 추천할 수록 점수 상승
유저 한명당 하나씩 나옴. -
MAP@K
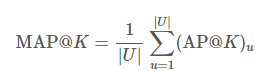
위의 AP@K를 전체 유저 m명의 평균을 낸 값.
nDCG@K
이상적인 순위와 실제 순위 비교. 상위 순서에 더 큰 가중치 부여. 0~1 사이의 정규화된 값.
MAP와 다르게 연관성을 이진값이 아니라 수치로도 사용할 수 있다.
DCG(순위에따라 관련도 합을 discount)를 IDCG(이상적인 상황에서 DCG)로 나눈 값.
Offline Test
-
기존에 수집된 데이터를 train/valid/test로 나눠서 평가.
-
실제 서비스 배포전 검증용으로 쓰이고 빠른 실험과 반복이 가능하고 비용 효율적이다.
-
하지만 과거의 데이터이고 실제 사용자 반응 예측은 한계가 있다. 새로운 상황 대응이 어렵다.
온라인 테스트에 선행되어 시행된다. -
ranking에선 Precision@K, Recall@K, MAP@K, nDCG@K, Hit Ratio 같은 지표를 쓰고, prediction에선 MAE, RMSE, AUC 같은 지표를 쓴다.
Online A/B 테스트
-
Offline Test에서 도출된 결과를 실제 시스템에 도입해 검증하는 단계
-
동일한 시간대에서 유저를 랜덤하게 나눠(추천시스템 제외 다른 환경 최대한 동일하게) 대조군과 실험군 성능을 평가하고 이를 통한 결과로 최종 사용 여부를 가린다.
-
매출, CTR같은 비즈니스 지표로 평가한다.
인기도 기반 추천
전체 사용자들에게 가장 인기 있는 아이템을 추천하는 방식으로 비개인화 추천의 대표적인 방식
-
가장 간단하면서 대중의 선호도를 반영하고 안정적이며 cold start 문제가 없어 서비스 초기 추천 모델이나 기본 추천으로 많이 사용한다.
-
개인화 부재, 롱테일 문제, 느린 트렌드 반영 및 계절성 반영 어려움 등의 단점이 있다.
Most Popular
조회수를 토대로 가장 인기있는 아이템을 추천.
-
인기도와 최신성(시간)을 다 고려해야된다. 뉴스의 경우 조회수가 많다고 예전껄 추천해줄수는 없다.
-
시간을 빼거나, 시간으로 나누거나, 최신일수록 가중치를 준다거나 하는 방식으로 시간을 고려해준다.
Highly Rated
평점으로 score를 만들어 가장 높은 평점의 아이템을 추천하는 방식
-
평점과 평가 횟수 둘 다 고려해야한다. 평가횟수가 적으면 신뢰할 수 없다.
-
rating은 평균을 쓰되, 평가 횟수가 적으면 discount하는 방식을 써서 평가 횟수가 많아지면 score가 원래 값과 비슷하게 나오는 스팀의 평가 방식이 있다.
