Today I Learned
오늘 배운 내용은 context를 활용한 추천시스템!
Context-aware Recommendation
유저와 아이템 간의 상호작용 뿐만 아니라 상황적 맥락을 고려하는 추천 시스템
-
Context?
시간, 공간, 사회적맥락, 환경적 맥락 등 유저의 현재 상태나 환경같이 추천에 영향을 끼칠 수 있는 부가적 정보 -
주로 광고 쪽의 CTR(유저가 아이템을 클릭할 확률) 문제를 예측할 때 많이 사용한다.
CTR문제는 클릭 하냐 아니냐의 이진 분류문제로 시그모이드 함수를 적용하면 0,1사이의 예측 CTR이된다. -
주로 이진분류에 사용하는 회귀분석 방법인 로지스틱 회귀에서 각 데이터의 상호작용까지 고려한 다항식 모델(Polynomial Model)을 사용하다가 파라미터 수가 급격히 증가하는 단점을 해결하기 위해 FM, FFM과 같은 모델이 나왔다.
-
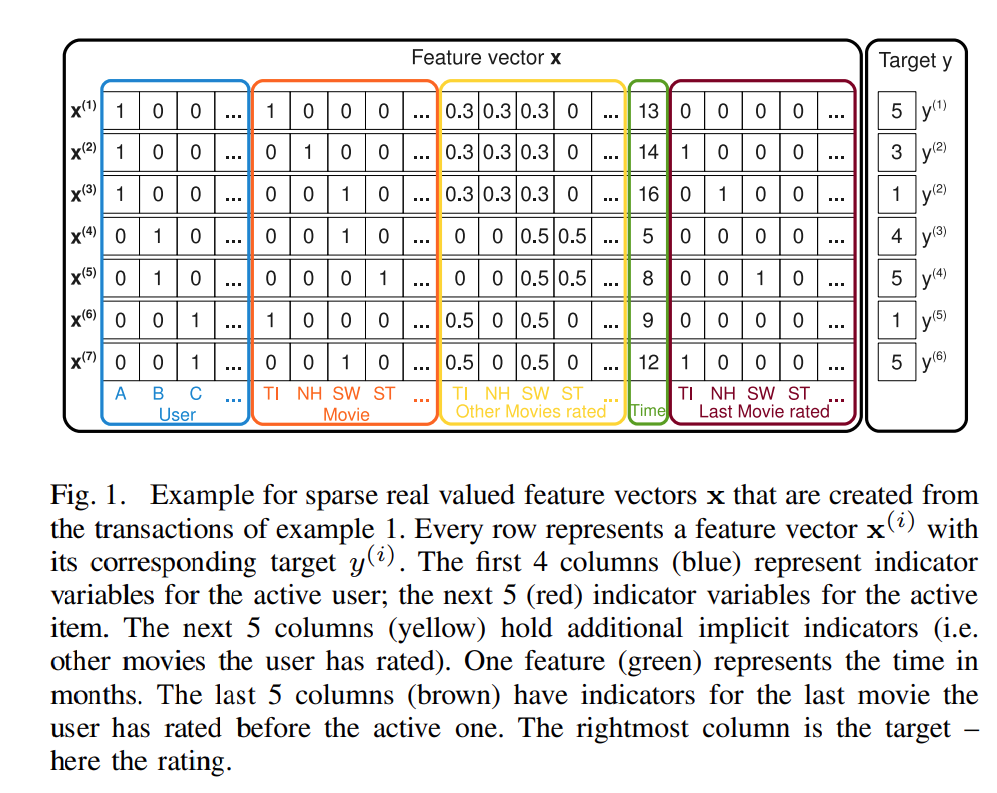
dense feature : 벡터로 표현 시 작은 공간에 밀집된 수치형 변수
sparse feauture : 벡터로 표현 시 넓은 공간에 분포하는 범주형 변수 -
피처 임베딩
CTR 문제의 데이터는 대부분 sparse feature이다. 이걸 다 one-hot 인코딩하면 파라미터 수가 너무 많아져 언더/오버피팅 문제가 발생한다. 그래서고차원의 범주형 데이터를 저차원의 연속적인 벡터로 변환하는 기법을 피처 임베딩이라 한다.
FM(Factorization Machine)
 이미지 출처 : 논문
이미지 출처 : 논문
-
비선형 데이터셋에 높은 성능을 보이는 SVM과 CF 환경에서 좋은 성능을 내나 특별한 환경(or 데이터)에만 적용할 수 있는 MF를 결합한 모델
희소한(sparse) 데이터에서 특징들 간의 상호작용을 학습한다.
각 특징을 저차원 벡터로 표현하여 상호작용을 계산한다. -
기본공식. 로지스틱회귀에 두 피처의 상호작용을 추가한 식
-
각 피처가 독립적으로 미치는 영향을 1차 상호작용으로 계산한 후, 피처들 간 상호작용을 2차로 학습한다. 이때 각 피처를 잠재벡터로 표현해 내적으로 상호작용의 강도를 계산한다.
-
선형 복잡도를 가지므로 대량의 학습 데이터에 대해서도 빠르게 학습한다.
FFM
Field-aware Factorization Machines for CTR Prediction
-
FM을 확장한 모델이다. input을 필드로 나눠서 각 피쳐는 다른 필드마다 다른 잠재 벡터를 가진다. 필드는 모델 설계시 직접 도메인 지식을 활용해 구현해야 한다.(성별, 나이대, 직업 등)
-
기본 공식
: i번째 특징이 j의 필드 와 상호작용할 때 사용하는 잠재 벡터 -
CTR 예측 예시
광고 클릭 예측
필드1(사용자): 성별, 나이
필드2(광고): 카테고리, 위치
필드3(컨텍스트): 시간, 기기 -
CTR에서 우수한 성능을 보이고, 실제 산업에서도 많이 사용한다. 정교한 관계를 포착해 정확도가 높고 도메인 지식을 활용해 해석 가능성도 높다. 하지만 FM보다 파라미터가 많고 학습시간도 길어 계산복잡도를 고려해야한다.
-
오히려 필드를 사용하지 않은 FM이 FFM보다 성능이 좋을 때도 있다. 도메인, 서비스마다 다르다.
RecSys with GBM
Gradient Boosting Machine을 이용한 CTR 예측
-
Boosting
앙상블의 일종으로 여러 weak learner를 연속적으로 결합해 이전의 약점을 보완하는 방식의 학습방법. 잔차(residual, 실제와 예측의 차이)를 줄이는 방향으로 훈련된다. -
AdaBoost, GBM, XGBoost, LightGBM, CatBoost 등..
-
추천 도메인에도 FM, FFM이나 휴리스틱 방식 보다 GBM이 성능이 잘 나오는 경우가 있다.
